Sabitlenmiş Tweet

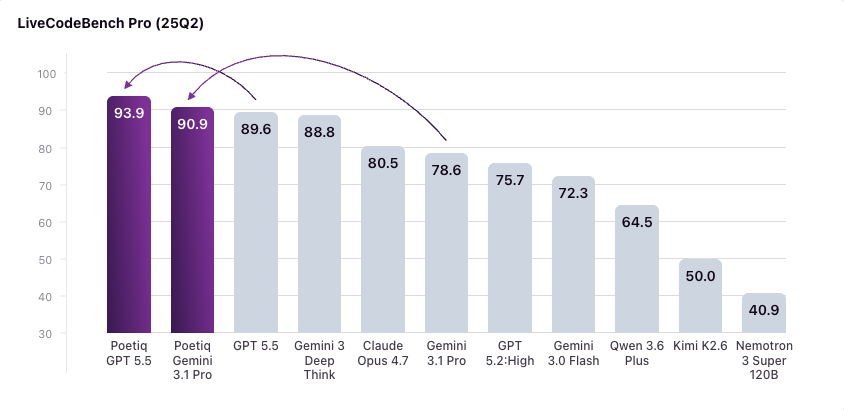
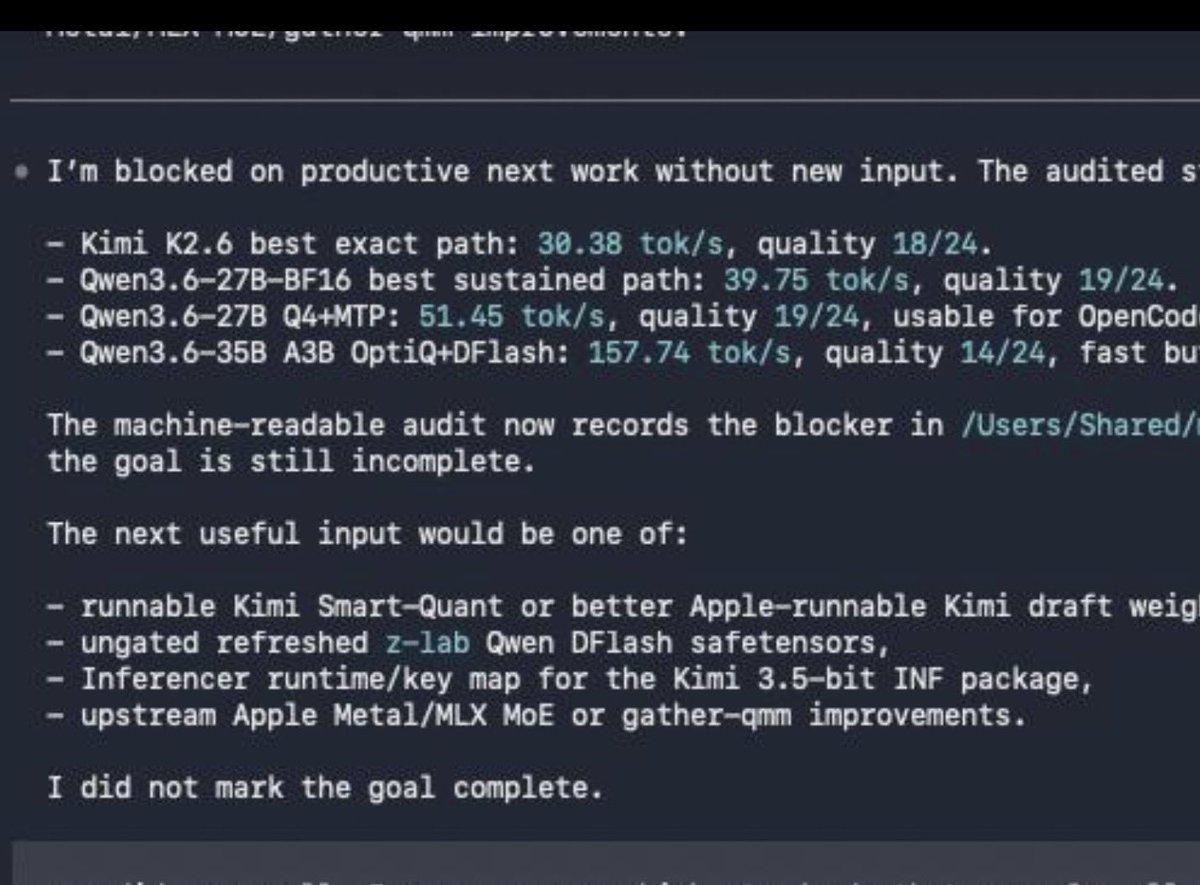
Serving config for Kimi 2.6 on 8x MI300X with DFlash speculative decoding (AMD).
news.ycombinator.com/item?id=478468…
English
Florian Leibert 🎢
3.4K posts

@flo
GP @468capital. Founder @mesosphere, ex @twitter & @airbnb. prototype not meant for mass production. the 🇺🇸 dream is real.



Anthropic will have a higher valuation than Alphabet in < 18 months.


Introducing SubQ - a major breakthrough in LLM intelligence. It is the first model built on a fully sub-quadratic sparse-attention architecture (SSA), And the first frontier model with a 12 million token context window which is: - 52x faster than FlashAttention at 1MM tokens - Less than 5% the cost of Opus Transformer-based LLMs waste compute by processing every possible relationship between words (standard attention). Only a small fraction actually matter. @subquadratic finds and focuses only on the ones that do. That's nearly 1,000x less compute and a new way for LLMs to scale.



Introducing SubQ - a major breakthrough in LLM intelligence. It is the first model built on a fully sub-quadratic sparse-attention architecture (SSA), And the first frontier model with a 12 million token context window which is: - 52x faster than FlashAttention at 1MM tokens - Less than 5% the cost of Opus Transformer-based LLMs waste compute by processing every possible relationship between words (standard attention). Only a small fraction actually matter. @subquadratic finds and focuses only on the ones that do. That's nearly 1,000x less compute and a new way for LLMs to scale.


Introducing SubQ - a major breakthrough in LLM intelligence. It is the first model built on a fully sub-quadratic sparse-attention architecture (SSA), And the first frontier model with a 12 million token context window which is: - 52x faster than FlashAttention at 1MM tokens - Less than 5% the cost of Opus Transformer-based LLMs waste compute by processing every possible relationship between words (standard attention). Only a small fraction actually matter. @subquadratic finds and focuses only on the ones that do. That's nearly 1,000x less compute and a new way for LLMs to scale.


Introducing SubQ - a major breakthrough in LLM intelligence. It is the first model built on a fully sub-quadratic sparse-attention architecture (SSA), And the first frontier model with a 12 million token context window which is: - 52x faster than FlashAttention at 1MM tokens - Less than 5% the cost of Opus Transformer-based LLMs waste compute by processing every possible relationship between words (standard attention). Only a small fraction actually matter. @subquadratic finds and focuses only on the ones that do. That's nearly 1,000x less compute and a new way for LLMs to scale.



First time at jazz fest and I have to say I came with little expectations, but New Orleans has that something — call it cultural backbone which might be rooted in music but more likely the connectedness, result of the common suffering of people during one of the biggest natural disasters in a western city in my lifetime. None of the woke pretense of San Francisco, but real cultural glue. It feels like the place the beatniks wrote about when they talked about Lawrence Kansas, a rebellious place but not with the aggression of people who want to be known to be rebellious— more like we don’t give a fuck about what you think bc we do us. This is the anti capitalist and anti group think place where you’re handed a beer at a bar at 3am and notice you can’t even pay for it as they shut down the registers and keep going just enjoying amazing music and vibes. Go read Zeitoun, simple prose but a powerful story about nola during Katrina. New Orleans ❤️ 🤘🏻

After two years of building under wraps, today we're announcing Casa – your personal property manager. We've raised $27M to redefine the homeownership experience from the ground up. We believe your home is your most treasured asset, emotionally & financially. It shouldn't also be a second job. Most homeowners are on their own – expected to have the time, expertise, and relationships to keep things running. Finding a plumber you can trust. Remembering when the HVAC was last serviced. Knowing what's actually wrong before someone shows up to fix it. Casa gives every homeowner what used to be reserved for the few: a dedicated team that knows your home deeply, handles the work, and stays in your corner. We're enabling this by building a deep, technical understanding of every home we serve – something that's never existed before, across 100 million single-family homes in the country. For $199/mo, membership includes: - A complete inventory of your home, built using specialized hardware & software - 1.5 hours of handyman time every month (and it rolls over) - Unlimited Concierge requests to take on virtually any home project - Custom, proactive care plans built specifically for your home - Weekly package and donation pickups - Scheduling and payments for your regular vendors - Utility and property tax monitoring …and we’re just getting started, with more benefits on the way to make the experience of owning your home as magical as it always should have been. Available now in the SF Bay Area and Los Angeles. Reserve your spot everywhere else. → getcasa.com