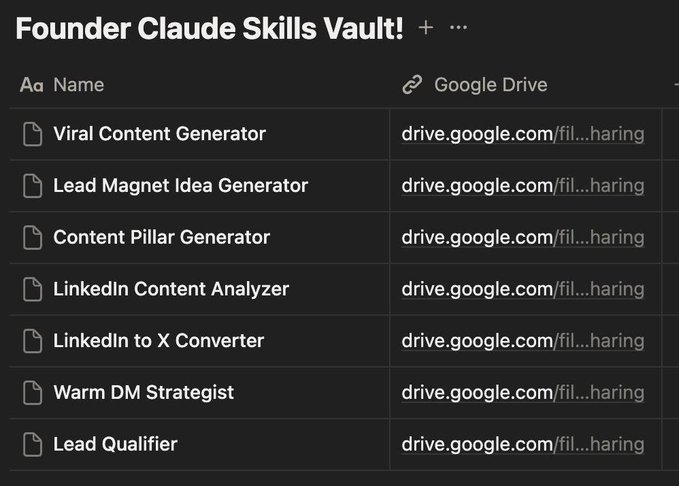
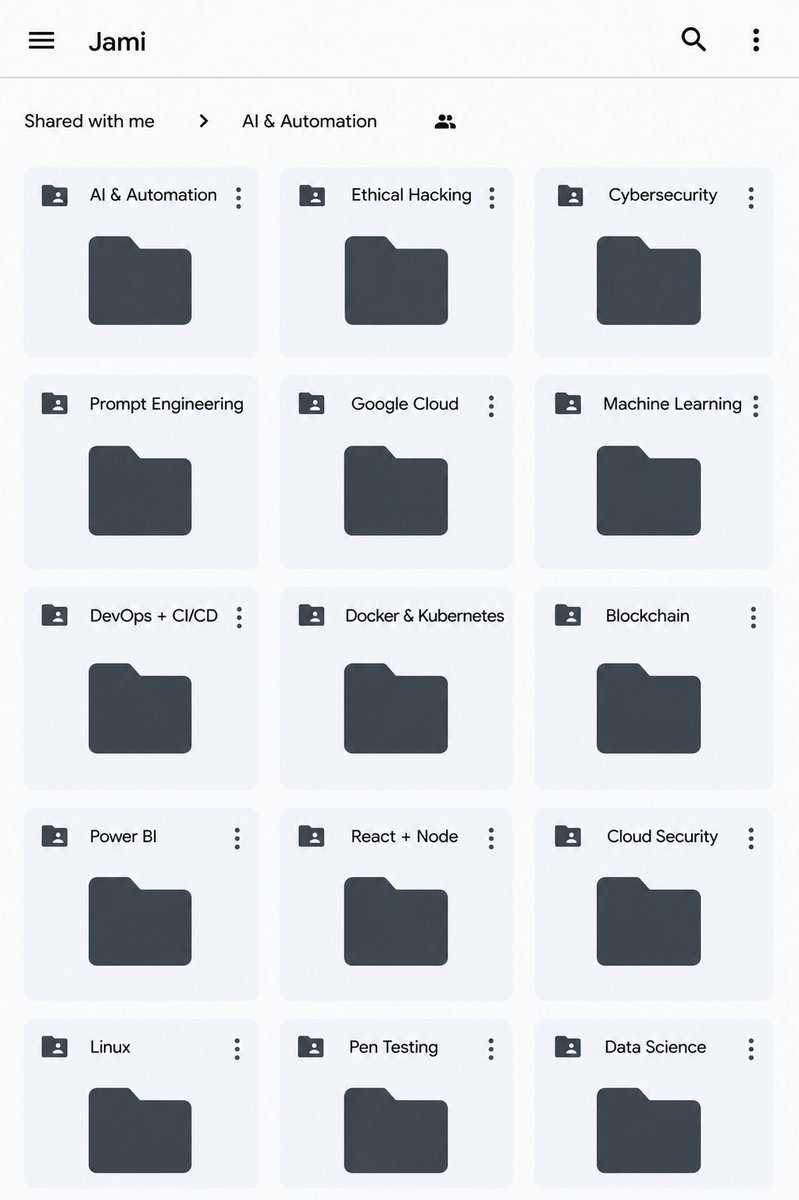
Sabitlenmiş Tweet

Holy Moly..
This caught my attention...
Everyone's racing to build better AI video models.
But what amazed me seeing 4K generation built directly into @capcutapp
Here's why that's exciting. 👇
English
GrowAIHub
19.4K posts

@GrowAIHub
Turning AI noise into clarity Tools • Threads • Growth Helping creators & devs win the future