Sabitlenmiş Tweet

Stephen Panaro
904 posts

@flat
making coffee and other things. @BrewTimerApp
We are doing really cool hard tech at @trymirai, but until recently our social media feeds were full of linkedinish cringe. We decided to fix it and share more technial content I am currently working on our quantization pipeline, so here is a thread about LLM quantization


This developer just turned the iPad into Tom Riddle’s diary ‼️


I’ve been radicalized by MLX and now need a cluster of Mac minis

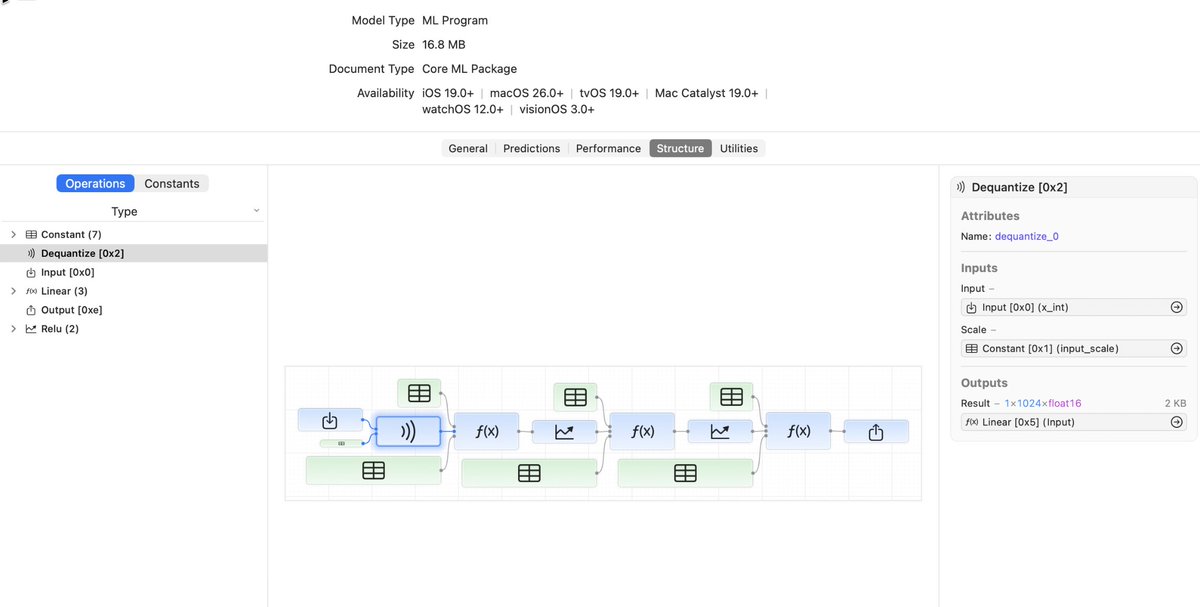
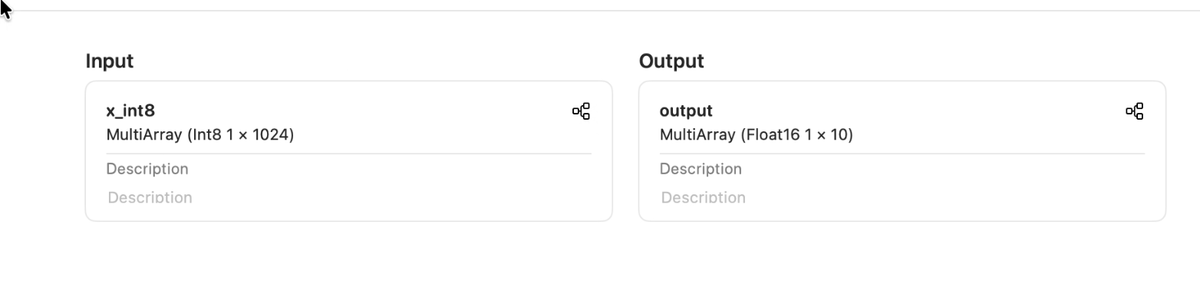
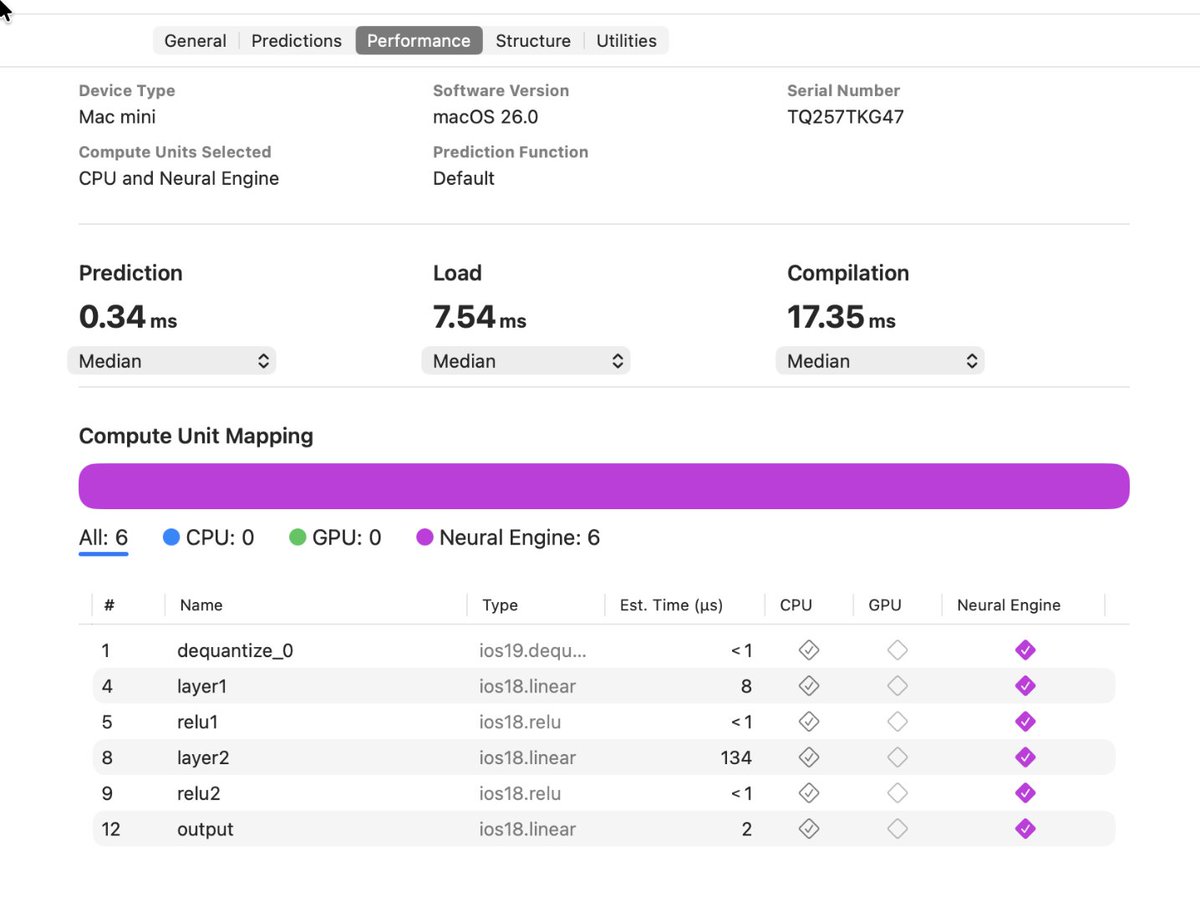
Wonder if we’re gonna get a new version of coremltools. Last year it dropped on Monday.

Its nightmare to think 2 layer MLP are super redundant: even if you have a global minima, there are at least n! more of em. For n = 8k, 2 layer MLP is like 10^27800 larger in terms of hypothesis space WHO ALLOWED THIS ???
Liking the line of research where you multiply LLM weights by rotation matrices and the model still works. Most do it in between layers, but you can also sneak one between Q/K and RoPE. Extra parameters? None. Useful? …Maybe. Cool? I think so. (See R₅ below.)