Sabitlenmiş Tweet

I couldn't be more proud of this tiny giant that is a great addition to the Gemma family!! I can't wait to see what the community will build with this powerful model!
Omar Sanseviero@osanseviero
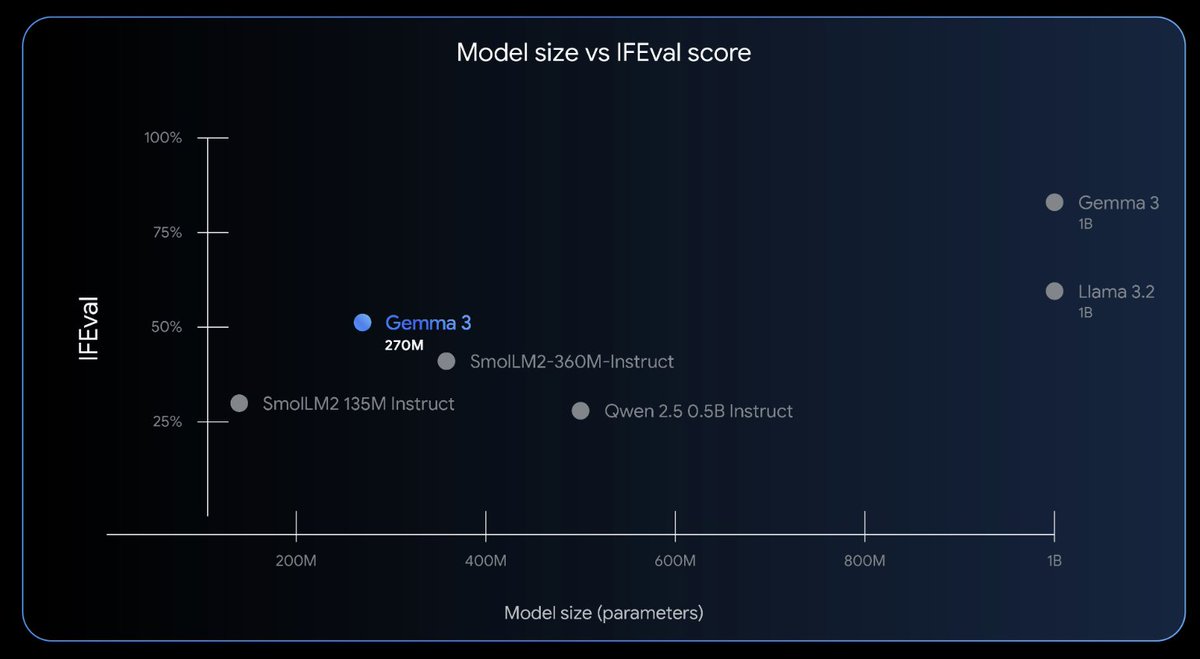
Introducing Gemma 3 270M 🔥 🤏A tiny model! Just 270 million parameters 🧠 Very strong instruction following 🤖 Fine-tune in just a few minutes, with a large vocabulary to serve as a high-quality foundation developers.googleblog.com/en/introducing…
English