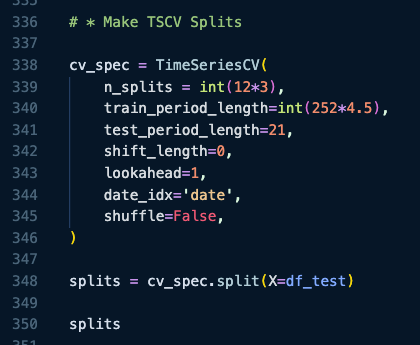
Sabitlenmiş Tweet

Francesco A. Fabozzi
27 posts

@FAFabozzi
Education & Research on LLMs and Quant Finance | Research Director @ Yale ICF | Managing Editor @ Journal of Financial Data Science | Data Science PhD

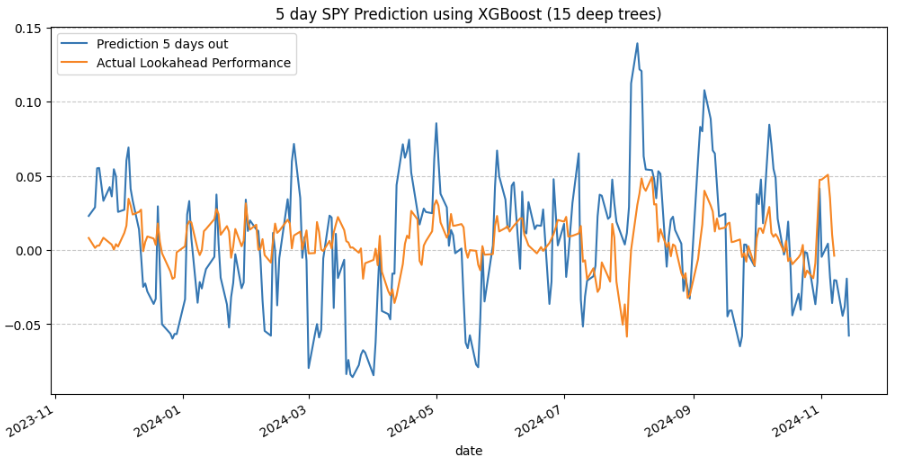
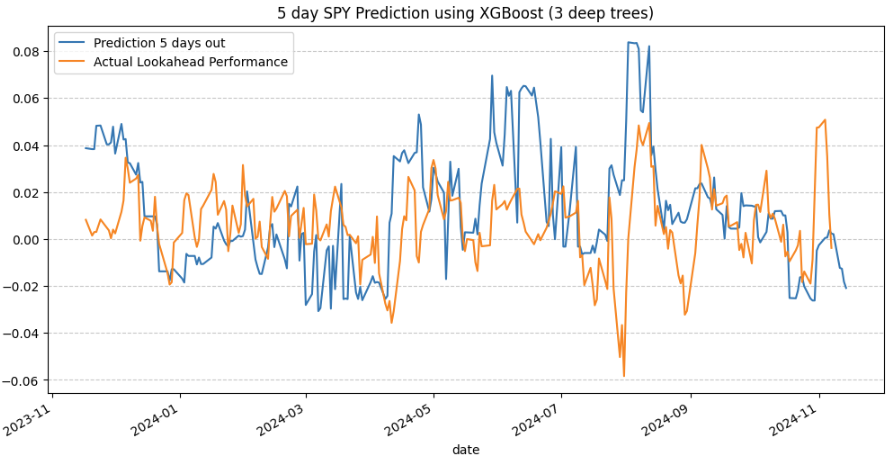


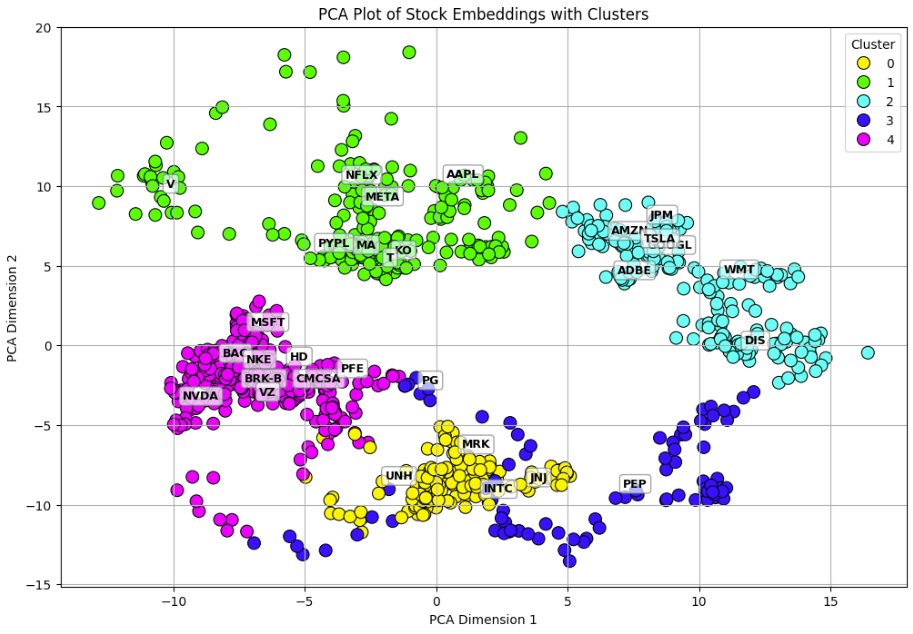
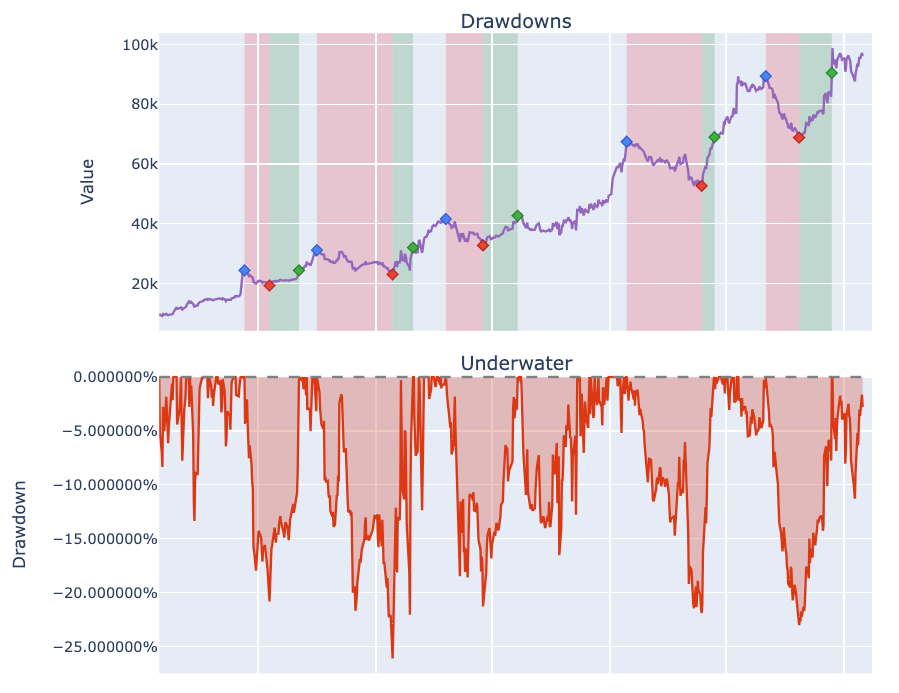
From my colleagues: “Can Machines Build Better Stock Portfolios?” aqr.com/Insights/Resea…