LightMem-Ego: Your AI Memory for Everyday Life
A lightweight streaming multimodal memory system for smart glasses and smartphones that continuously captures egocentric visual and audio streams and organizes them into current, short-term, and long-term memory.
StudioRecon
Reconstructs dynamic 4D human scenes from just 4 low-overlap cameras by decoupling background and humans — video diffusion densifies the background, SMPL constrains the humans, and a recursive module harmonizes both.
Direct-OPD: Weak-to-Strong Generalization via Direct On-Policy Distillation
ByteDance Seed reuses RL exploration from a small model as a dense implicit reward. Boosts Qwen3-1.7B by +10 points on AIME24 in just 4 hours on 8 A100s.
NVIDIA just released the Nemotron-3 Embed model on Hugging Face
State-of-the-art multilingual text embedding with 8B parameters,
supporting 34 languages for retrieval and semantic search.
Alibaba's ABot-N1
A visual language navigation foundation model that decouples cognition from control, achieving a 35% gain in POI arrival to 77.3% and 95.4%/92.9% SR in complex indoor and outdoor scenes.
ABot-AgentOS
A general robotic Agent Operating System that provides scene-conditioned planning, context-isolated skill execution, multi-modal memory, and self-evolution for long-horizon embodied tasks.
ReChannel
A new way to extract depth, normals, matting, and segmentation from a single image using a frozen text-to-image DiT — with only 33K trainable parameters per task.
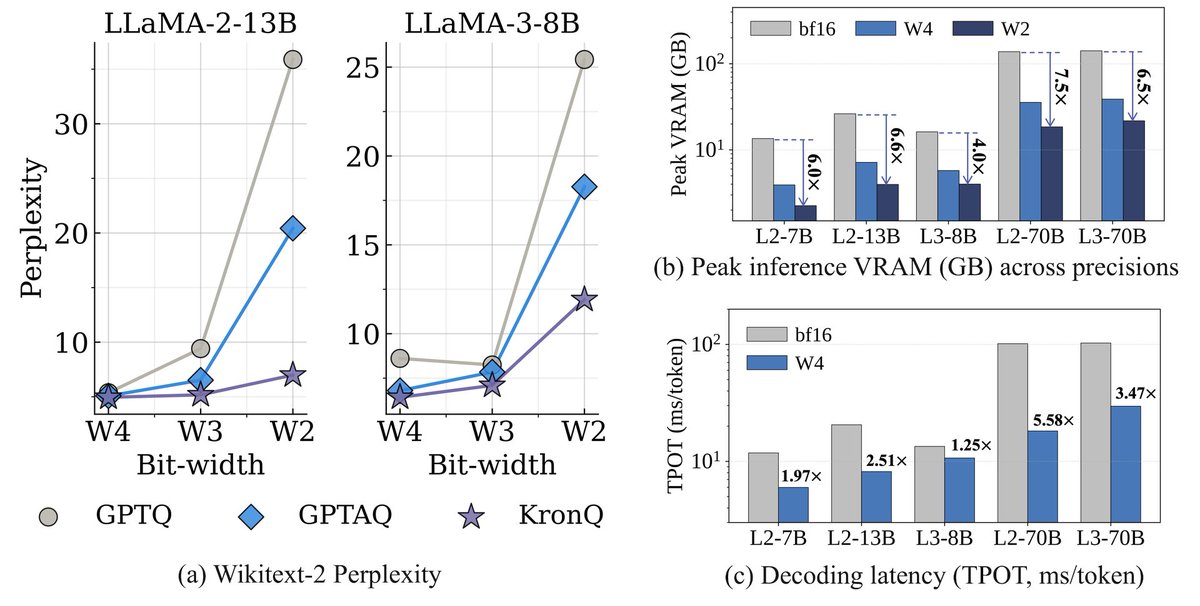
KronQ
A new post-training quantization framework that introduces gradient covariance into the quantization objective, achieving 7.93 perplexity on Llama-3-70B at 2-bit where GPTQ diverges
Trust Region Policy Distillation (TOP-D)
Transforms unstable on-policy distillation into a stable training paradigm by dynamically constructing a proximal teacher, improving sample efficiency and final performance at zero additional computational cost.
Scalable Visual Pretraining for Language Intelligence
Training language models directly on visual documents—figures, equations, layouts—outperforms text-only pretraining, challenging the default assumption that LMs need plain text.