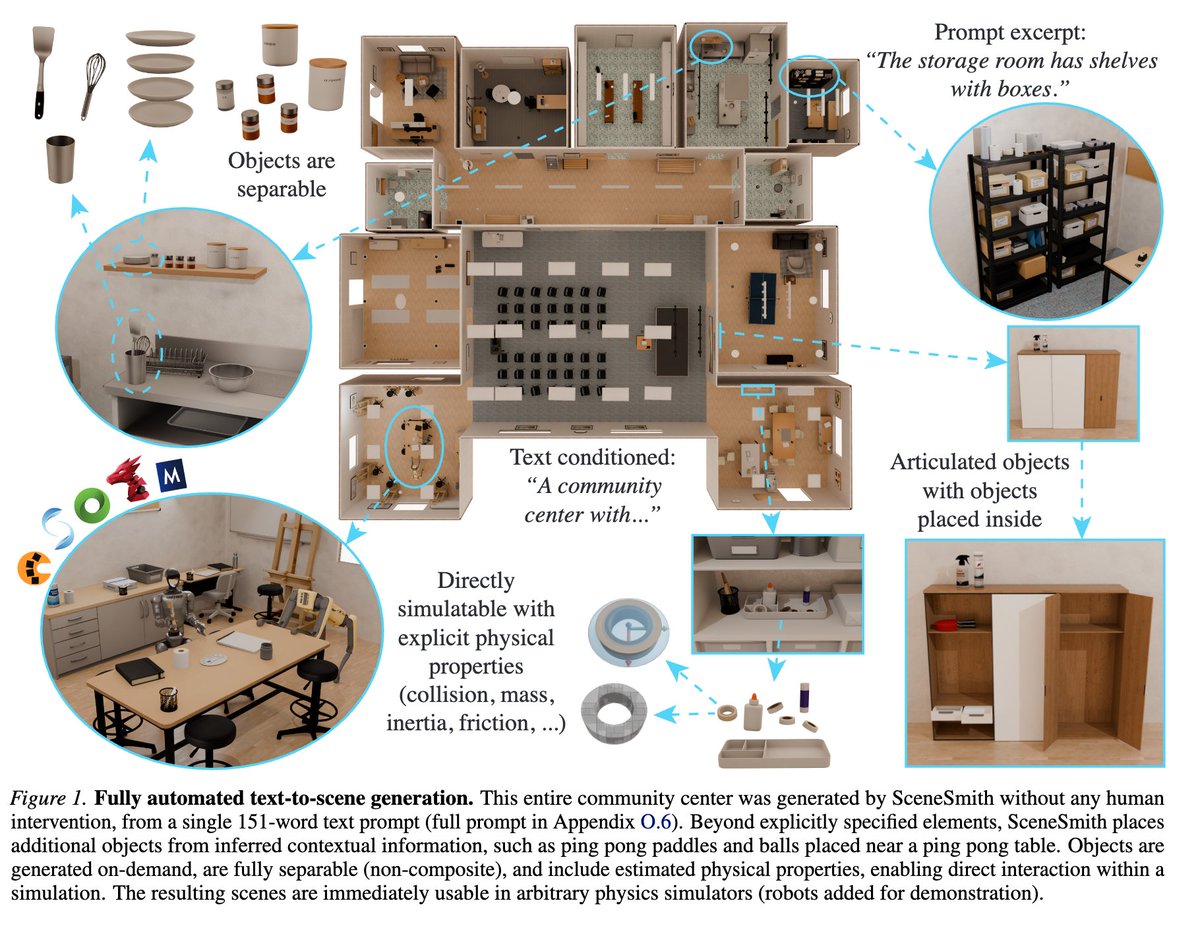
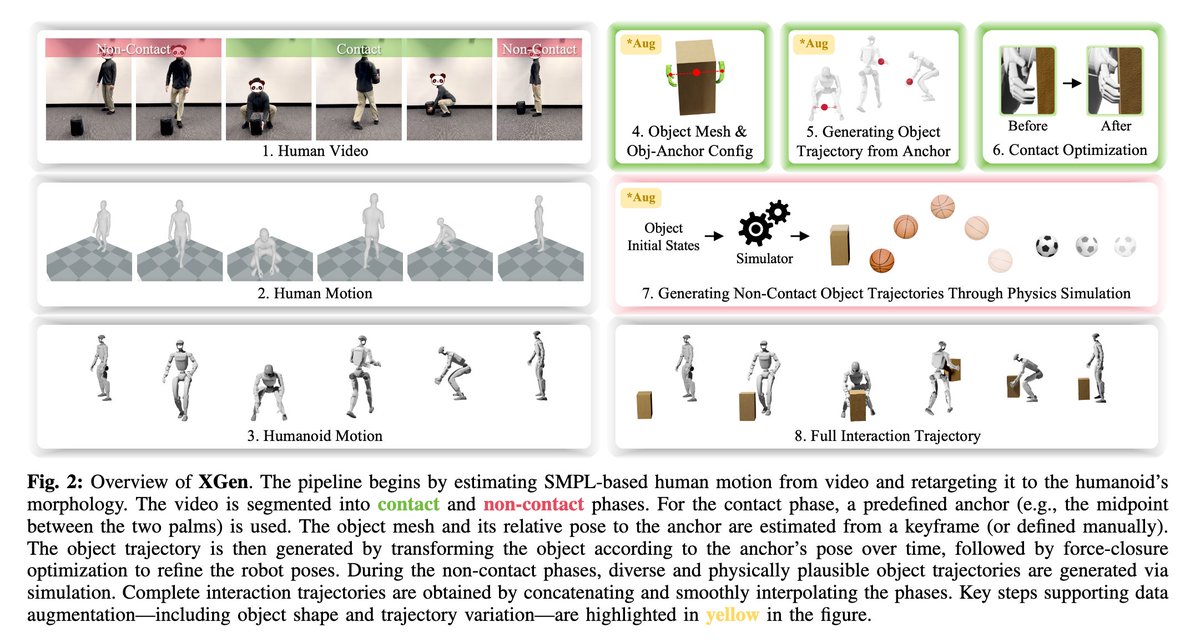
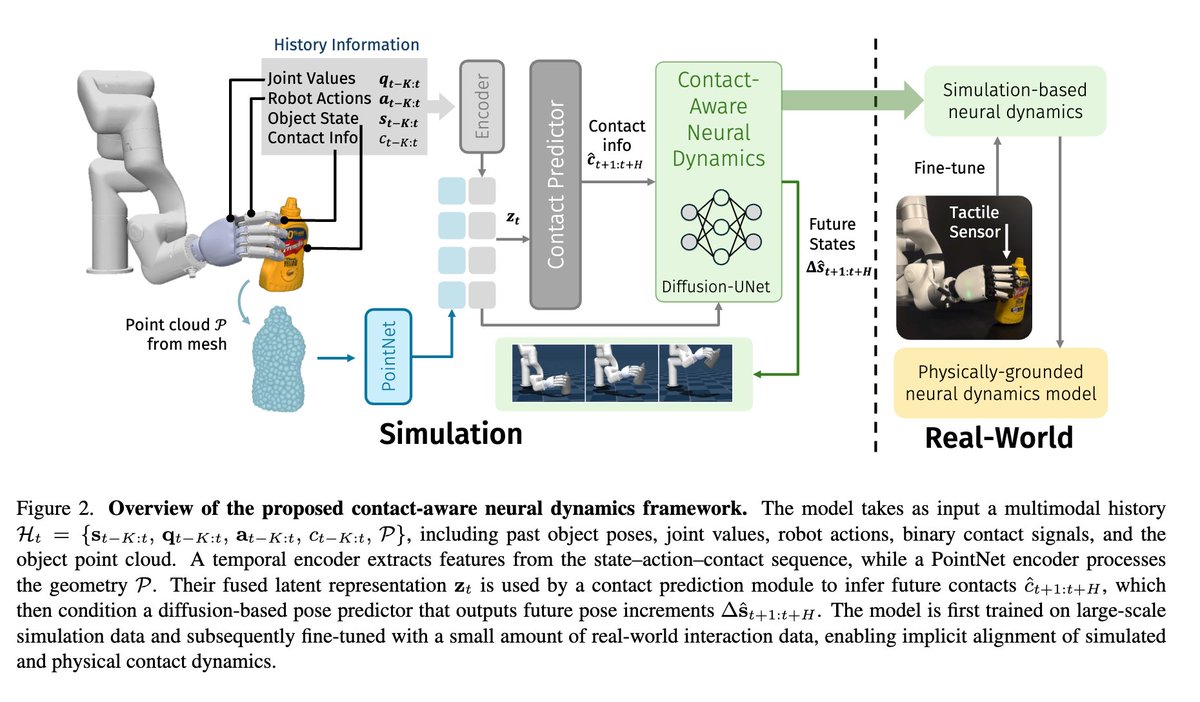
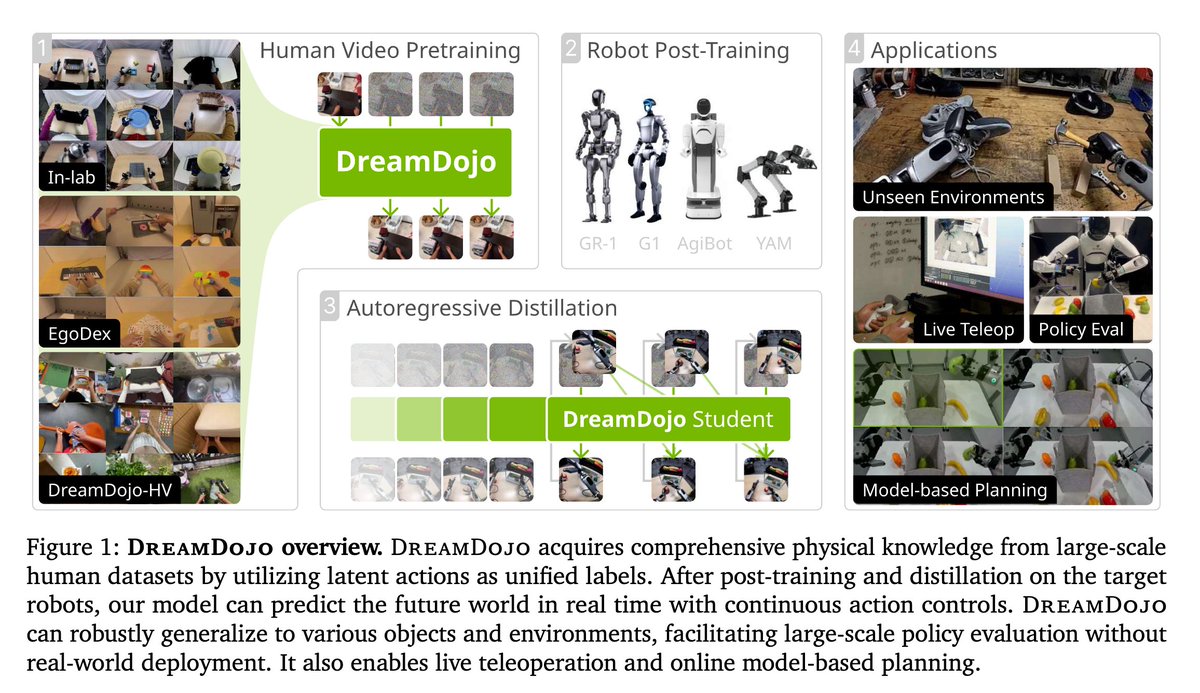
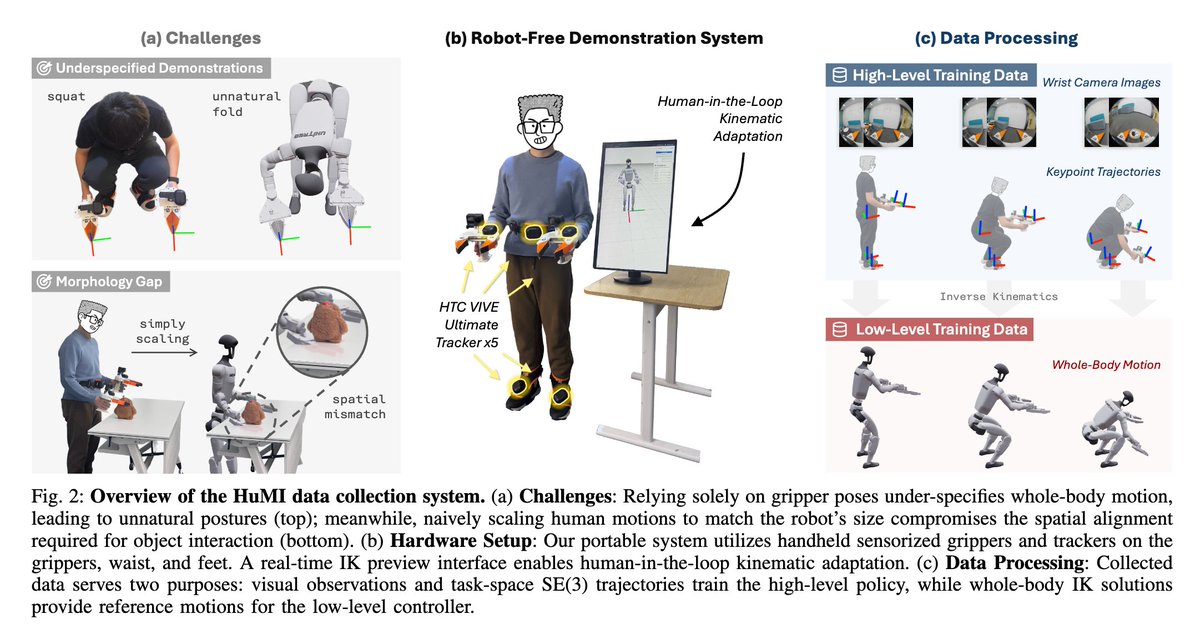
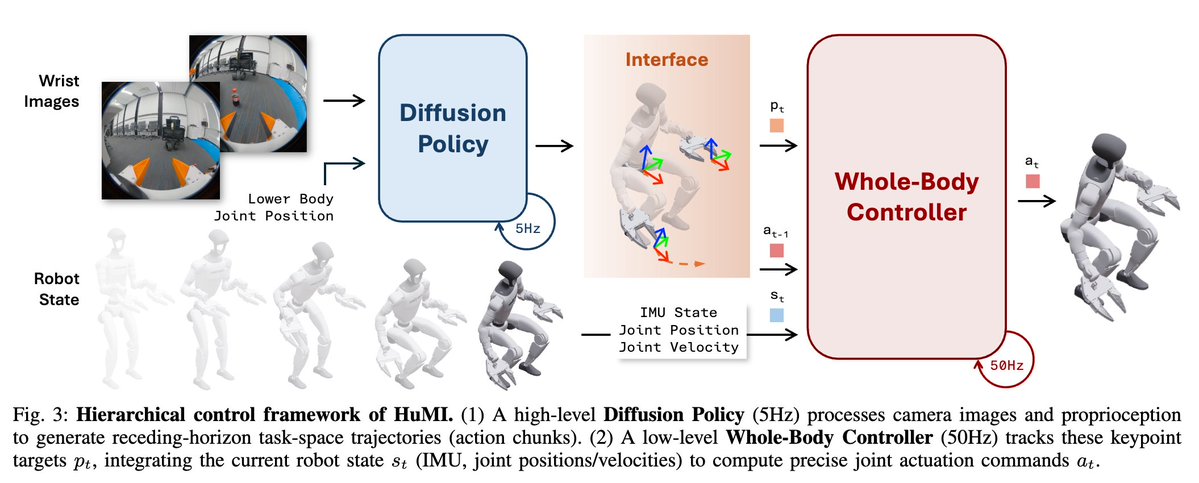
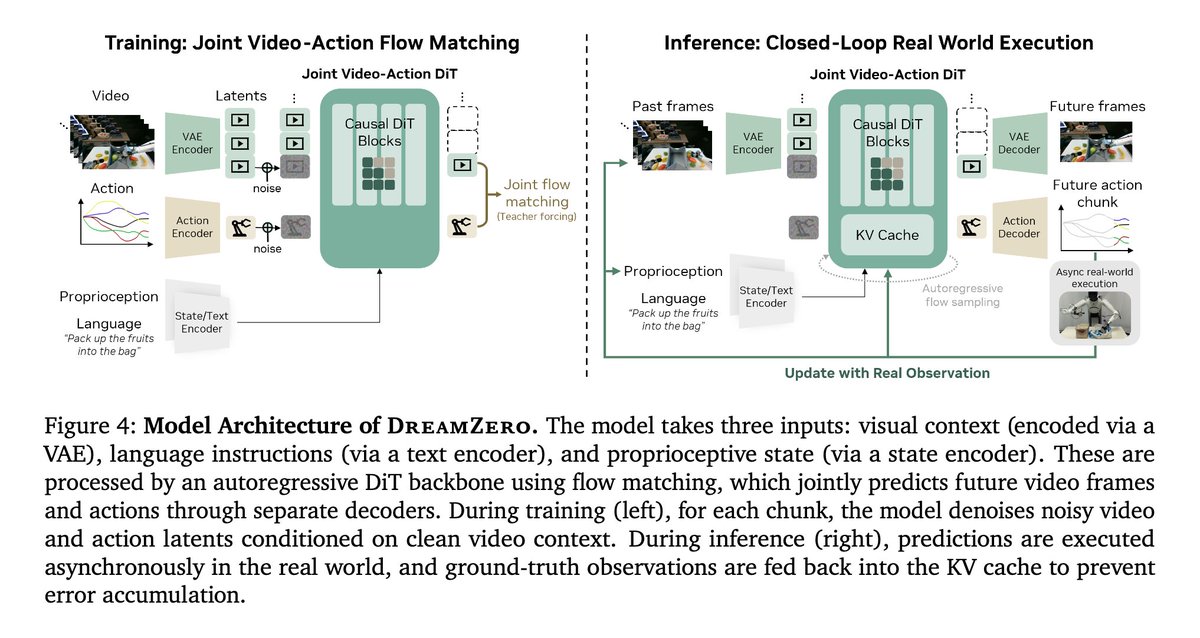
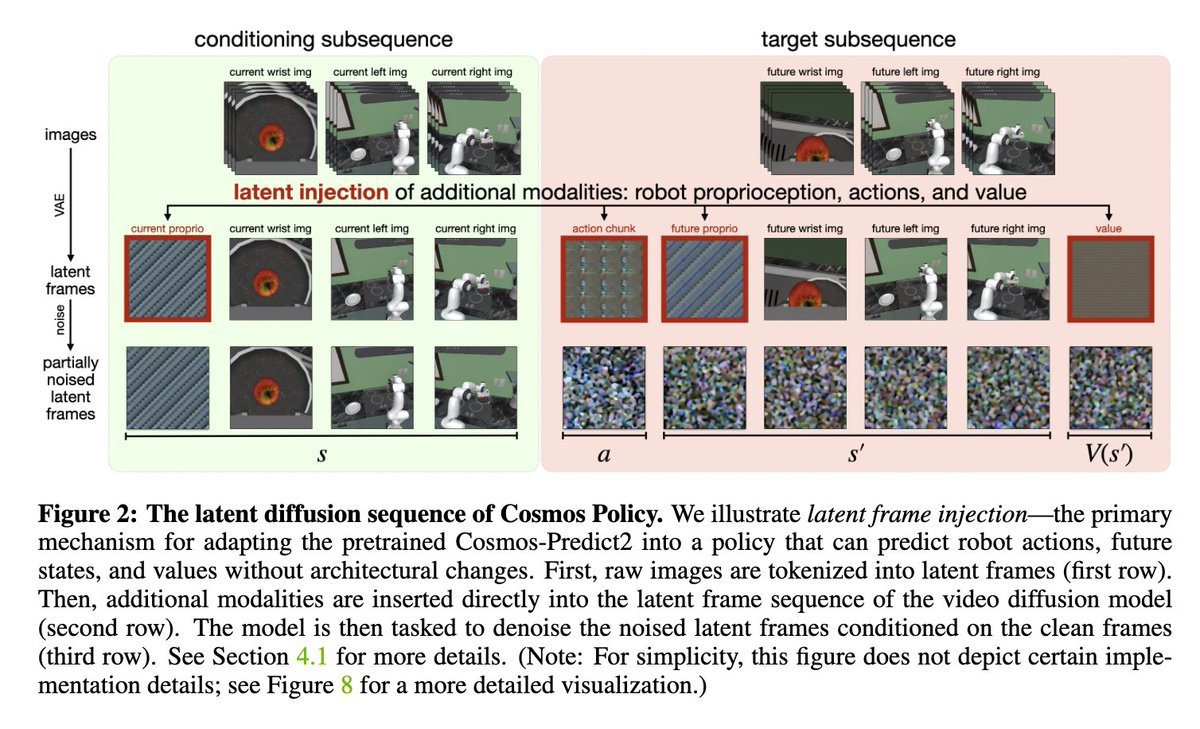
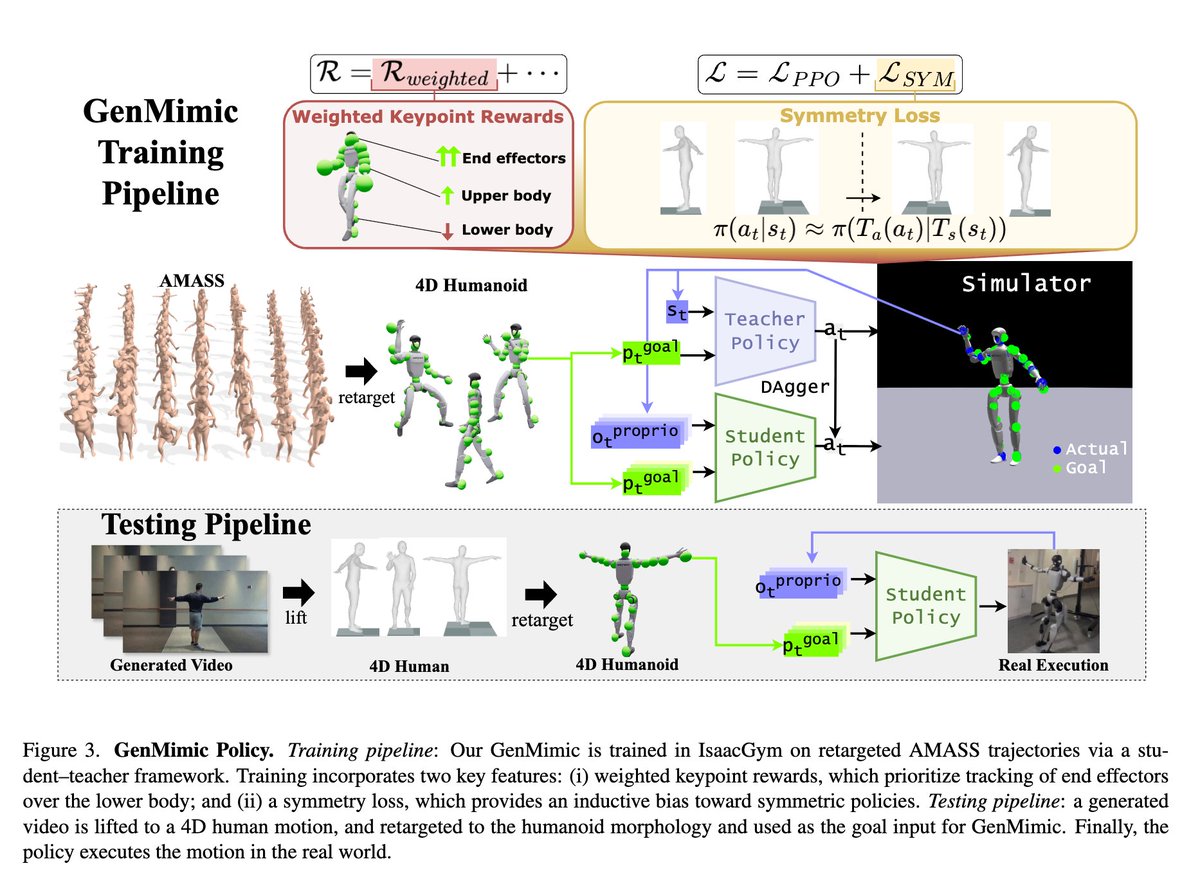
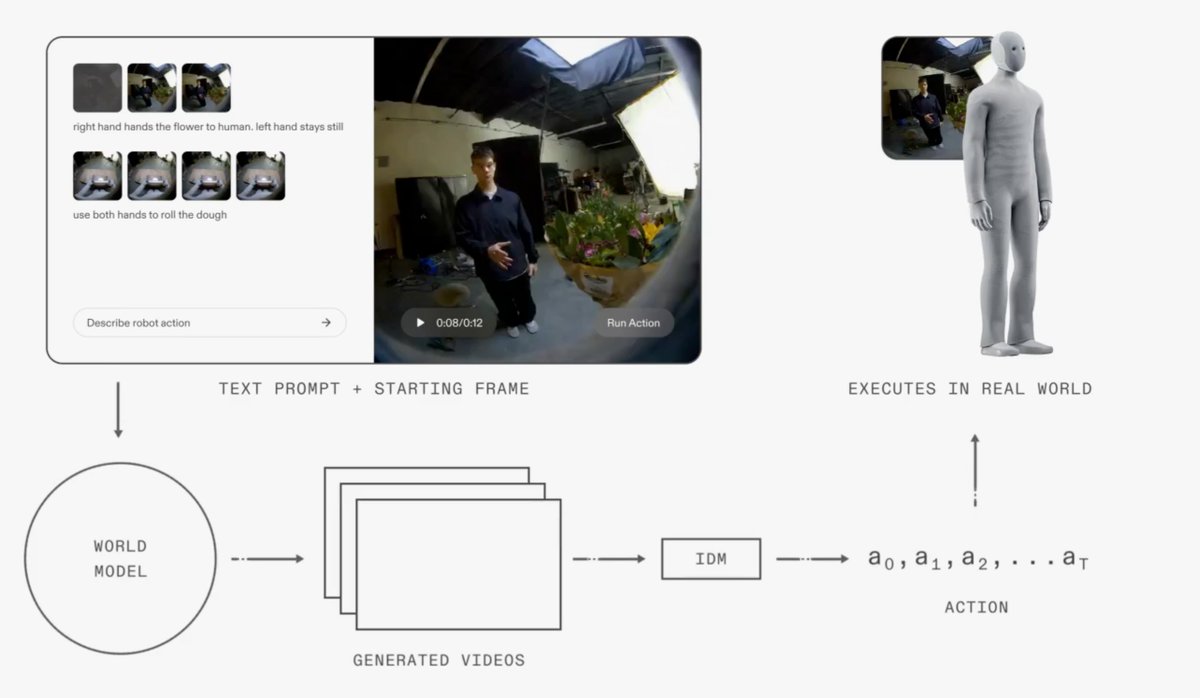
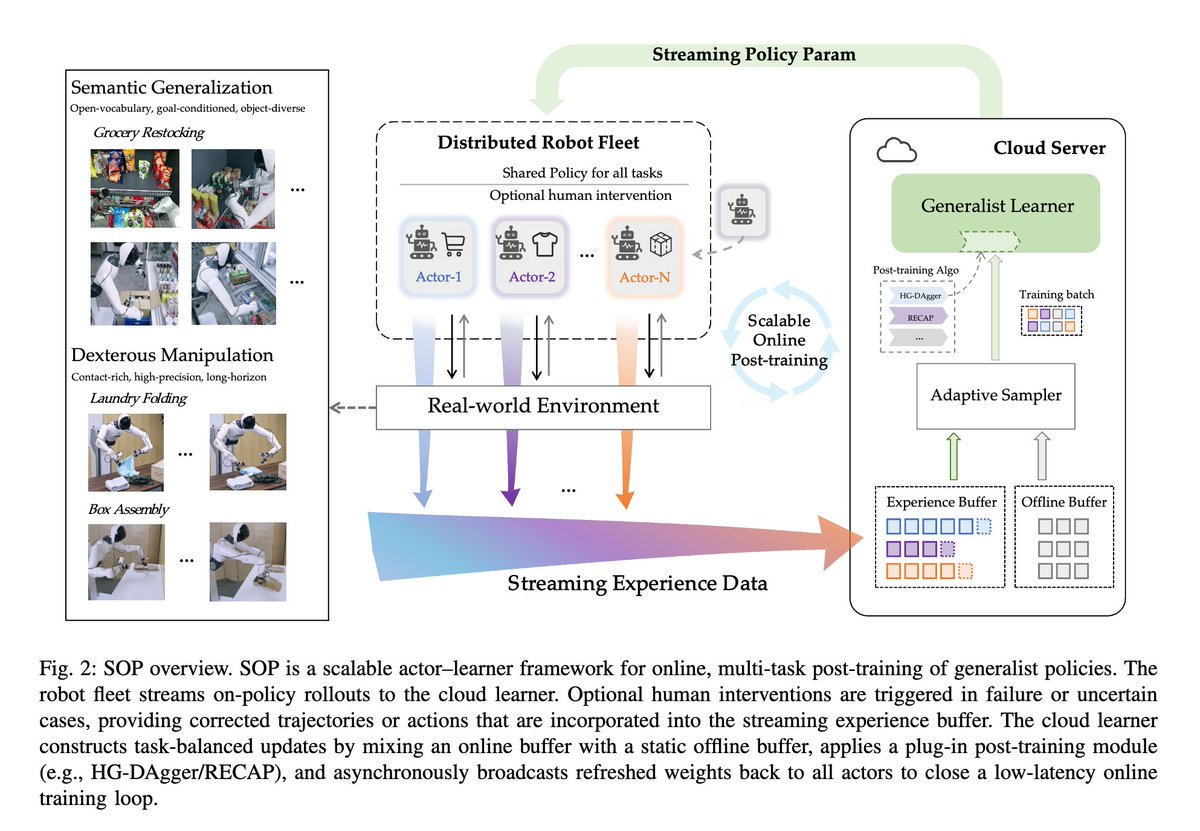
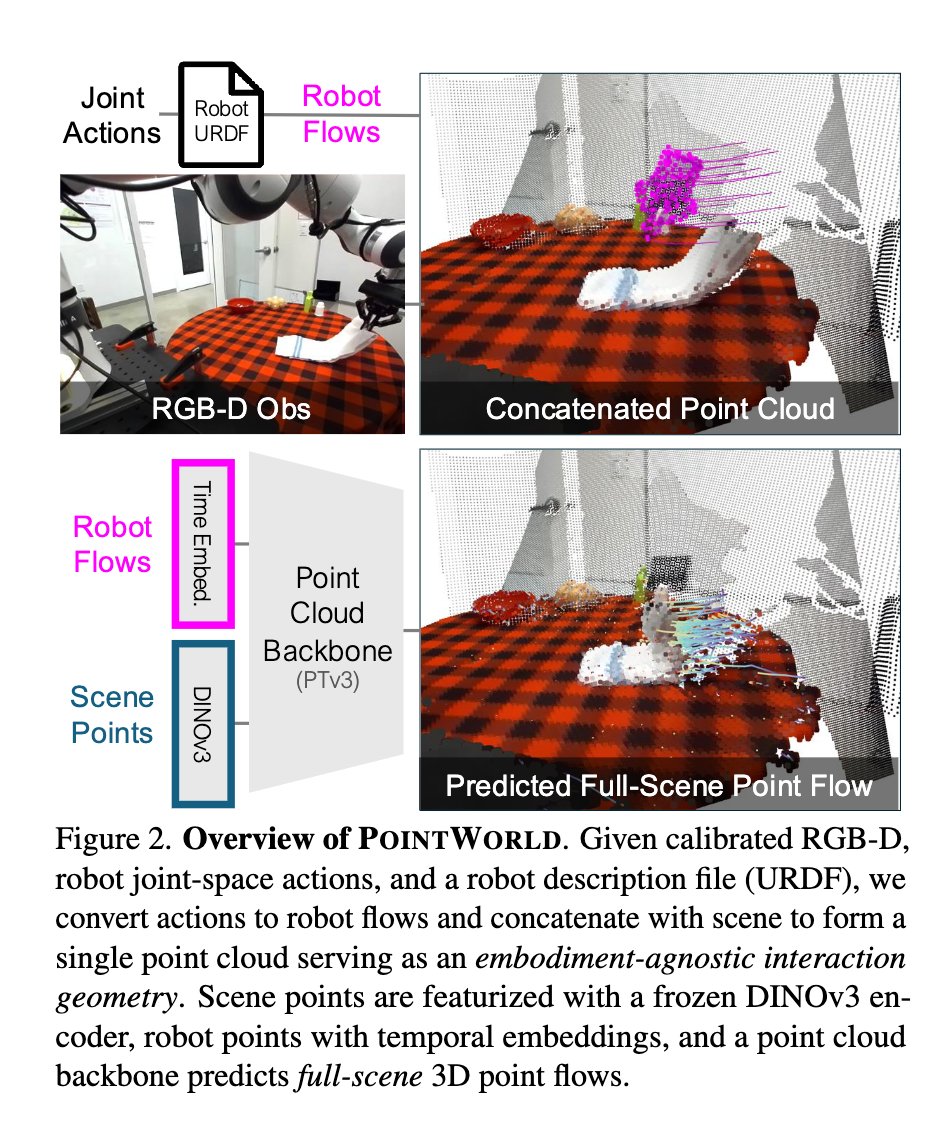
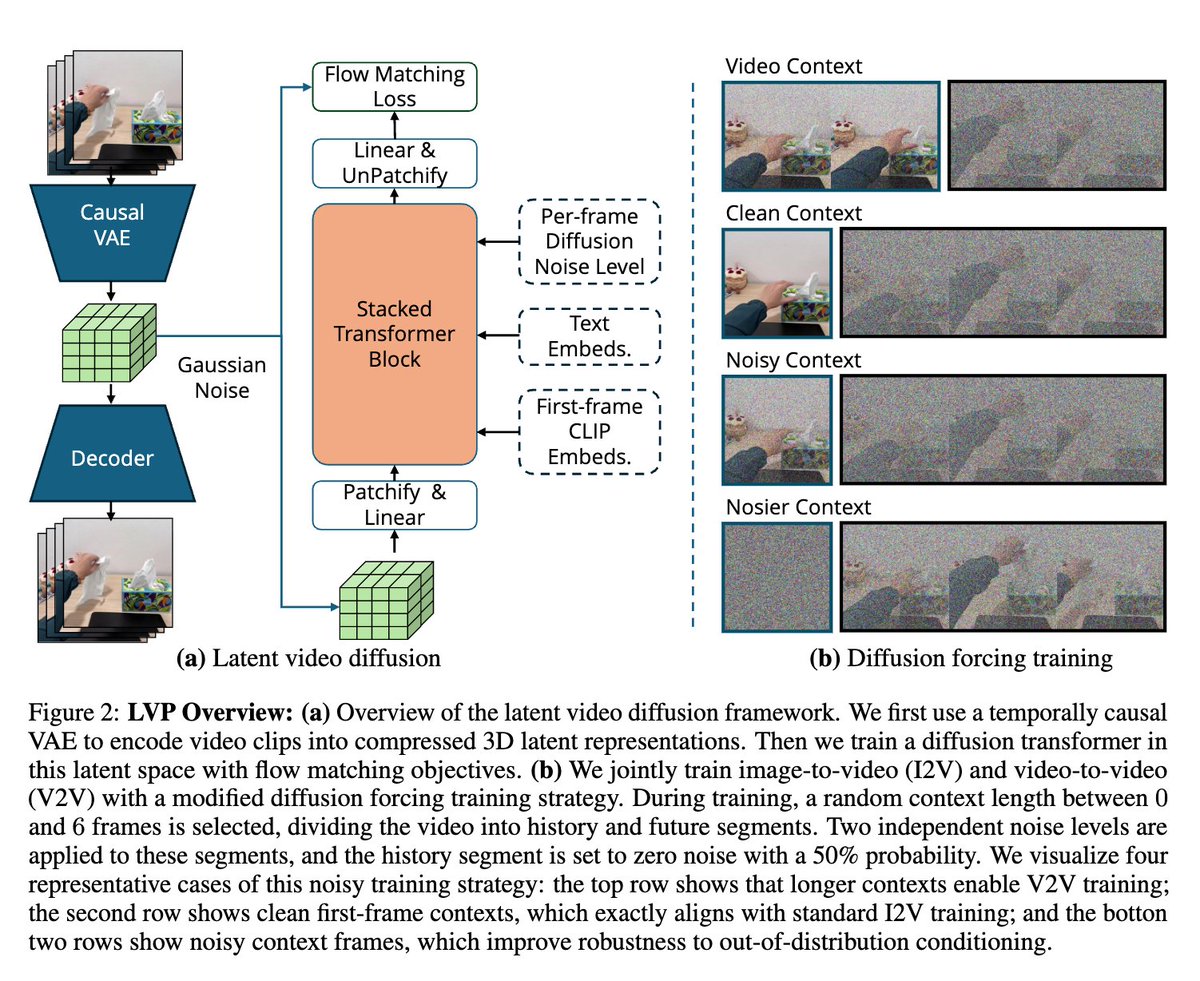
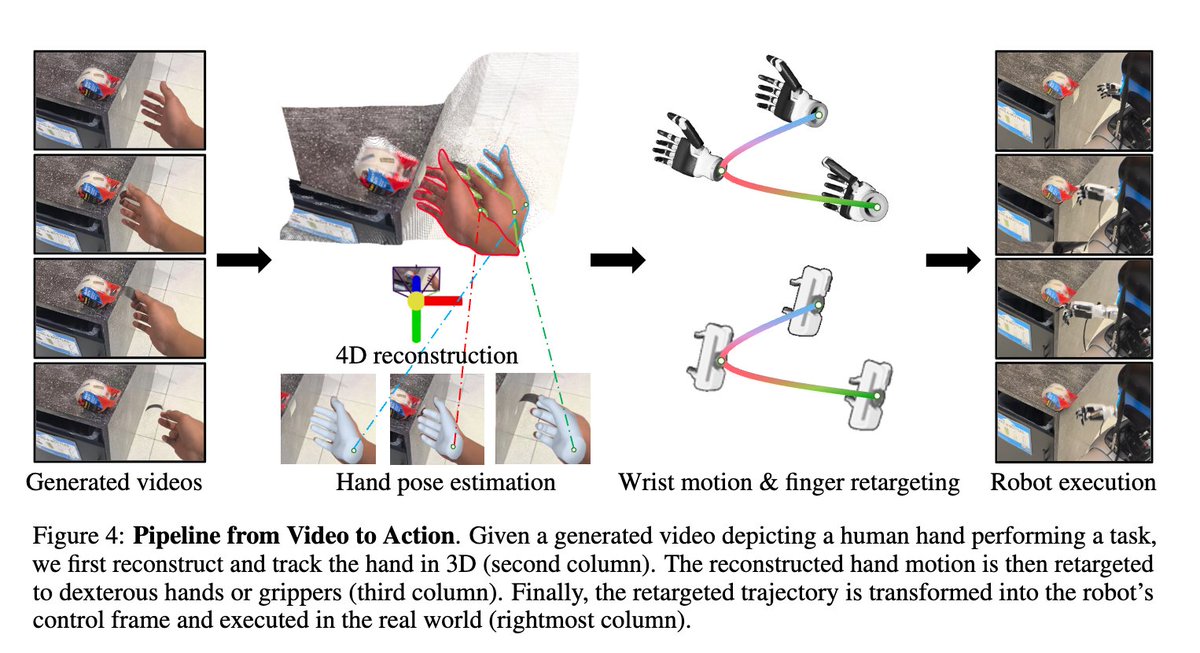
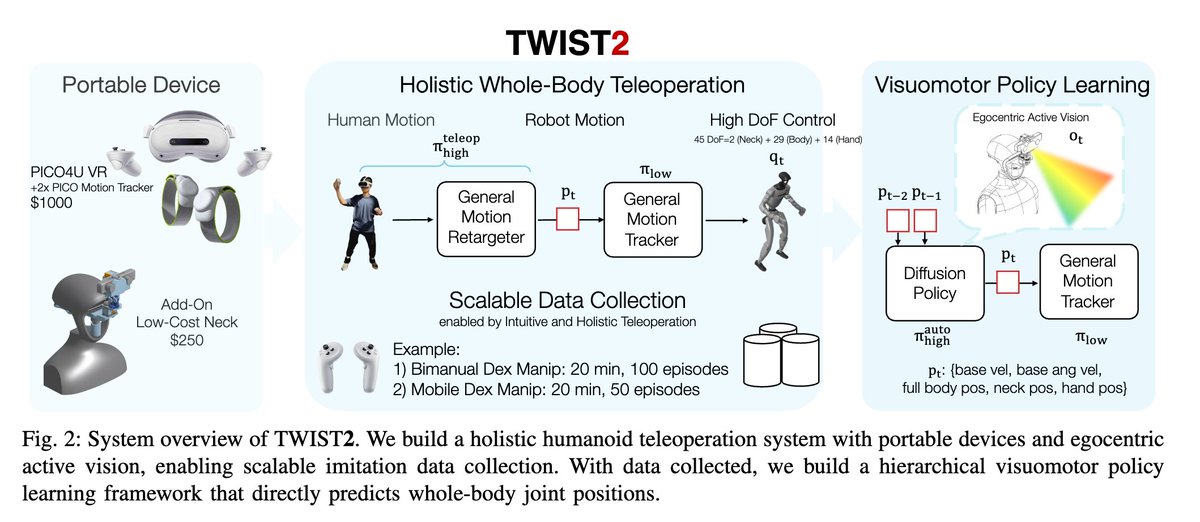
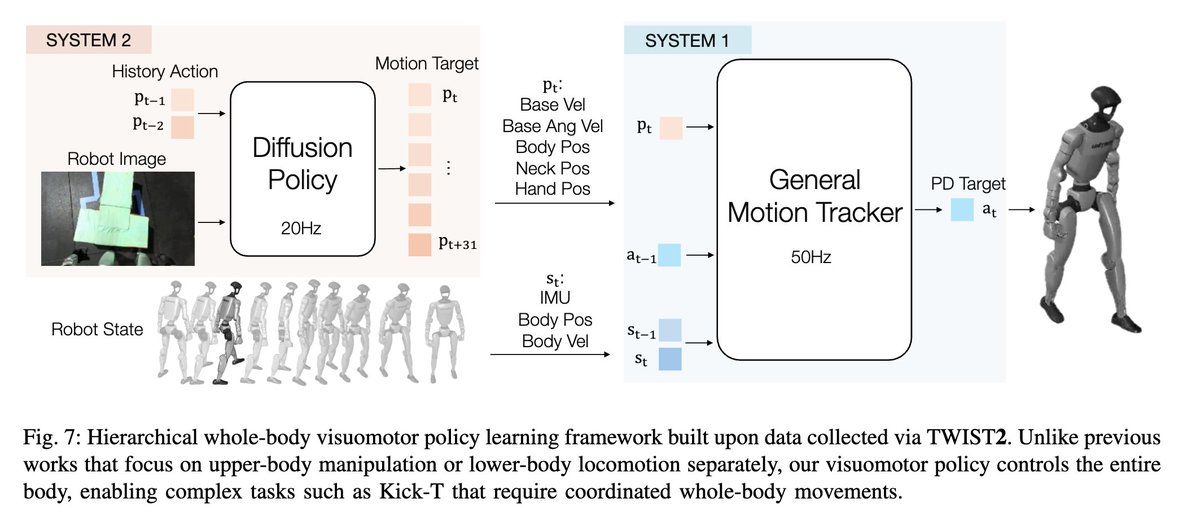
The flavor of the bitter lesson for computer vision
Blog: vincentsitzmann.com/blog/bitter_le…
This blog offers an interesting perspective on Bitter Lesson for the computer vision field: the author argues traditional computer vision, built around task-specific intermediate representations (e.g., classes, masks, 3D reconstructions), is becoming obsolete and will dissolve, and the real vision problem should be understood as end-to-end perception–action for embodied intelligence. This reflects the spirit of Rich Sutton’s Bitter Lesson: simple, scalable, general methods leveraging massive computation outperform handcrafted, modular systems.
English