Sabitlenmiş Tweet

FUNDA now offers the Market Top and Bottom Indicator, a mid to long-term contrarian signal system. Low scores signal buy zones, high scores signal sell zones.
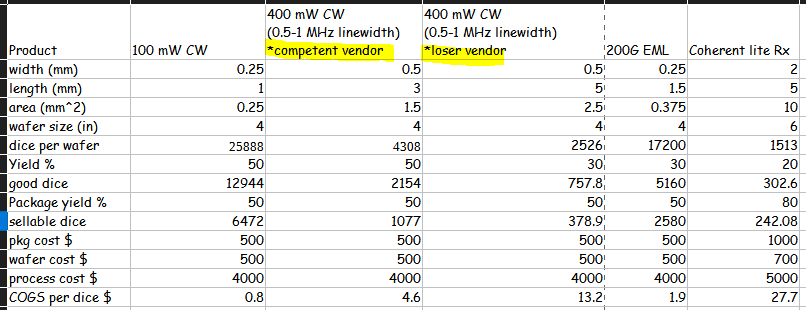
Top and Bottom Score
A 0 to 10 contrarian composite weighted across 11 sub-components, updated daily. Low readings correspond to fear, high readings to greed. As a high-conviction indicator, it triggers approximately 2 signals per year.
Component Breakdown
11 dimensions scored on a 0 to 10 scale, covering credit spreads, yield curve, equity flows, bond flows, hedge fund positioning, CTA positioning, long-only positioning, sentiment, greed, equity breadth, and credit technicals. Each score reflects that dimension's current contrarian reading.
Market Top and Bottom Indicator is available to all paid Substack subscribers.
Start here: funda.ai/zh/agent-chat?…

English