Finisher🧪 retweetledi

Finisher🧪
758 posts


Kubernetes - In Plain English ☸️ - Pod → Smallest unit where your app runs - Deployment → Manages replicas & updates - StatefulSet → Stable identity + persistent storage - DaemonSet → One Pod on every node - Service → Stable internal access - Ingress → External HTTP/HTTPS access - ConfigMap → Non-sensitive configuration - Secret → Sensitive data - Node → Machine that runs Pods - Control Plane → Brain of the cluster - RBAC → Controls permissions - Namespace → Logical isolation Understand the building blocks → Kubernetes becomes simple.




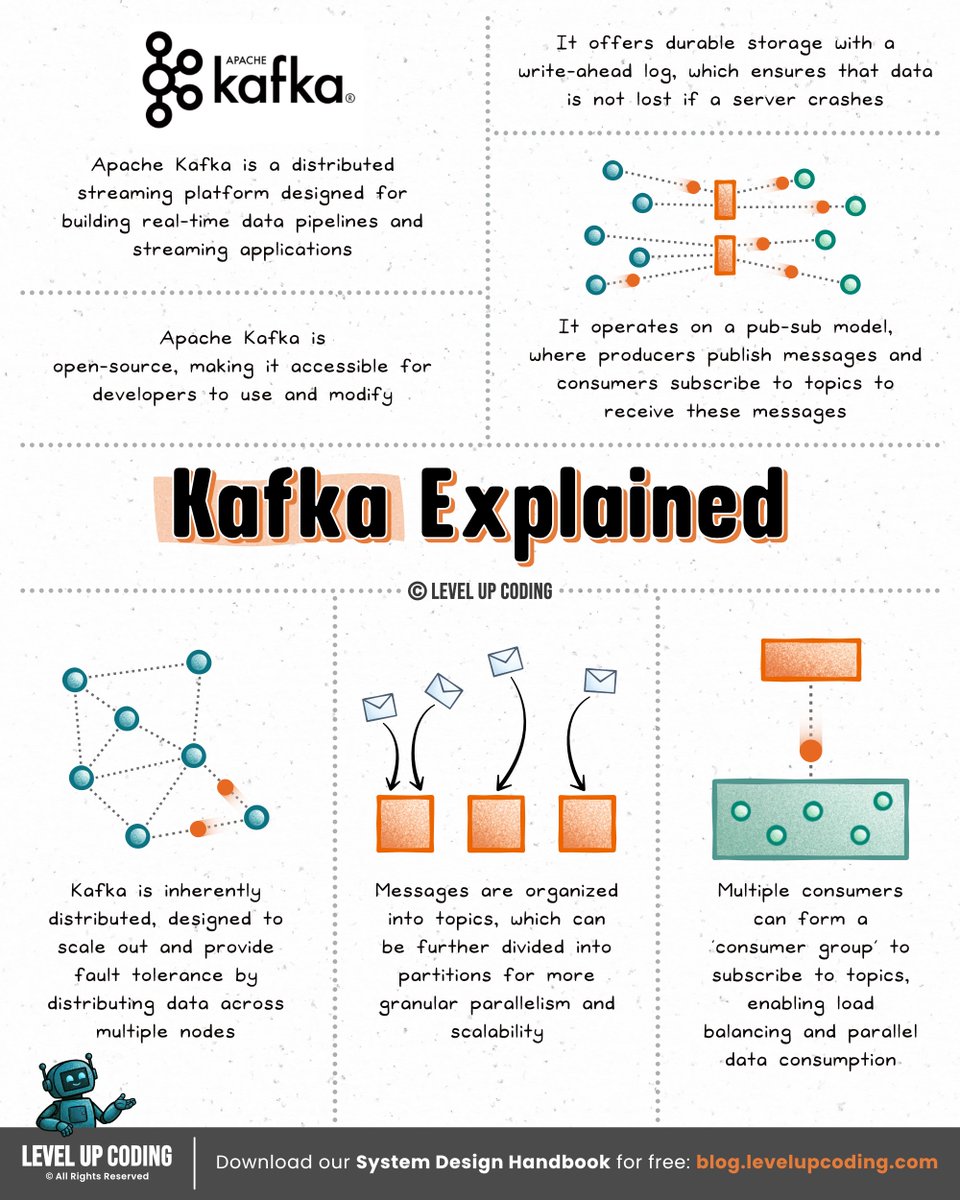
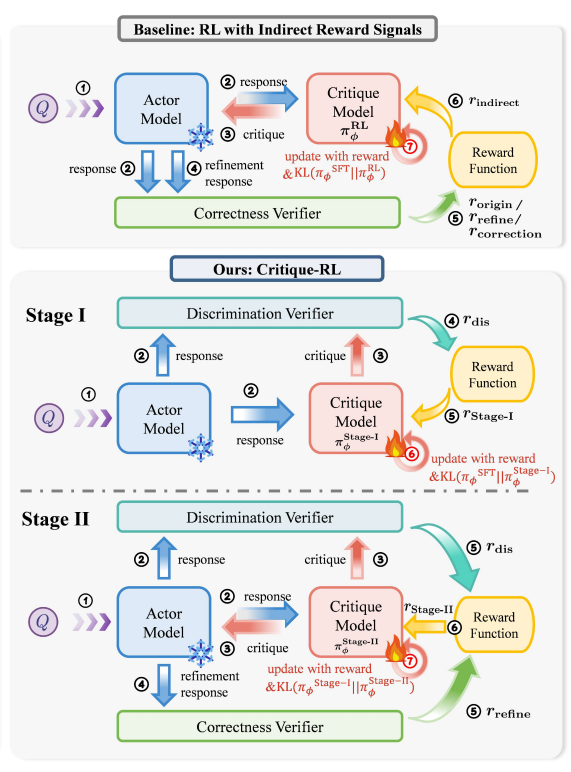
How Kafka works (clearly explained in under 2 mins): First, did you hear about the Aiven Free Tier Competition? They're providing prize money for the best project built using their free tiers (including Kafka, Postgres, and more). If you’ve been meaning to get hands-on with Kafka, this is a great way to do it. Check it out → lucode.co/aiven-free-tie… At its core, Kafka is a distributed commit log. It stores streams of events in append-only logs that multiple systems can read from independently. Here’s a simple mental model to understand it: 𝟭) 𝗣𝗿𝗼𝗱𝘂𝗰𝗲𝗿𝘀 𝘄𝗿𝗶𝘁𝗲 𝗲𝘃𝗲𝗻𝘁𝘀 ↳ Applications publish events like order_created to a topic 𝟮) 𝗧𝗼𝗽𝗶𝗰𝘀 𝗮𝗿𝗲 𝘀𝗽𝗹𝗶𝘁 𝗶𝗻𝘁𝗼 𝗽𝗮𝗿𝘁𝗶𝘁𝗶𝗼𝗻𝘀 ↳ Each partition is an ordered, append-only log ↳ Events are stored with sequential offsets 𝟯) 𝗕𝗿𝗼𝗸𝗲𝗿𝘀 𝘀𝘁𝗼𝗿𝗲 𝘁𝗵𝗲 𝗱𝗮𝘁𝗮 ↳ Kafka runs as a cluster of servers (brokers) ↳ Partitions are distributed across them for scalability 𝟰) 𝗖𝗼𝗻𝘀𝘂𝗺𝗲𝗿𝘀 𝗿𝗲𝗮𝗱 𝘁𝗵𝗲 𝘀𝘁𝗿𝗲𝗮𝗺 ↳ Services subscribe to topics and read events sequentially ↳ Consumer groups allow parallel processing at scale Two important design ideas make Kafka powerful: Decoupling → producers and consumers never talk directly Durability → events are stored on disk and replicated across brokers That’s why Kafka is often used as the event backbone for microservices, analytics pipelines, and real-time systems. What else would you add? —— ♻️ Repost to help engineers learn Kafka. 🙏 Thanks to @aiven_io for sponsoring this post. ➕ Follow me ( Nikki Siapno ) to improve at system design.



If you’re building modern AI applications, learn these concepts (resources included): I’ve been using MongoDB’s AI Learning Hub to sharpen how I think about AI systems. It stands out for covering both concepts and real implementation. 1. AI Stack ↳ lucode.co/ai-stack-z7xd 2. Vector Search ↳ lucode.co/vector-search-… 3. AI Data Strategy ↳ lucode.co/at-data-strate… 4. Data Ingestion for RAG Applications ↳ lucode.co/data-ingestion… 5. Evaluating RAG Application Results ↳ lucode.co/evaluating-rag… 6. Going from RAG to Agentic Systems ↳ lucode.co/rag-to-agentic… 7. Introduction to AI Agents ↳ lucode.co/ai-agents-intr… 8. Introduction to Agent Memory ↳ lucode.co/agent-memory-z… 9. Why Multi-Agent Systems Need Memory Engineering ↳ lucode.co/memory-enginee… Which concepts do you think don't get enough focus? —— ♻️ Repost to help others learn AI. 🙏 Thanks to @MongoDB for sponsoring this post.