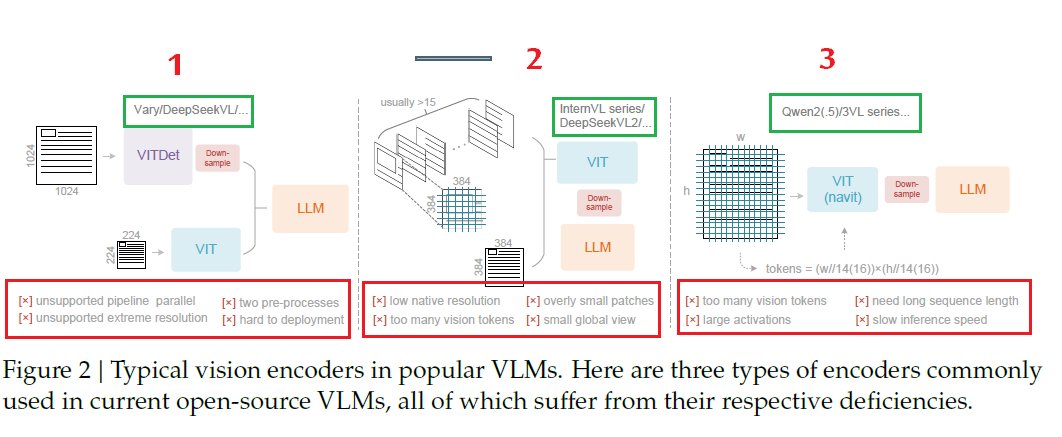
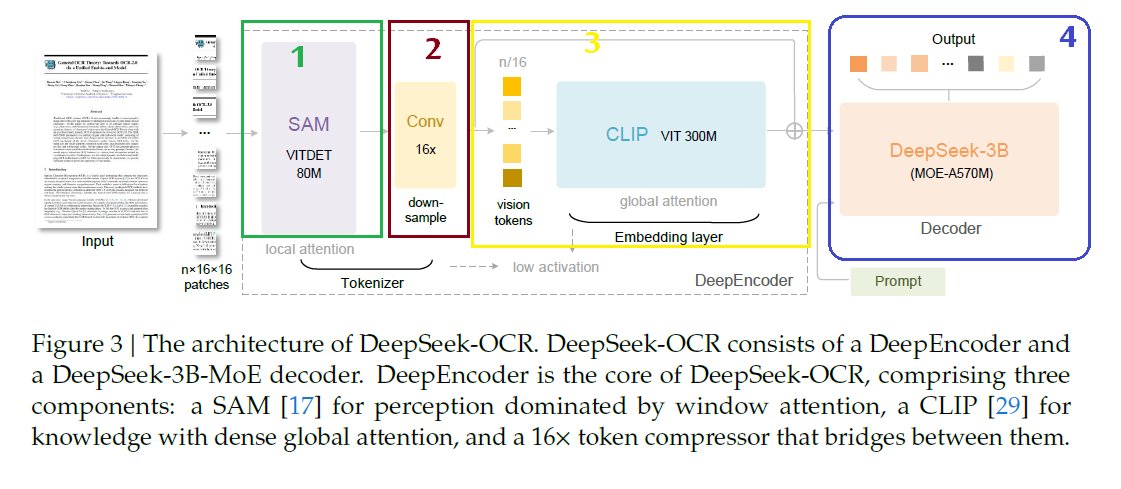
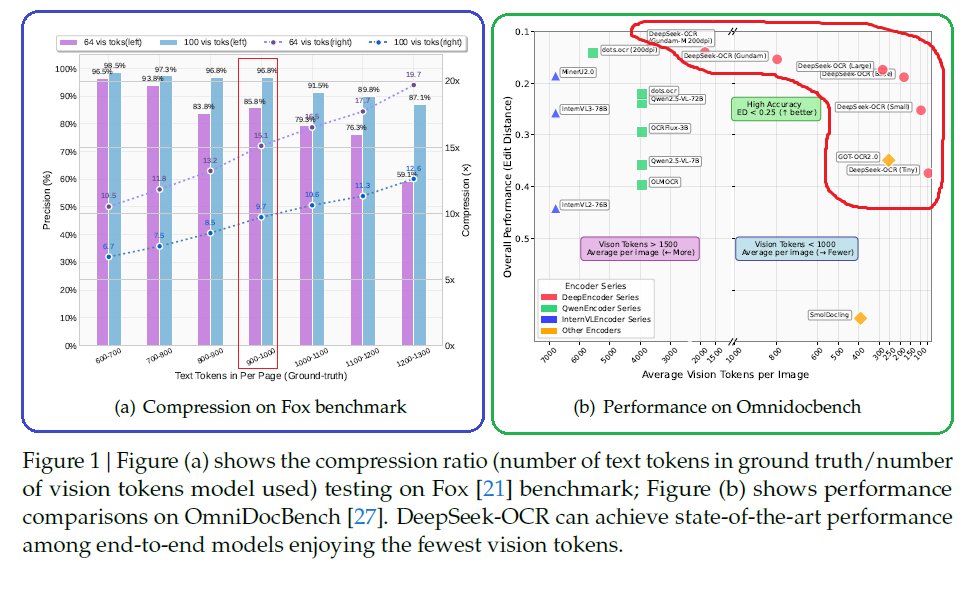
Sabitlenmiş Tweet

كيف استطاع نموذج من قوقل اكتشاف علاج محتمل لمرض السرطان؟ وكيف يعمل هذا النموذج؟
وهل ممكن نستخدم ال AI لعلاج أمراض أخرى؟
ثريد: 🔽

العربية
Hamad Alkalbani
920 posts

@Hamad_Mmk
AI Researcher | Passionate about AI | @KAUST_Academy Alumni | @TuwaiqAcademy Graduate




فخورين بإطلاق أول خدمة STT (تحويل الصوت إلى نص) لحظية ومباشرة Streaming بهوية سعودية كاملة 🇸🇦وبزمن إستجابة أقل من 100 ملي ثانية ! الصدمة؟ دقة تتفوق على عمالقة المجال مثل (Deepgram) بنسبة تصل إلى 40%! ✅ فهم أعمق للهجاتنا المحلية. ✅ سرعة معالجة فورية (Streaming) لتطبيقات مختلفة. ✅ أمان بيانات محلي 100%. متوفرة في استديو نبرة وعلى الAPI.. جربها الآن! 👇







إطلاق النسخة الرابعة من برنامج الذكاء الاصطناعي والنسخة الثالثة من برنامج المعلوماتية الحيوية! اكتسب قدرات متقدمة تشكل مستقبل الابتكار في المملكة العربية السعودية. 🇸🇦💚 بالشراكة مع @McitGovSa و #JARIR_Investment و #RZM_Investment، تجمع هذه البرامج بين التميز الأكاديمي والتدريب العملي لإعدادك في أسرع القطاعات نمواً في المملكة. هل أنت مستعد لتطوير خبرتك وصناعة المستقبل؟ تقدم الآن academy.kaust.edu.sa #KAUST_Academy #KAUST #SaudiTalent #SaudiVision2030 #AI #Bioinformatics

طور مهاراتك لمستوى أعلى. تابع فيديوهات مسار الشباب لحل مسائل KMC مع حلول تفصيلية. متوفر باللغتين العربية والإنجليزية للجميع. تدرب بذكاء، اطمح للأعلى، واستعد للمنافسة.


كيف استطاع نموذج من قوقل اكتشاف علاج محتمل لمرض السرطان؟ وكيف يعمل هذا النموذج؟ وهل ممكن نستخدم ال AI لعلاج أمراض أخرى؟ ثريد: 🔽