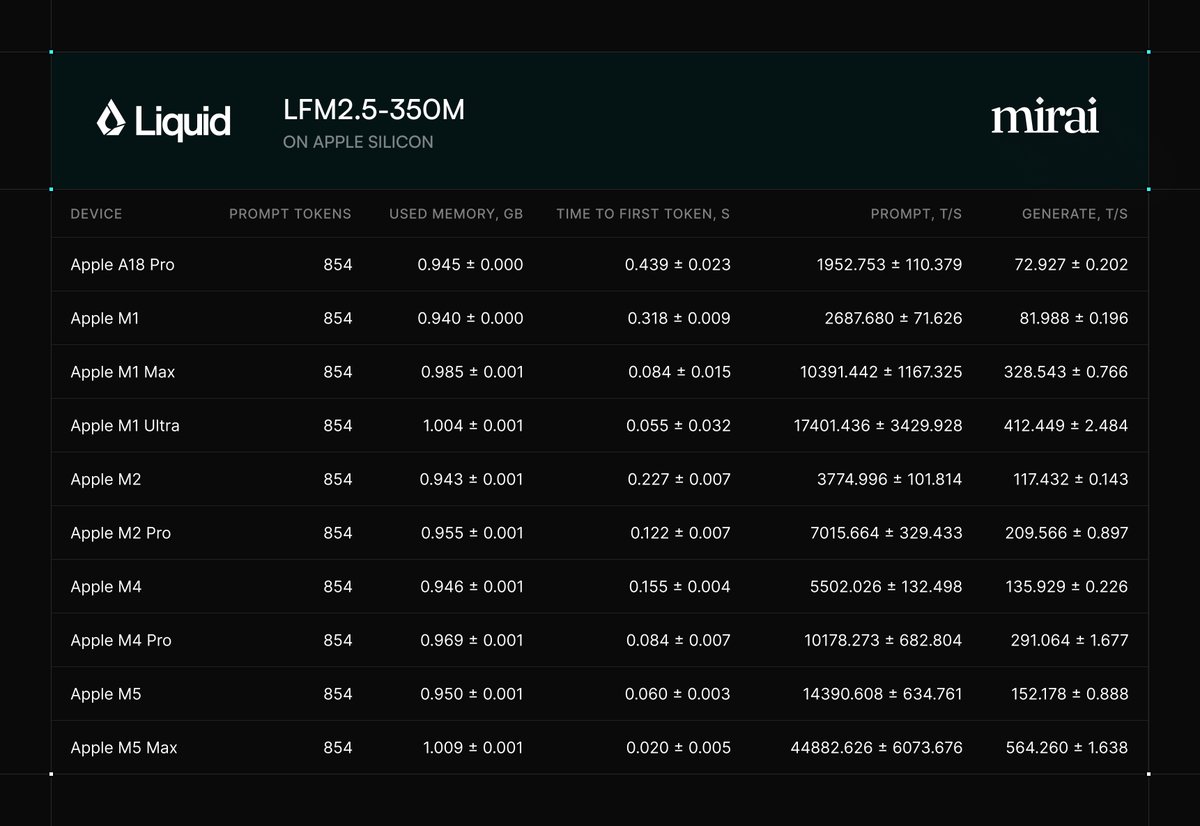
Google DeepMind released Gemma 4.
Our engineer @norpadon analyzed the architecture
Artur Chakhvadze@norpadon
Gemma 4 architecture analysis thread Just as Gemma3n, this thing has a galaxybrained architecture, very much not a standard transformer
English