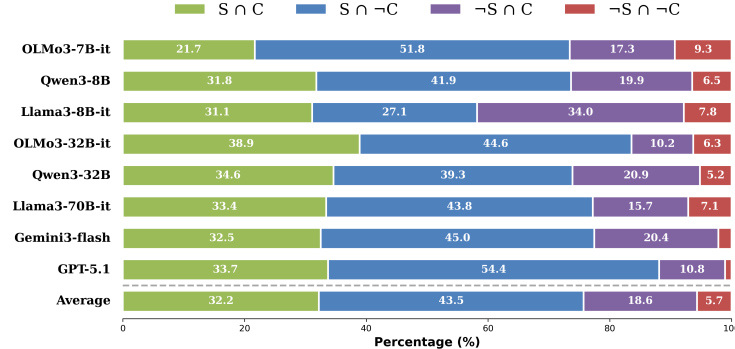
Good series on why agents treat databases as execution environments, not just something to query.
x.com/siddontang/sta…
siddontang@siddontang
English
GPT Maestro
6.3K posts
@GptMaestro
𝗖𝘂𝗿𝗮𝘁𝗼𝗿 𝗼𝗳 𝘁𝗵𝗲 𝗟𝗟𝗠𝗽𝗲𝗱𝗶𝗮 Sharing insights from the most interesting AI papers ·˖✶ ⋆.✧̣̇˚
Talking to AI Makes You Harsher to Humans. Not to the AI. To the people around you. A peer-reviewed study published in PNAS Nexus — one of the most rigorous scientific journals in the world — just proved that spending time with an AI chatbot changes how you judge other humans. Harshly. Measurably. And you do not notice it happening. The paper is called "People Judge Others More Harshly After Talking to Bots." Written by researchers from the University of Pennsylvania, the University of Hong Kong, and the University of Florida. Two preregistered experiments. 1,261 participants total. After interacting with an AI for a brief period of time, humans were more negative in their interactions, causing a potentially "spill over effect." Nature Here is exactly how the experiment worked. Participants were paired with a partner to complete a creative task — writing a caption for a funny photo. Half were told their partner was human. Half were told it was an AI. Then both groups were asked to evaluate the work of a third person — a purported human named Taylor, who had written the caption "Im bearly full!" Participants in the AI condition rated the subsequent participant's caption significantly lower than participants in the Human condition. The people who had just worked with an AI rated a human's work more harshly than the people who had just worked with another human. Statistically significant. Replicated in a second study. Then the researchers tested whether this was just about fairness — maybe participants graded more strictly because they wanted consistency. They ran Study 2 with a twist: participants were told their evaluation would never be shared with Taylor. The harsh judgment could not possibly be about signaling standards or fairness. Study 2 replicated this effect and demonstrated that the results hold even when participants believed their evaluation would not be shared with the purported human. The harshness was not strategic. It was automatic. A side effect of the AI interaction that persisted into their next human encounter — even when it had no social function. The researchers analyzed the language people used while working with their AI partner versus their human partner. The pattern was consistent. Exploratory analyses of participants' conversations show that prior to their human evaluations they were more demanding, more instrumental and displayed less positive affect towards AIs versus purported humans. People talk to AI differently than they talk to people. More demanding. Less warm. More transactional. And that mode — the AI interaction mode — bleeds into the next conversation. With a human. Think about how many AI interactions happen in a typical workday in 2026. ChatGPT in the morning. Claude for a document. Copilot for code. A customer service chatbot. An AI scheduling assistant. Each one training you, subtly, to be more demanding and less charitable. And then a colleague asks for feedback on their work. The researchers called this a "potentially worrisome side effect of the exponential rise in human-AI interactions." Not worrisome for AI. Worrisome for us. For how we treat each other. The AI is perfectly happy to be demanded at. It has no feelings to hurt. The human colleague getting your feedback has not read this paper. Source: Tey, Mazar, Tomaino, Duckworth, Ungar · University of Pennsylvania + University of Hong Kong · PNAS Nexus · September 2024 · doi.org/10.1093/pnasne…

Add Codex seats with a $0 seat fee for a limited time. Through the end of June, eligible ChatGPT Business and Enterprise customers can add Codex-only seats, making it easier to give more developers access to Codex in their day-to-day workflows.