
Greg Tarr
178 posts

Greg Tarr
@Greg_Tarr
ai researcher, cto @markovrobotics
Katılım Eylül 2019
1.8K Takip Edilen1.8K Takipçiler

@Greg_Tarr @agi_inc Is your impression that it generalizes well outside of osworld tasks?
English
@Greg_Tarr @agi_inc Cool, interesting. I saw that training used a base reasoning model. Can you say what that base reasoning model was?
English
@BenAybar @agi_inc Yes, it's a general model. It can perform coding tasks, but it's not optimized for programming - tools like Codex or Claude are much faster and better suited for that.
However, it can still assist in areas like automated UI testing when used alongside those specialised agents!
English
@Greg_Tarr @agi_inc Is this a general model? Can it perform coding tasks and whatever as well? It's listed that way on the Osworld-verified leaderboard but just want to confirm
English
Link: #benchmark" target="_blank" rel="nofollow noopener">os-world.github.io/#benchmark
English
we're hiring as well, come join us!
AGI, Inc.@agi_inc
AGI, Inc. is now the global leader on the AndroidWorld benchmark, with state-of-the-art verified performance of 97.4% This is a huge milestone for Android use, and just a sneak preview of what's coming - bringing trustworthy, reliable agents to every screen 🚀
English

The two main issues with GRPO:
1) No credit assignment, unless you do rollouts from each state (VinePPO-style), which is super expensive.
2) Doing multiple rollouts from the same state requires state resetting / copying capabilities. This is fine for question answering, and simple virtual environments, but quickly becomes unrealistic in more complex envs. Even exactly cloning a running docker container (including the state of running processes, etc.) is nearly impossible.
English
As promised here's a TPA implementation in PyTorch w/ KV cache: github.com/Greg-Tarr/tpa-…
Didn't reference the authors' code so it might deviate a bit. Next step is to add a kernel to compute attn scores without materializing a ⊗ b in memory

English
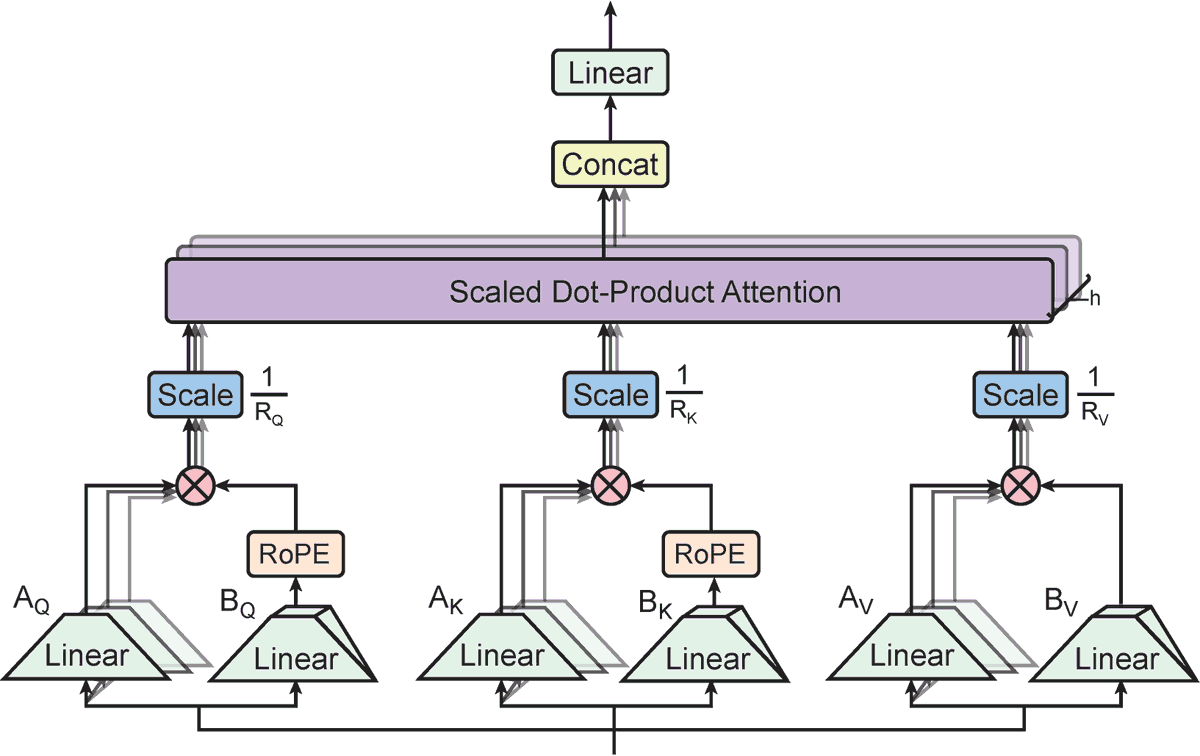
TPA (arxiv.org/pdf/2501.06425) is another banger paper. It has better (10x) KV cache compression than MLA ~and~ it's RoPE compatible. Haven't read the repo yet as I want to do a blind implementation tomorrow but I hear the authors are working on a kernel that computes attn scores without materializing QKV (directly from their factorized forms).
English
Titans (arxiv/2501.00663) is an all-round great paper. It reads almost like a blog post: probes prior research, asks pertinent questions, and naturally leads to a few elegant architectures that perform really well!
I'd have missed it if not for gh/lucidrains as I haven't seen anyone mentioning it here.
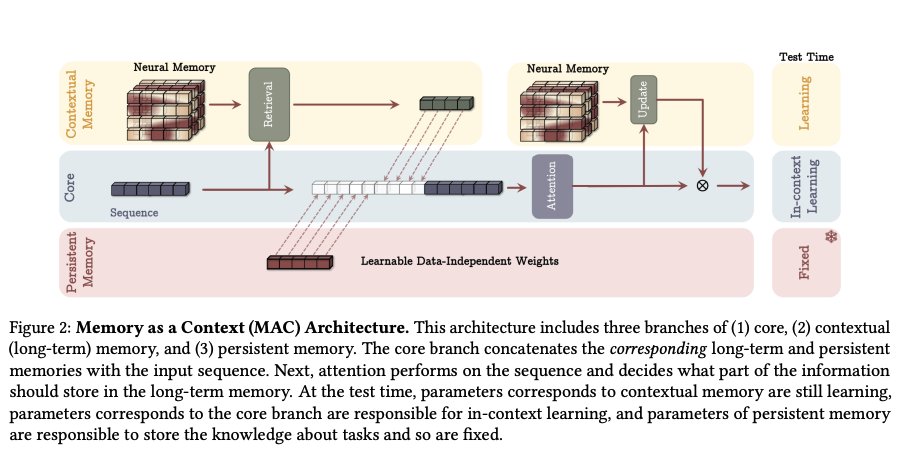
English

i was annoyed at having many chrome tabs with PDF papers having uninformative titles, so i created a small chrome extension to fix it.
i'm using it for a while now, works well.
today i put it on github. enjoy.
github.com/yoavg/pdf-tab-…

English
@scaling01 We’ll unlock better latent reasoning by lifting some unnecessary burdens we’ve been placing on our models.
Best I can think of is dense MLPs vs Memory+ layers. All those flops can go back to world modelling!
English

Don't you fucking dare make both options 50-50 😭
I know that scaling TTC is much better economically and probably also better for model performance. It's the easier path. But I think getting much deeper and larger models might also unlock better latent reasoning.
English
I'm so irrational about scaling laws.
I would love to see 100 trillion parameters before we see 1 million token CoTs.
What scaling are you more excited about?
English
@0xluffy @scaling01 It’s more important to deeply understand the landmark papers (>3m old and still influential) than it is to skim >10 bleeding edge papers everyday day.
Pick a landmark paper, set full reimplementation as your project for the week, and read as much as you can in the downtime.
English

how do you guys keep up with frontier research rn? is there an easier way (than arxiv) to find all these papers or is there a knowledge graph that aggregates it? rn only following people like @scaling01 closely
English
@shxf0072 @teortaxesTex @hwchung27 Structure tends to be temporary. I remember going from handwritten features to one-shot YOLO, and we’ll go from post-model MCTS to intra-model unstructured search spaces.
It’s just a consequence of identifying a problem and hacking a quick solution on top.
English

@teortaxesTex @hwchung27 fixing problems, instead of letting model learn to fix problem is structure
wild guess but i think its same story with o1,
ocra/step by step solving like dataset adding human cot structure to lm,
let them think free
English
this is how i feel about ++ tricks,
its easy to add structure, its hard to remove it

Teortaxes▶️ (DeepSeek 推特🐋铁粉 2023 – ∞)@teortaxesTex
I think the best modern Transformer+++ design (diff transformer, gated deltanet, sparse MoE, NTP+n, some memory etc etc) might be only one OOM away in efficiency from the Optimal Architecture, unless we cheat and search for strong humanlike inductive biases (which isn't The Way).
English

startup idea: Ramanujan AI
premise: humans all have similar brain structures, but only one in a billion is a true genius
hypothesis: maybe this is true for LLMs too
Step 1: train a billion 7B llama models from scratch w random initializations
Step 2: search through to find the Ramanjuan LLM
Step 3: ???
Step 4: profit
English
@_arohan_ I use runpod too (not for notebooks).
If you write a script to ssh and setup everything (e.g. git creds, clone, download buckets or whatever) you’ll save so much time.
Still a pain to setup every morning - was thinking of making a dev containers equivalent for my projects
English

Got myself runpod.io and a40 for prototyping. So far its smooth, I just need to figure out persistent storage across pods now.
rohan anil@_arohan_
Colab A100 experience is pretty awful for prototyping. The sessions take lot of time to connect. Are there other services out there which is not a DIY for a notebook+h100 experience?
English
@Springcoil Living between York (gf's uni) and Ireland - 90/10. Planning to apply to an AI lab next year which will probably bring me back to London!
English

@finbarrtimbers unfortunately discovered this by training 100-800m param models thinking my MTP implementation was faulty. Turns out 1B+ is where models prepare +1 token context and MTP starts paying off. Mitigated slightly by sequential MTP modules and scaling loss contrib. during training
English

