
HenyJone STEM
4.7K posts

HenyJone STEM
@HenyJone
每日分享喜欢的美食,美女,旅行还有各种科技❤️互关互粉互Fo💯回关 Share your favorite food, beauty, travel and various technologies every day😄
加拿大🇨🇦,多伦多 Katılım Kasım 2014
2.7K Takip Edilen3.1K Takipçiler


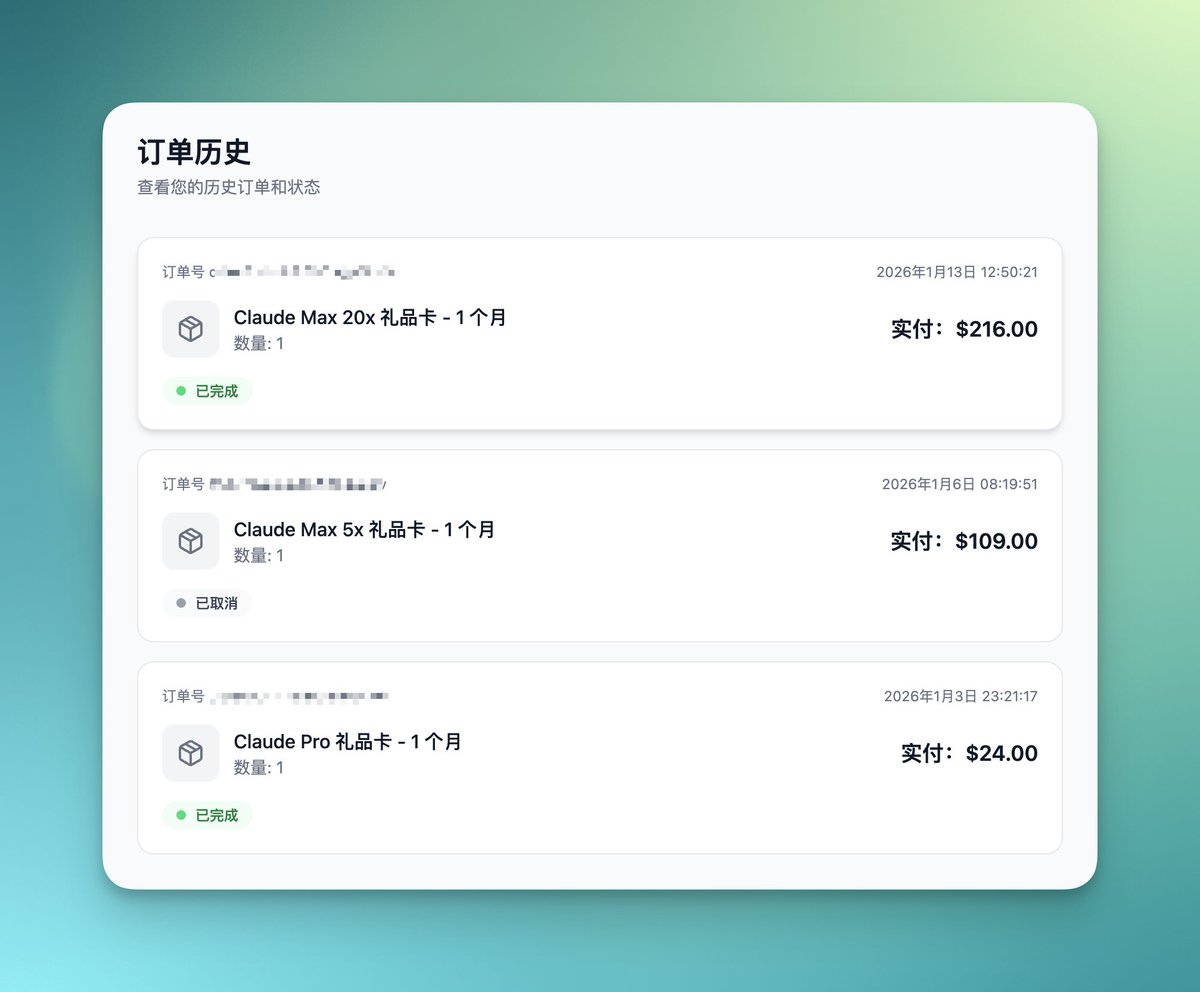
有 𝕏 友私信我是怎么开通 Claude Max 的?干脆记录一下:
0. 注册账号(见评论)
1. 在 meiguo.app/?ref=L9LPS 购买礼品卡
2. 点礼品卡链接激活
注意:
推荐先买 Claude Pro,不够再买 $100 Max;
$200 Max 实在用不完,如果要用完我得累死;
全程 TUN 模式,否则命令行不支持还存在封号风险。
中文



HenyJone STEM retweetledi

Claude Code 的创建者 Boris Cherny 公开了他的 CC 使用方法。
这套流程核心的两个思维方式比较有意思:
复利思维和验证
复利思维体现在 CLAUDE. md 不是一次性写完的文档,而是团队在日常工作中持续积累的知识库。每次代码审查、每次发现问题,都在让这个文件变得更好。
Boris 强调验证能让质量提升 2-3 倍,这其实暴露了当前 AI 编程的一个核心问题:AI 很会写代码,但不一定知道代码是否真的能用、用户体验是否好。
总结一下做个笔记👇
## 多实例并行:同时运行 15-20 个 Claude
Boris 的电脑上至少跑着 15 个 Claude 实例。终端里开 5 个标签页,每个标签编号 1-5,用 iTerm2 的系统通知功能知道哪个 Claude 需要输入。
浏览器里还会同时开 5-10 个 claude. ai/code 页面。他会在终端和网页之间来回切换,用 & 符号把本地会话转到网页,或者用 --teleport 在两边传送。这种并行工作方式让他能同时推进多个任务。
## 模型选择:全程 Opus 4.5 with thinking
Boris 只用 Opus 4.5,而且开着 thinking 模式。他的理由很直接:虽然 Opus 更大更慢,但因为理解能力强、工具使用准确,最后反而比用小模型更快。
不需要反复纠正和引导,一次就能做对,这才是真正的效率。
## 团队知识库:共享的 CLAUDE .md 文件
Claude Code 团队有一个共享的 CLAUDE. md 文件,提交到 git 里,整个团队每周都会往里面加内容。
这个文件的逻辑很简单:只要看到 Claude 做错了什么,就写进 CLAUDE. md,下次 Claude 就知道不要这么做。相当于把团队的代码规范和踩坑经验都记录下来,让 AI 助手也能遵守。
## 代码审查集成:@.claude 标签触发改进
在代码审查时,Boris 会在同事的 PR 上 @.claude,让 Claude 把发现的问题加到 CLAUDE. md 里。这是通过 Claude Code 的 GitHub action 实现的(用 /install-github-action 安装)。
这就是他们版本的"复利工程"。每次代码审查都在让 CLAUDE. md 变得更好,而 CLAUDE. md 又让后续的代码质量自动提升。
## Plan 模式:先规划再执行
大部分会话都从 Plan 模式开始(按两次 shift+tab 进入)。Boris 会跟 Claude 来回讨论,直到计划让他满意,然后切换到自动接受编辑模式,Claude 通常能一次性完成。
一个好的计划就是成功的一半。
## Slash Commands:内部循环工作流自动化
Boris 把每天重复做很多次的"内部循环"工作流都做成了 slash commands。这些命令保存在 .claude/commands/ 目录下,提交到 git。
这样就不用每次都重复输入相同的提示词,而且 Claude 自己也能使用这些命令。比如团队有一个 /verify 命令用来验证更改。
## Subagents:常见工作流的自动化
Boris 经常用几个 subagents:code-simplifier 在 Claude 完成工作后简化代码,verify-app 包含了端到端测试 Claude Code 的详细指令。
Subagents 本质上就是把最常见的工作流自动化,让每个 PR 都能跑一遍标准流程。
## PostToolUse Hook:自动格式化代码
团队用 PostToolUse hook 自动格式化 Claude 生成的代码。Claude 通常生成的代码格式就挺好,hook 只是处理最后 10%,避免后面 CI 报格式错误。
## 权限管理:预允许而非跳过
Boris 不用 --dangerously-skip-permissions。他用 /permissions 预先允许那些在他环境里确定安全的常见 bash 命令,避免不必要的权限提示。
这些配置大部分都保存在 .claude/settings.json 里,跟团队共享。
## 工具集成:Slack、BigQuery、Sentry
Claude Code 会使用 Boris 的所有工具。通过 Slack 的 MCP server 搜索和发布消息,用 bq CLI 跑 BigQuery 查询回答分析问题,从 Sentry 抓取错误日志。
Slack MCP 的配置文件 .mcp.json 也是提交到 git 跟团队共享的。
## 长时间任务:后台代理和 Stop Hook
对于特别长的任务,Boris 有几种方法:
让 Claude 在完成时用后台代理验证工作
用 agent Stop hook 更确定性地做验证
用 ralph-wiggum 插件(Geoffrey Huntley 最初想出来的)
在沙盒环境里,他会用 --permission-mode=dontAsk 或 --dangerously-skip-permissions,让 Claude 能持续工作不被权限提示打断。
## 最关键的一点:给 Claude 验证反馈
Boris 说最重要的是给 Claude 一个验证工作的方法。有了这个反馈循环,最终结果的质量能提升 2-3 倍。
Claude Code 团队用 Claude Chrome 扩展测试每个改动。Claude 会打开浏览器,测试 UI,然后迭代直到代码能跑、用户体验也好。
验证方法因领域而异。可能就是跑一个 bash 命令,或者跑测试套件,或者在浏览器或手机模拟器里测试应用。但一定要投入精力把这个做扎实。

Boris Cherny@bcherny
I'm Boris and I created Claude Code. Lots of people have asked how I use Claude Code, so I wanted to show off my setup a bit. My setup might be surprisingly vanilla! Claude Code works great out of the box, so I personally don't customize it much. There is no one correct way to use Claude Code: we intentionally build it in a way that you can use it, customize it, and hack it however you like. Each person on the Claude Code team uses it very differently. So, here goes.
中文
HenyJone STEM retweetledi


人类之光啊👍
Berryxia.AI@berryxia
🔥兄弟们!今天啥也没干,就给祖国的花朵和教育工作者,做了一套互动教学Skills! 直接让你的龙虾🦞OpenClaw 学习起来吧! 很多老师备课的时候,最头疼的就是那些抽象概念怎么才能让学生一眼就懂。 物理运动轨迹、数学函数图像、化学反应机理…… ✍🏻PPT讲得干巴巴,自己做3D互动又要学半天软件,时间精力根本不够。 我已经开源到 GitHub 上,直接做了个skills--AetherViz Master。 这个项目号称“互动教育可视化建筑师”,只要输入任意教学主题,AI就能一键生成一个完整、沉浸式、可交互的3D网页!零代码,普通老师也能秒变3D课件大师。 它有哪些优势呢? - 智能识别学科(物理/化学/生物/数学/天文/编程等),自动匹配颜色方案、渲染模式和专业语言 - Three.js r134 专业3D引擎 + SVG/D3.js 混合渲染,支持物理模拟、粒子系统、矢量箭头 - 拖拽旋转、滚轮缩放、触屏 pinch 操作,60fps 丝滑流畅 - 内置学习目标打卡、KaTeX 公式渲染、生活化类比、小测验面板、播放控制条 - 玻璃拟态现代UI,手机/平板/电脑全响应 对一线老师、在线教育创作者、想让学生秒懂抽象知识的朋友来说,这妥妥的是降维打击级的神器。 强烈推荐大家立刻试试,把你的课堂变成沉浸式3D宇宙吧! 地址:GitHub:github.com/andyhuo520/aet… 记得给我Star⭐️啊!一键三连哦!
中文
HenyJone STEM retweetledi

六招升级 OpenClaw 成为最强辅助!
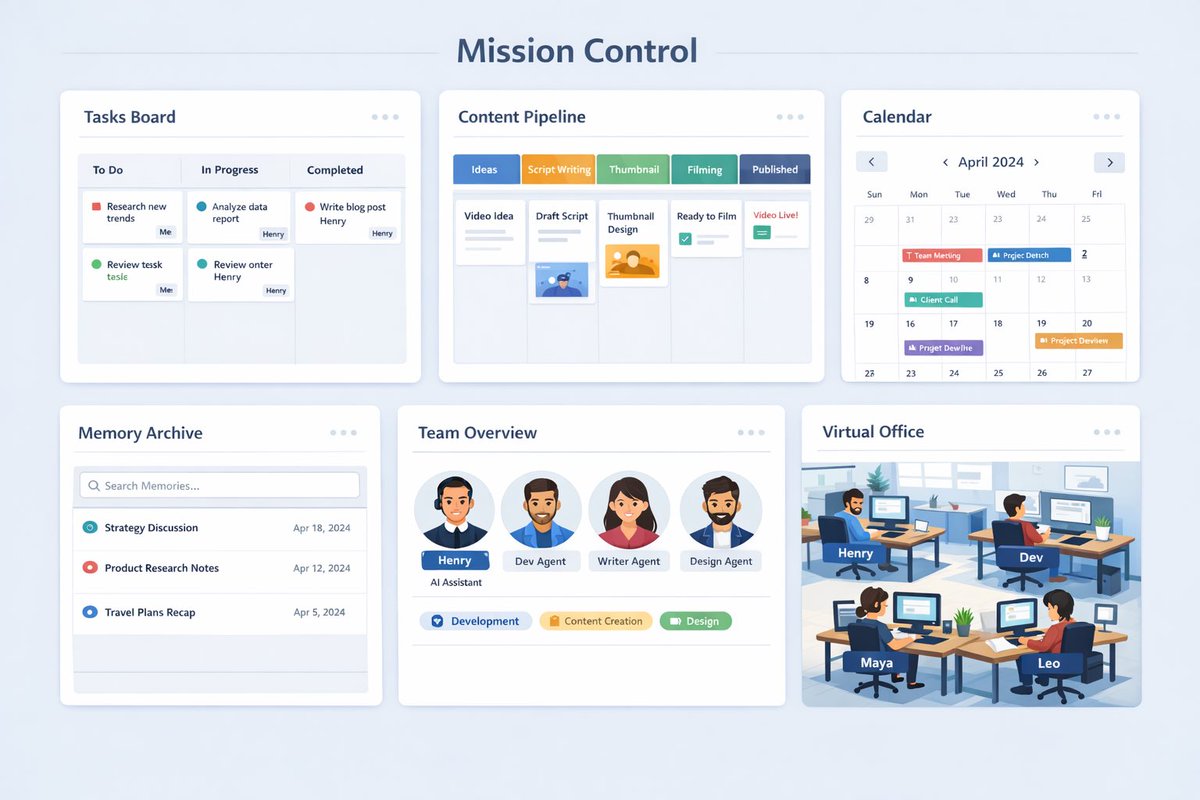
先搭一套「Mission Control」,看了一个博主分享、使用后效率立马提升十倍!Mission Control 本质是一套由 OpenClaw 自己长出来的专属控制台:
你能在同一个地方追踪它在做什么、把你的流程工具化、把记忆从藏在文件里升级为可检索的系统。越用越贴合你的工作流,而且不需要你手写代码、让 OpenClaw 生成即可。建议技术栈直接定死:Next.js + Convex(你在最开始就明确告诉它)!
//
1) Tasks Board|任务看板(让它开始“主动做事”)
用途:你和 OpenClaw 的工作都透明化,谁在做什么、做到哪一步、卡在哪里一眼看清;它也能看见你在忙什么,从而主动接走任务并更新状态。
指令(直接复制给 OpenClaw):
Please build a task board for us that tracks all the tasks we are working on. I should be able to see the status of every task and who the task is assigned to, me or you. Moving forward please put all tasks you work on into this board and update it in real time. Build it as a Next.js app with a Convex database.
2) Content Pipeline|内容流水线(把“分发”做成系统)
用途:把内容创作拆成流水线:Idea → Script → Thumbnail → Filming → Publish。你丢灵感,它每天固定时间把脚本写好、生成缩略图、把卡片推进到下一列,减少你“重复启动”的成本。
指令:
Please build me a content pipeline tool. I want it to have every stage of content creation in it. I should be able to edit ideas and put full scripts in it and attach images if need be. I want you to manage this pipeline with me and add wherever you can. Build it as a Next.js app with a Convex database.
3) Calendar|日历(验证它有没有真的排程)
用途:很多人觉得 Claw 不够主动,实际问题常常是“没有可见的排程”。日历就是你对它的 cron jobs / scheduled tasks 的审计面板:有没有排进来、什么时候跑、是否执行成功。
指令:
Please build a calendar for us in the mission control. All your scheduled tasks and cron jobs should live here. Anytime I have you schedule a task, put it in the calendar so I can ensure you are doing them correctly.
Build it as a Next.js app with a Convex database.
4) Memory|记忆库(把记忆变成可搜索资产)
用途:把它产生的每一条 memory 变成 UI 里的文档集合,并且做全局搜索。你不再靠想起来去翻文件,而是像查资料一样检索你们过去的决定、偏好、策略、上下文。
指令:
Please build a memory screen in our mission control. It should list all your memories in beautiful documents. We should also have a search component so I can quickly search through all our memories.
Build it as a Next.js app with a Convex database.
5) Team|团队结构(把 OpenClaw 当成公司在运营)
用途:你会反复用到开发 / 写作 / 设计 / 研究等不同能力,Team 页面把这些常用 sub-agents 固化成组织结构:角色、职责、正在做的事、对应的记忆与工具,方便管理,也能让它对“该叫谁出来做事”更确定。
指令:
Please build me a team structure screen. It should show you, plus all the subagents you regularly spin up to do work. If you haven’t thought about which sub agents you spin up, please create them and organize them by roles and responsibilities. This should be developers, writers, and designers as examples.
Build it as a Next.js app with a Convex database.
6) Office|数字办公室(偏氛围,但能提升运营感)
用途:更像一个实时状态总览 + 组织效率仪表板。用头像/工位展示每个 agent 的当前状态与任务进度;谁空闲、谁卡住、谁在跑流程,一眼可见,也更有在带团队的感觉。
指令:
Please build me a digital office screen where I can view each agent working. They should be represented by individual avatars and have their own work areas and computers. When they are working they should be at their computer. I should be able to quickly view the status of every team member.
Build it as a Next.js app with a Convex database.
建议:先把 Tasks Board + Calendar + Memory 做出来,你会立刻感觉到它从对话助手变成可运营的系统。后面再按你的工作流一点点加组件,Mission Control 会越用越像你自己的 AI 控制台。
中文
HenyJone STEM retweetledi

HenyJone STEM retweetledi

太精辟了
Susan STEM@feltanimalworld
人工智能的认知皮层 至此,我们已经从整体结构上解构了大语言模型 Transformer 的单层模块,它也常被类比为“人工智能的认知皮层”。在 Transformer 架构中,每一层 Layer 并不只是一个简单的神经网络运算单位,而是一个结构化的信息处理模块,仿照人类大脑皮层的处理方式,将输入的语言信息逐步抽象、压缩、选择,并生成更高层次、更符合语义逻辑的表达。 一个标准的 Transformer 层通常包含三个核心组成部分。第一是多头自注意力机制(Multi-Head Self-Attention),它允许每个 token 不只是理解自己,还能同时“看到”句子中其他所有 token,并以不同的角度去判断哪些信息在当前语境中最为重要。注意力机制的“多头”结构则让模型在多个语义空间中并行提取关联特征。第二部分是前馈神经网络(Feed-Forward Network, FFN),它对每个 token 的表示向量单独进行处理:先升维以拓展语义表示空间,再通过非线性激活函数选择有意义的特征,最后再降维回原始维度,以完成一次局部语义的加工。第三部分是残差连接与层归一化(Residual Connection + LayerNorm),它们共同保证信息的稳定传递:残差连接允许模型保留原始信息而不被新一层完全覆盖,而归一化机制则避免激活值在层间传递中失衡,有助于稳定训练过程。 x.com/feltanimalworl… x.com/feltanimalworl… x.com/feltanimalworl… 这个结构可以被简化成一个逻辑流程图:输入向量首先进入多头注意力模块,然后加上残差并做一次归一化处理;接着传入前馈神经网络,再次残差连接并归一化。最终输出的新向量则会成为下一层的输入。这样的模块并不是独立存在的,而是作为整个模型的基础单元被一层层堆叠起来。以 GPT 模型为例,GPT-2 包含 12 至 24 层,GPT-3 增至 96 层,而 GPT-4 被推测可能超过 100 层;BERT-base 有 12 层,BERT-large 有 24 层。每一层都拥有相同的结构,但参数独立、语义功能递进。就像人脑皮层中不同区域处理不同层级的信息,每一层 Transformer 都负责更进一步的语义抽象。 从认知结构的角度来看,Transformer 的每一层可以类比为一个“人工皮层单元”,具备类神经系统的三个核心功能:感知、加工、整合。感知机制由多头注意力实现,相当于模型的“感官”;加工机制由 FFN 执行,完成特征提取与语义变化;整合机制则通过残差连接与归一化,把旧的信息结构与新提取的语义进行融合,形成更稳定的表达方式。这使得每一层都具备了局部理解、结构压缩和语义统一的能力,是大模型内部的认知最小单位。 一句话总结:Transformer Layer 就是大型语言模型的大脑皮层。每一层都在进行一次“看懂 → 加工 → 整合”的语义演化过程,最终通过数十乃至上百层的堆叠,构建出类人语言智能的神经系统。
中文


