
Elastic
10.4K posts

Elastic
@elastic
Where developers learn, build, and share. Your source for hands-on demos, cheat sheets, explainers and more.
Global Katılım Ekim 2009
183 Takip Edilen65.6K Takipçiler
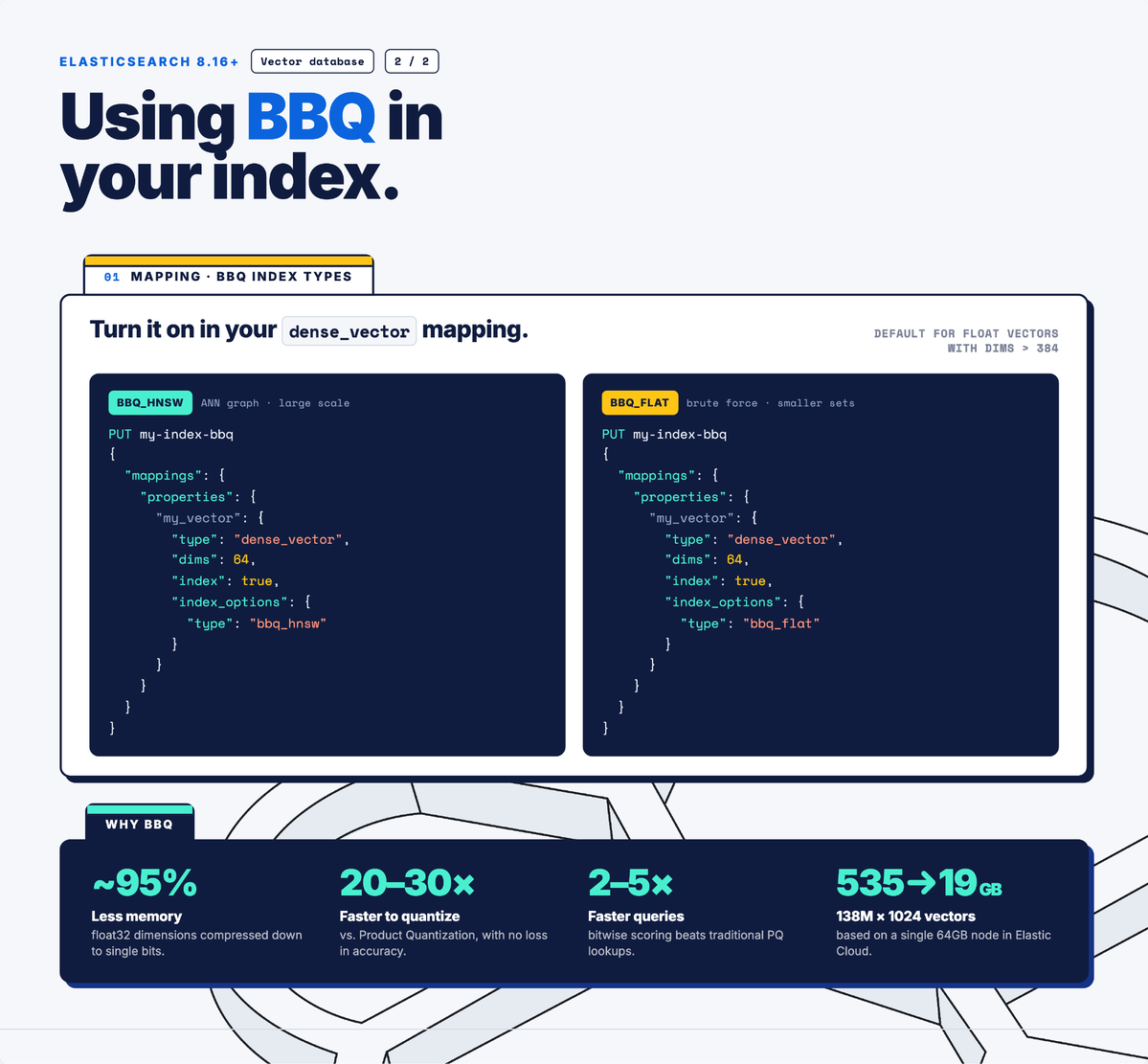
Binary quantization sounds like it should tank recall.
BBQ in Elasticsearch doesn't due to its asymmetric nature.
Vectors compress to single-bit values. Queries stay at int4 precision, so distance calculations keep the detail that matters. You trade a bit of oversampling and reranking for an approximately 95% storage reduction.
Trade-off: queries cost slightly more to compute per comparison. Storage costs don't move at all.

English
Elastic retweetledi

7 trojanized repos targeting developers. Zero detections across every AV vendor.
Elastic Security Labs is tracking a new Contagious Interview campaign (REF9403) where DPRK-aligned actors distribute fake coding challenges through Slack job postings.
The repos masquerade as real Next.js e-commerce projects. The code was copied from a legitimate template called GoCart. The difference is steganography.
Base64 payload fragments are hidden inside HTML comments in SVG flag images. A script reassembles them alphabetically, decodes with a custom function, and runs on server start.
What deploys:
- Credential stealer targeting 25 crypto wallet extensions plus browser login data
- File stealer scanning for .env, .pem, .ssh, .aws, documents, images, shell history, and source code
- Socket. IO RAT providing real-time interactive shell access
- Clipboard stealer polling every 500ms, plus a Windows dropper downloading 3 disguised executables from the C2
Full analysis from Elastic Security Labs by @danielstepanic : go.es.io/4fqEhgp

English
Elastic retweetledi

I just wrote and recorded a video about how to perform vector search --- on 🎞️ video clips, by how they *look*!
It means you can find scenes by what's *on the screen*, without expensive tagging. (Because, actually, a lot of video search is actually metadata-driven text search!)

English
Storing full 1024-dim vectors for every modality wastes storage.
Matryoshka representation learning ranks signal into the first dimensions, so truncating a vector doesn't mean losing everything.
jina-embeddings-v5-omni inherits this from v5-text. Truncate to 32, 64, 128, up to 1024 dims, same embedding, no retraining or re-embedding required.
Text, image and audio hold up well even at the smallest sizes. Video is the one modality that wants the higher end of the range.

English
New modular malware family, tracked from first appearance.
Our Security Labs team breaks down the full infection chain, evasion techniques, and C2 infrastructure.
Elastic Security Labs@elasticseclabs
TELEPUZ is a new modular malware spreading via CLICKFIX-VIDAR chains. Elastic Security Labs is tracking it. Active since late April 2026. The delivery path: ClickFix social engineering tricks users into running a PowerShell command that downloads a VIDAR Go variant, which then fetches a lightweight stager and the main TELEPUZ payload. The core DLL communicates over WebSockets and pulls additional modules from C2 on demand: Keylogger Stealer Web injector: intercepts browser sessions via CDP and WebDriver BiDi, with default configs targeting financial form fields like IBANs 36 commands. Indirect syscalls. AMSI and ETW patching. NTDLL unhooking. Multiple UAC bypasses. Still in active development: the shellcode injection command returns a TODO placeholder. C2 infrastructure is small (2 domains), but fallback methods include Telegram channels, Steam profiles, DNS records, and a Polygon smart contract that doubles as a kill switch. New builds hit VirusTotal daily. The C2 footprint is small, but this thing is moving fast for something that started 2 months ago. Full technical analysis: go.es.io/4wg6i1p
English
@_jphwang Where to watch:
X: Right here on our X channel!
YouTube: go.es.io/44wyYqJ
English
15-minute live demos, Q+A. Every week.
Starting tomorrow.
Relevance Please is a new weekly livestream: demos across Search, Observability, and Security with rotating hosts and rotating topics.
First up: @_jphwang on Making Video Search Easy.
Join us tomorrow, 11AM ET / 8AM PT / 4PM BST. Links in the reply below.
English
Let's put it all together. What happens when I search for "the best wood fired neapolitin pie"?
- “the best wood fired neapolitan pie” (original query)
- “(t̶h̶e̶) best wood fired neapolitan pie” (stop word removal)
- “(t̶h̶e̶) best wood fire(d̶) neapolitan pie” (stemming)
- “(t̶h̶e̶) best wood fire(d̶) neapolitan (p̶i̶e̶)pizza” (synonym expansion)
English
5. An inverted index is the main data structure for search, working like a hash map.
It creates a 1-to-many mapping between a term, and the documents where that term appears.
This is why text analysis is performed on your documents at index time AND on your search query at query time to ensure a match on analyzed terms.
When the analyzed query terms [wood, fire, pizza] are sent to the inverted index, the index returns a list of document IDs (the postings list) for each individual term. These lists are then combined to retrieve the documents that match the query.
English

We went back to the full Elasticsearch vs Qdrant benchmark exchange. Traced every number to a cause.
Same hardware. 21M vectors. The disk sat at 0 IOPS the entire run.
io_uring and prefetch got the headline. Neither moved the number. You can't be bottlenecked on a device you never read from.
Matched on setup, both engines land around 56 QPS at 0.96 recall. The setup choices explained the multipliers, not the engines.
Here's what we found: go.es.io/3SY0dbb

English
Search feels simple until you start getting back irrelevant results.
Know which of these 3 retrieval strategies to reach for a furniture store site:
- BM25 matches exact terms. Finds an ottoman from "Product ID 43926".
- Vector matches meaning. Figures out what "padded stool for my feet" actually refers to.
- Hybrid runs both. Exact SKUs and vague descriptions in the same query.
BM25 for known items. Vector for descriptions. Hybrid when you can't predict which. There is no one-size-fits-all solution.

English