Learn. Build. Grow.
Join a community of passionate learners and start your journey into tech today.
📩 support@hannacode.com
#TechEducation #FutureDevelopers #CodingJourney #WebDevelopment #MobileDevelopment #SoftwareEngineering
English
HannaCode Academy
31 posts

@HannaCode_
Skills over degrees. At HannaCode, our expert instructors teach real-world skills to real people. We focus on hands-on learning and practical experience.
Happy Birthday To Me Thankful for another year. God has been my guide, my strength, and my source of growth. I am becoming the best version of myself because He is with me. Thank you YAHWEH. #TFV
Sweet environment 🥱... What’s stopping you from using @HannaCode_? Stop procrastinating and start using @HannaCode_ today the only platform to level up your coding skills!
Exactlyyy! We’re building a space where creators, educators, and community builders can grow and earn together. A home for all. Watch this space....
New course alert! MongoDB is now available on HannaCode Learn how to handle data the smart way with one of the most popular NoSQL databases used by developers worldwide. Don’t just learn build, practice, and grow with HannaCode 💚 hannacode.com #ProgrammingIsLife💻
Reinforcement Learning from Human Feedback (RLHF) in LLMs Step 1: Prompt Generation → Think of this as a teacher giving assignments → The pretrained LLM is asked different questions (prompts) Step 2: LLM Response Generation → The student (LLM) writes multiple answers → Example: Answer A → Answer B → Answer C → Some are good, some are weak, some are off-topic Step 3: Human Feedback & Ranking → Teachers (humans) grade and rank the answers → Best answer gets top marks, weaker ones get lower marks → Example: A > B > C Step 4: Reward Model Training → Instead of teachers grading forever, we train a teaching assistant (reward model) → This assistant learns the grading style of teachers → Now it can quickly score new answers without human effort every time Step 5: Policy Optimization (PPO Fine-Tuning) → The student (LLM) now practices with the teaching assistant’s feedback → Uses Proximal Policy Optimization (PPO) to improve step by step → Learns how to write answers closer to what teachers want Step 6: Improved LLM → The student (LLM) becomes more aligned, helpful, and safer → No longer just smart, but also well-behaved and human-friendly Flow from the Diagram Prompt (assignment) → LLM Responses (student answers) → Human Ranking (teacher grades) → Reward Model (teaching assistant) → PPO Fine-Tuning (guided practice) → Aligned LLM (improved student) 📖 For a complete deep dive into LLMs and AI foundations, check this ebook:codewithdhanian.gumroad.com/l/gbujqe
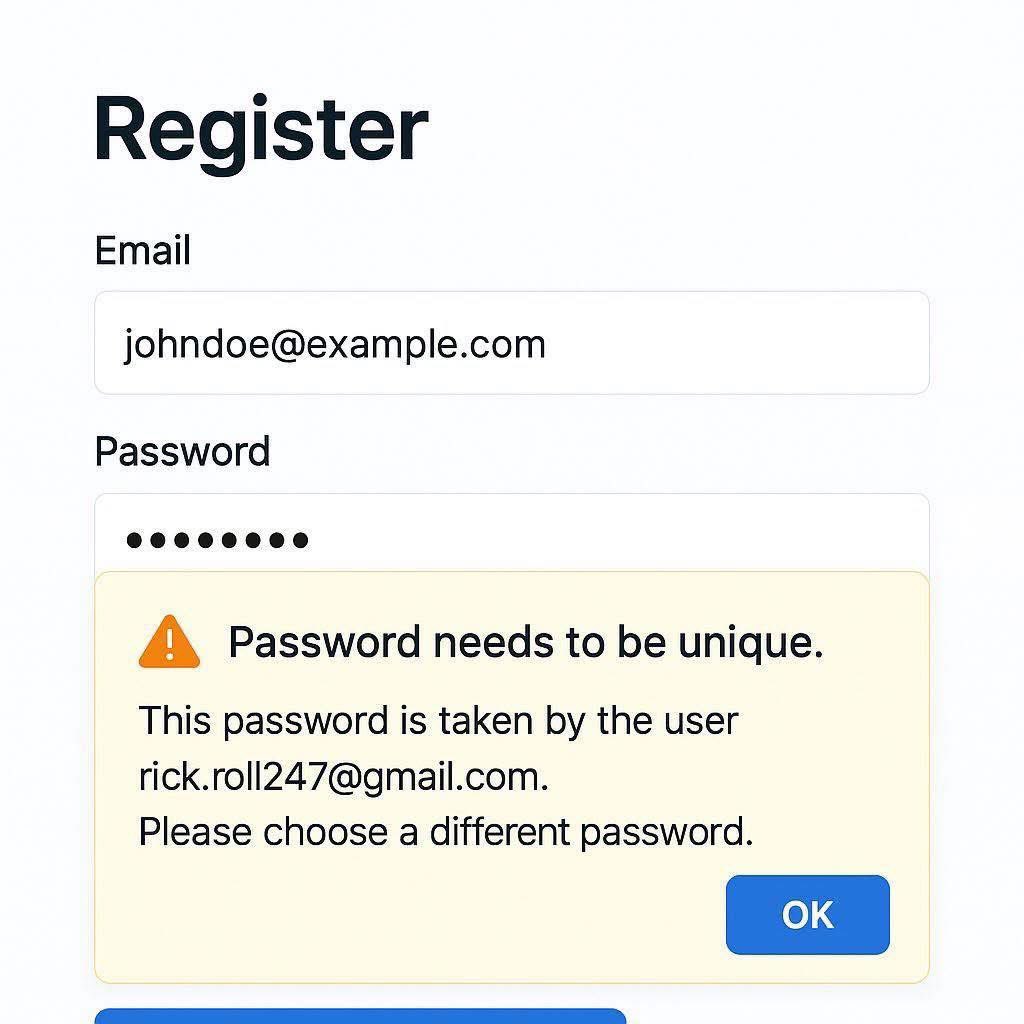
API Interview Cheatsheet
consistency looks like nothing is happening, until everything changes.
🌐 HTML Quiz Which HTML element is used to define the main content of a webpage, excluding headers, footers, and sidebars? A) <body> B) <main> C) <article> D) <div>
💻 HTML Quiz Which element defines the main heading of a webpage? A) <title> B) <header> C) <h1> D) <main>
Now we’ve made a massive upgrade Challenges are available in five programming languages and users will now get three challenges per day. That’s massive Procrastination won’t help you but consistency and determination will keep you focused and change your life forever. @HannaCode_