Sabitlenmiş Tweet

Didn’t expect ALE to spark this much attention — thanks for the interest !
It feels like we’re past the “prompt it and hope” phase.
The next leap is infrastructure for agents in real task environments!
Here’s the problem: Because of the lack of end-to-end infrastructure and scalable feedback loops, models can’t learn effectively from complex, multi-step interactions.
So we built ALE: an open Agentic Learning Ecosystem that closes the loopexecution → feedback → learning in executable environments.
Under the hood, ALE is powered by
ROCK:A sandbox environment manager that orchestrates complex trajectories at scale.
ROLL:A post-training framework dedicated to weight optimization.
iFlow CLI: An agent framework for efficient, configurable context engineering.
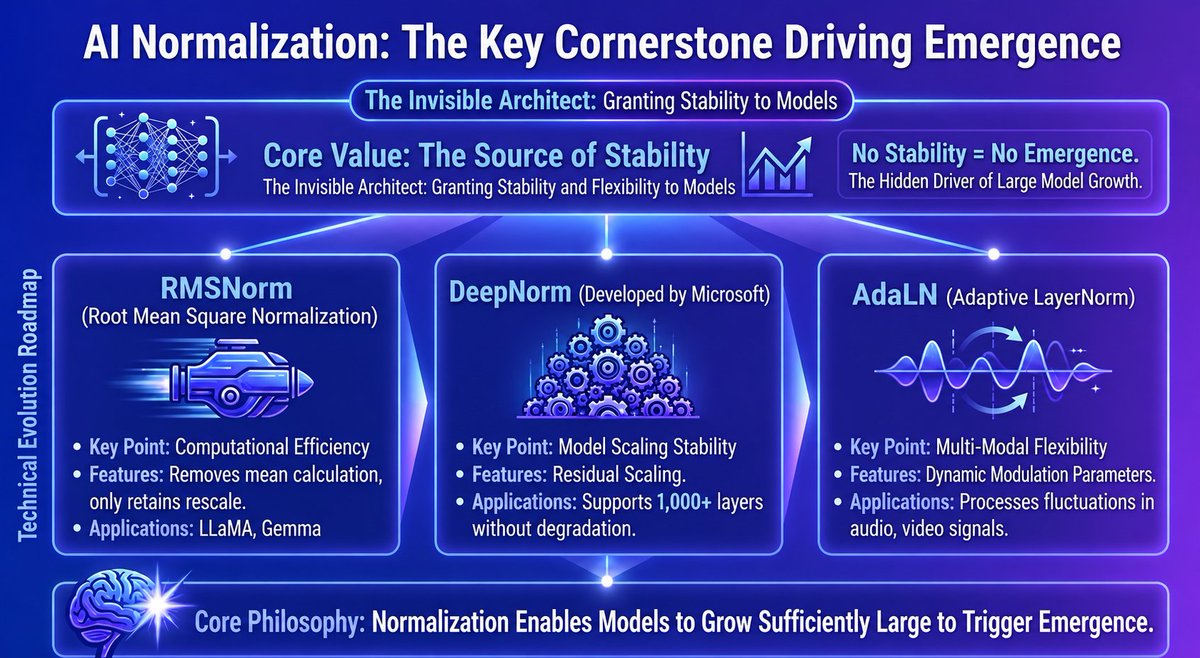
The Secret Sauce: IPA Algorithm
Standard LLM training fails on long tasks. Our IPA algorithm fixes this by optimizing for semantic interaction blocks—not just tokens—giving agents the stability to handle hundreds of steps.
The Capstone: ROME(ROME is Obviously an Agentic ModEl) was born naturally. Trained on 1M+ real trajectories.
ROME is a 30B-scale model, achieves 57.40% on SWE-bench Verified, outperforming similarly sized models and rivaling 100B+ giants.
30B is also the ‘sweet spot’ to get started — build your own “super ROME” from here.
We’ll keep sharing what we’re building next — agents, multimodal systems, and AI-native applications, powered by strong infrastructure like ALE.
If you’re building agents too, stay tuned!

English