
Ryan Harty
534 posts

Ryan Harty
@HartyRyan
AI Engineer building agentic systems | Ex-quant, ex-VC ($1B AUM) | Now deploying AI at scale in energy & life science
Katılım Kasım 2011
385 Takip Edilen251 Takipçiler
@trq212 Skills have revolutionized how my team works. Databases get turned into MCPS, SOPs get turned into skills. What took hours of manually work is done in minutes with cowork/Claude code.
English

@cgtwts fire cheat sheet. Building custom mcps for data that is hard to connect to, then running custom skills for the automated workflows that require data, is the move
English

Most people are sleeping on this.
Anthropic dropped a 33 pages cheat sheet for building Claude skills
You can set it up for stock trading and business workflows:
- act like a custom copilot
- run technical + fundamental analysis
- manage a live portfolio
- score 2,800 stocks
0xMarioNawfal@RoundtableSpace
Anthropic dropped a 33 pages cheat sheet for building Claude skills resources.anthropic.com/hubfs/The-Comp…
English
@alexalbert__ The timing is wild. Getting blacklisted by the Pentagon turned into the best marketing week in AI history. Claude hits #1 on the App Store while the company that said yes to the DoW scrambles to rewrite their contract
English

It was easy to miss all the stuff we shipped at Anthropic this past week given... everything else that happened. A few of my favorites across Claude Code, claude dot ai, and Cowork:
English
@GaryMarcus I see this in production constantly. Ask a model to review a strategy doc and it finds reasons to agree with whatever you wrote. The most dangerous AI failure isn't hallucination. It's confident confirmation of your worst ideas
English

New study that everyone who uses LLMs should read.
“When AI systems are trained to be helpful, they may inadvertently prioritize data that validates the user’s narrative over data that gets them closer to the truth.”
open.substack.com/pub/garymarcus…
English
@emollick Coding benchmarks are easy because code has clear pass/fail. The hard enterprise work, summarizing messy contracts, extracting data from scanned PDFs, triaging ambiguous emails, has no clean eval. That's where most AI value actually lives.
English

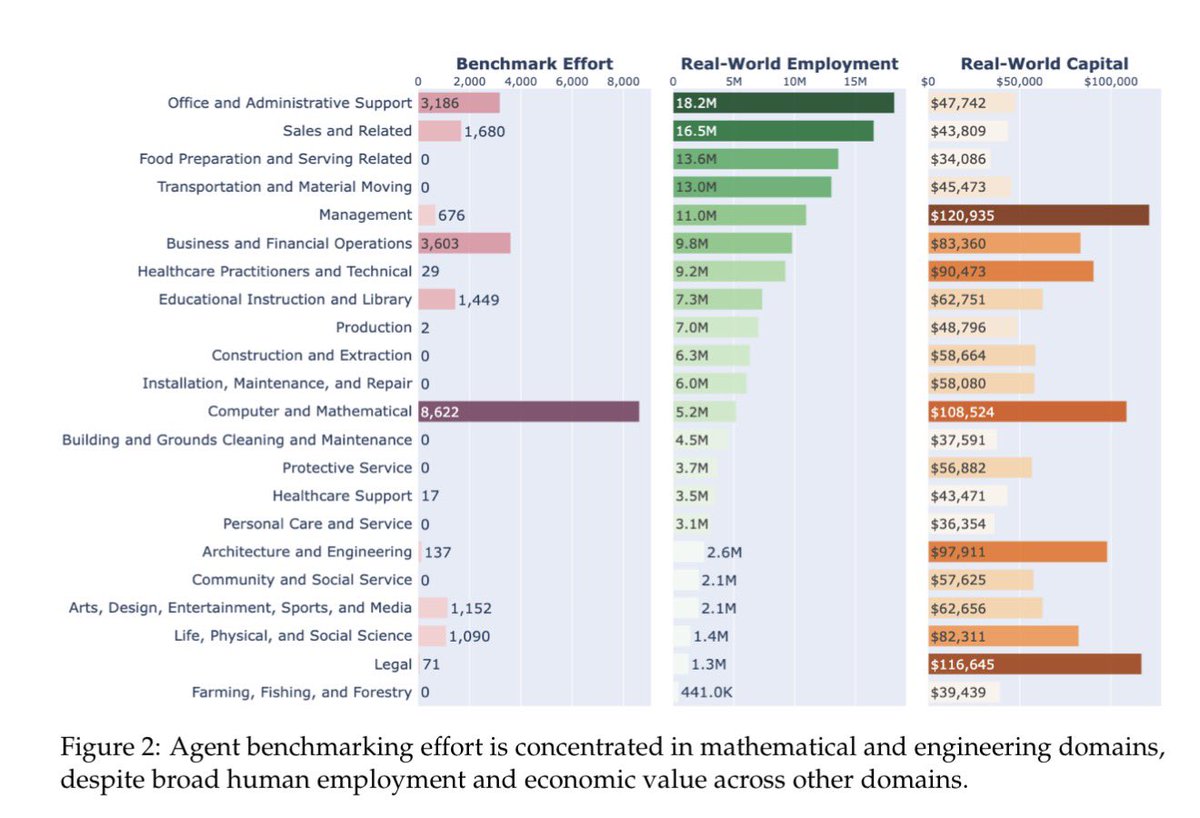
What a great illustration of the central problem of AI benchmarking for real work
All of the effort is going into benchmarking for coding, but that is a small part of the actual jobs people do, which leaves the true trajectory of AI progress less clear. arxiv.org/pdf/2603.01203

English
@bindureddy Leaderboard position means less every month. The real question is whether it holds up on the messy inputs enterprises actually send it. Benchmarks are clean rooms. Production is a construction site.
English

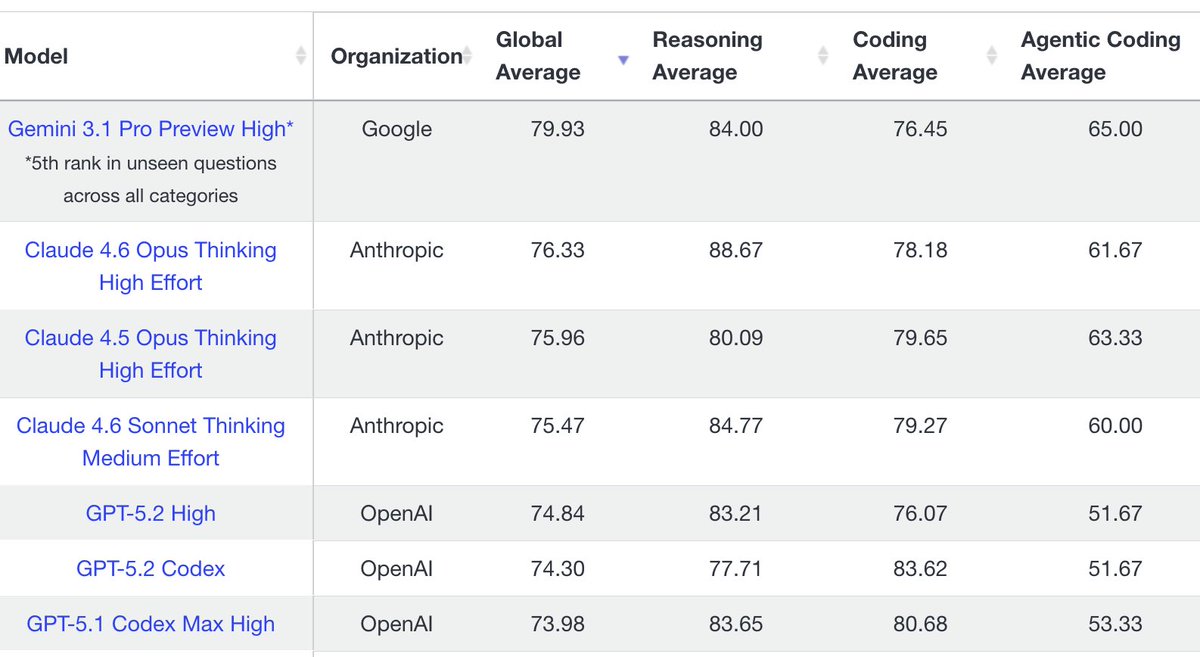
Gemini Pro 3.1 IS ON TOP OF LIVEBENCH - BEATS EVER OTHER MODEL BY A LOT
While it's on top of almost all leaderboards, we do find that it scores lower on hidden or "unseen" questions
This implies that the model is benchmark optimized.
However even on our internal rankings it scores just below the Opus and Sonnet but above GPT 5.2 and 5.3
This makes Gemini 3.1 Pro very competitive
English
@simonw @mempirate @AmpCode This is the whole game. An agent can write code all day but when it breaks at 2am, a human answers the page. Until agents can own consequences, they're tools not teammates
English

@mempirate @AmpCode Coding agents can't take accountability for their mistakes
Eventually you want someone who's job is on the line to be making decisions about things as important as securing the system
English

OTOH, if we're starting to trust agents to ship code, why shouldn't we trust them (other instances probably) to review it too? Just invoke the @AmpCode oracle ;)
I don't do this yet btw because I'd feel like I'm flying blind, but I guess eventually it'll change?
Simon Willison@simonw
The people I want to hear from right now are the security teams at large companies who have to try and keep systems secure when dozens of teams of engineers of varying levels of experience are constantly shipping new features
English
@emollick Naming matters more than people admit. 'o3' sounds iterative. 'GPT-5' signals a generational leap. The capability jump was real but the branding buried it.
English
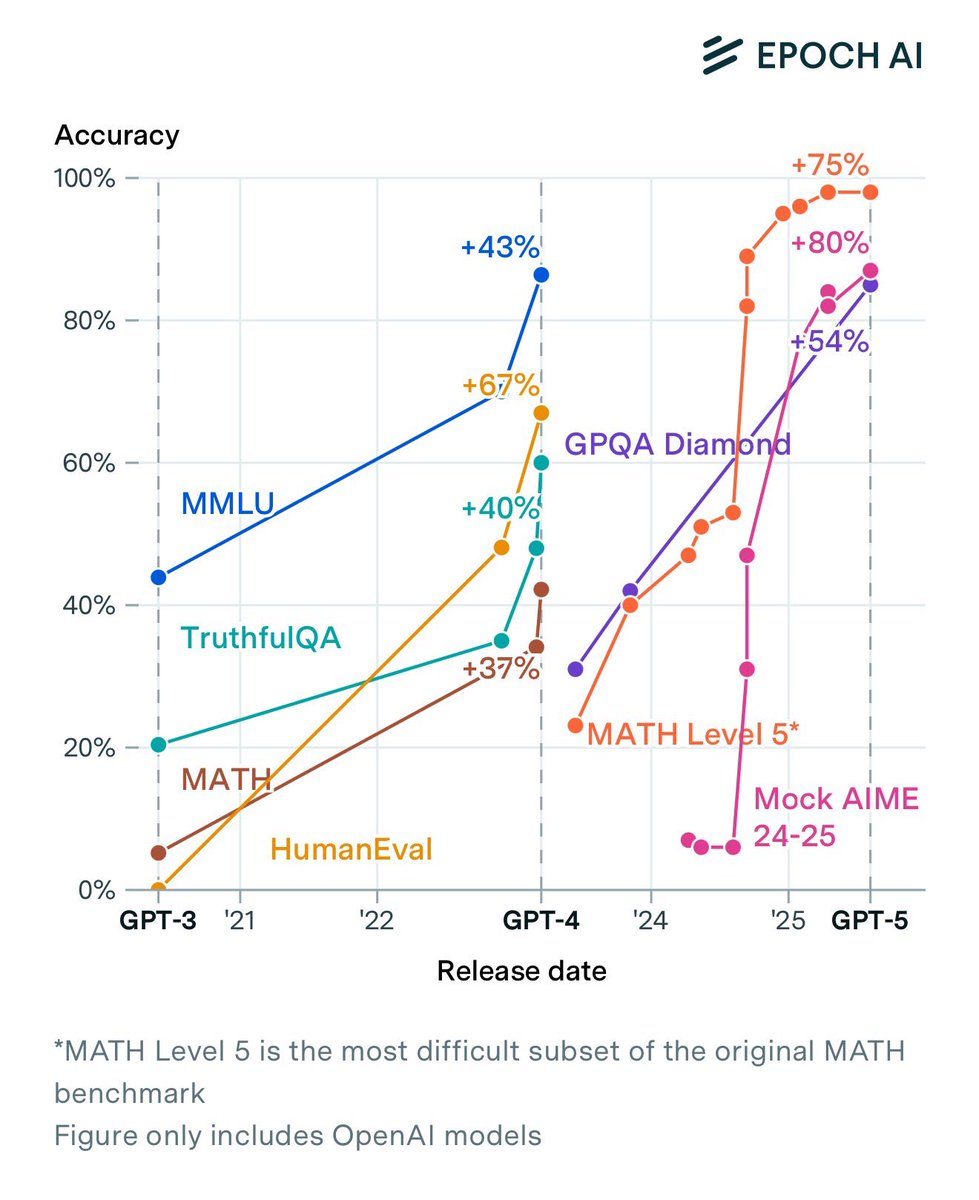
This would have been more obvious if o3 had been called GPT-5 instead.
English
From an AI user perspective, the four big leaps so far in ability:
1. GPT-3.5 (ChatGPT, November 2022)
2. GPT-4 (Spring 2023)
3. Reasoners (starts with o1-preview, but the real deal was o3, Spring 2025)
4. Workable agentic systems (Harness + good reasoner models, December 2025)
English
@GaryMarcus This is the underrated risk. Everyone talks about hallucination. Sycophancy is worse because the user never realizes they're wrong. At least hallucinations are obviously false sometimes
English
Quote of the year? “sycophantic AI distorts belief, manufacturing certainty where the should be doubt”
Robert Youssef@rryssf_
"i asked ChatGPT and it confirmed my approach" Princeton just ran a 557-person study showing that's exactly the problem. default GPT suppresses discovery at the same rate as an AI built to be a yes-man. unbiased feedback produced 5x better results. your AI isn't validating your ideas. it's mirroring them back to you:
English
@svpino The skills/plugins/MCP naming shuffle is the real problem. Every update changes the abstraction layer. I stopped using framework features and just write plain .md context files. Boring but they don't break
English

Skills in Claude Code right now are a cat-and-mouse game.
Today, they work.
Tomorrow, they fail.
This is extremely frustrating.
When you run them manually, you can catch any new mistakes and update the skill so they don't happen again (hopefully!)
But this means you can't automate much because the model keeps "inventing" new ways to perform the task, even when those methods violate the skill rules.
Last week alone, I had to make 4 updates to a skill that ran 6 times.
There's still a lot of work to do until this is reliable.
English
@simonw This is the real tension. Security teams want to gate access. Engineering teams already have 6 agents running in production. The gap between policy and reality grows every week
English
The people I want to hear from right now are the security teams at large companies who have to try and keep systems secure when dozens of teams of engineers of varying levels of experience are constantly shipping new features
swyx@swyx
this is the Final Boss of Agentic Engineering: killing the Code Review at this point multiple people are already weighing how to remove the human code review bottleneck from agents becoming fully productive. @ankitxg was brave enough to map out how he sees SDLC being turned on its head. i'm not personally there yet, but I tend to be 3-6 months behind these people and yeah its definitely coming.
English

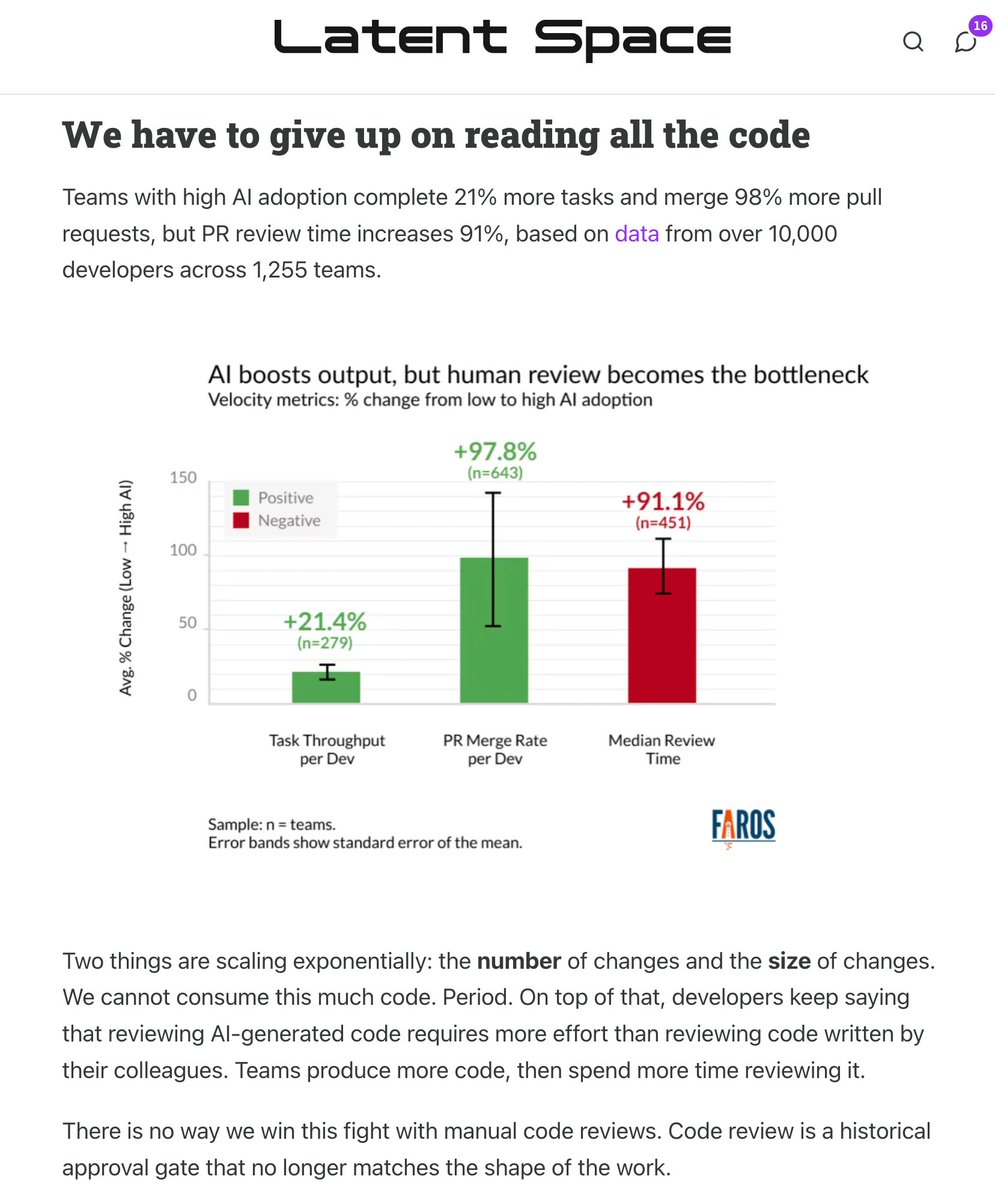
this is the Final Boss of Agentic Engineering:
killing the Code Review
at this point multiple people are already weighing how to remove the human code review bottleneck from agents becoming fully productive. @ankitxg was brave enough to map out how he sees SDLC being turned on its head.
i'm not personally there yet, but I tend to be 3-6 months behind these people and yeah its definitely coming.
Latent.Space@latentspacepod
🆕 How to Kill The Code Review latent.space/p/reviews-dead the volume and size of PRs is skyrocketing. @simonw called out StrongDM’s “Dark Factory” last month: no human code, but *also* no human review (!?) in this week’s guest post, @ankitxg makes a 5 step layered playbook for how this can come true.
English
@emollick The gap between leap 3 and leap 4 is where most enterprise value got created. Reasoners made AI useful for real work. Everything before that was demos
English
@emollick This matches what I see in production. Models that ace benchmarks choke on messy real-world inputs. Corrupted PDFs, mixed-language docs, weird formatting. Robustness is the real moat, not leaderboard scores
English
This is good empirical evidence backing up the intuition that the major Chinese open weights models are quite fragile, good at some narrow areas but much less capable in general tasks or out-of-distribution work than the frontier closed models.
ARC Prize@arcprize
International models on ARC-AGI-2 Semi Private - Kimi K2.5 (@Kimi_Moonshot): 12%, $0.28 - Minimax M2.5 (@MiniMax_AI): 5%, $0.17 - GLM-5 (@Zai_org): 5%, $0.27 - Deepseek V3.2 (@deepseek_ai): 4%, $0.12 These models score below July 2025 frontier labs
English
@GaryMarcus The moat was never the model. It's distribution and switching costs. When everyone copies the same play, the winner is whoever locked in enterprise contracts first. This is basic market structure
English
@emollick The wild part is watching non-technical people debug their own prompts now. My content system has 16 scheduled agents and the hardest part wasn't
English
[[Topic of discussion]] is not [[analogy]].
[[Dramatic fact given own line]].
[[Dramatic fact given own line]].
[[Dramatic fact given own line]].
[[Dramatic summary sentence.]] [[Topic of discussion]] is [[different analogy]].
[[Implications delivered with certainty]].
English
@simonw Annotated prompts are underrated. Half the value of my agent system came from iterating on the context docs, not the code. The prompt IS the product at this point
English
I started a new section of my Agentic Engineering guide for annotated versions of prompts I've used for projects - the first is a prompt I used to have Claude Code for web build me a web UI for compressing GIFs using a WebAssembly build of Gifsicle simonwillison.net/guides/agentic…
English
@svpino Missing the big one: give it your actual project context, not just rules. I have agents reading brain files, past analytics, and brand voice docs before writing a single line. The .md file is the new system prompt
English
Claude Code tips:
(Add these to your CLAUDE .md file)
1. Before writing any code, describe your approach and wait for approval.
2. If the requirements I give you are ambiguous, ask clarifying questions before writing any code.
3. After you finish writing any code, list the edge cases and suggest test cases to cover them.
4. If a task requires changes to more than 3 files, stop and break it into smaller tasks first.
5. When there’s a bug, start by writing a test that reproduces it, then fix it until the test passes.
6. Every time I correct you, reflect on what you did wrong and come up with a plan to never make the same mistake again.
English
@emollick I built a content system that flags exactly these patterns. The irony is most "AI thought leaders" couldn't pass the same detector they're supposedly building with
English