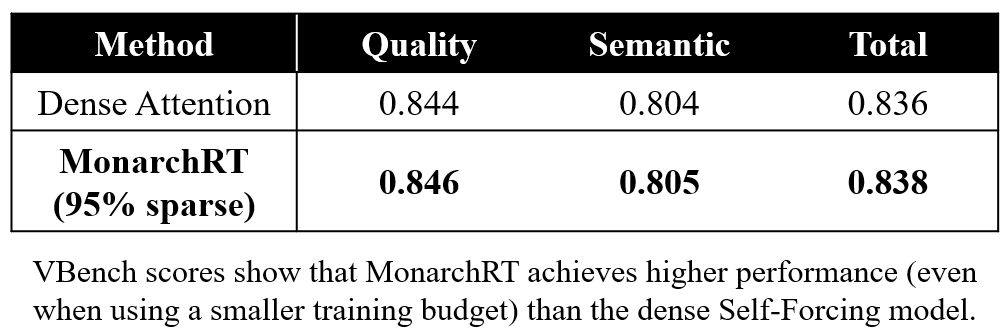
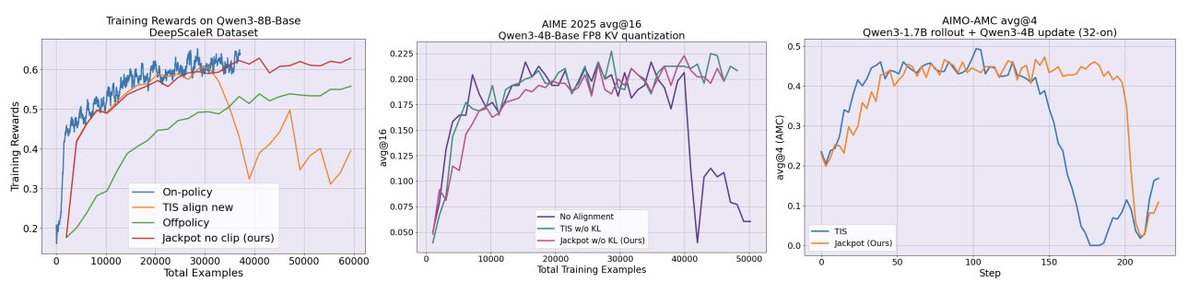
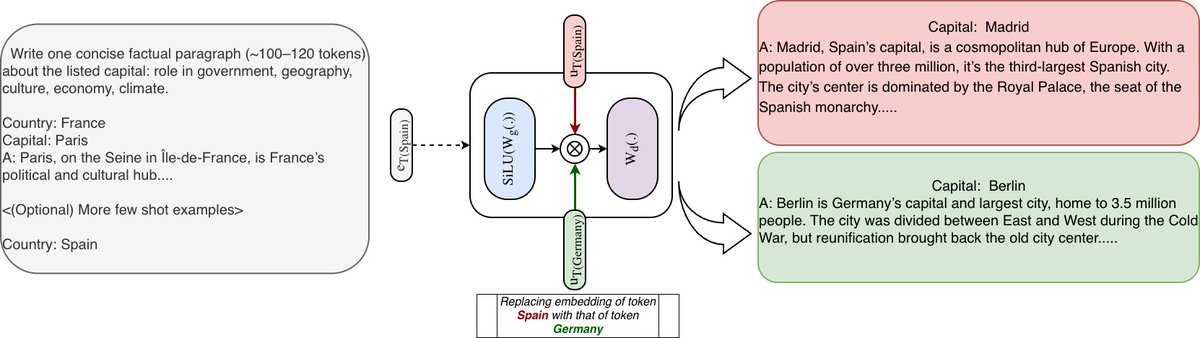
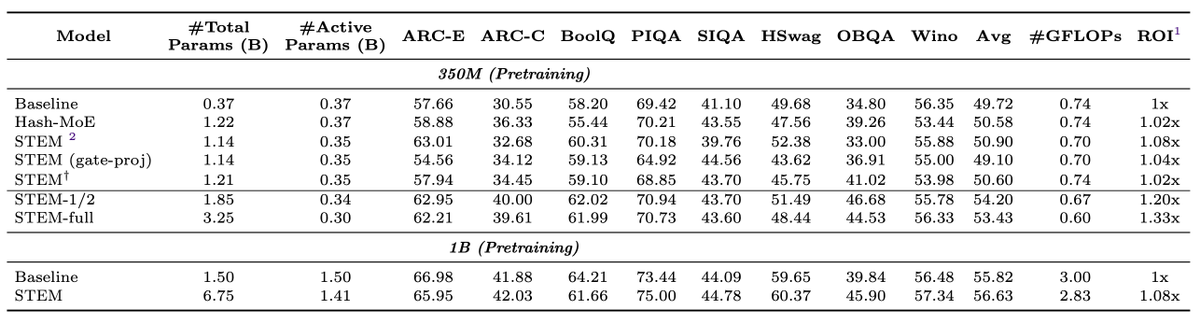
Joint work with @wonderingkrish, @chenzhuoming911, @ChengLuo_lc, @BrianChen112900, @haizhong_zheng, @xxunhuang, Atri Rudra, and @BeidiChen
We're grateful for the great work on MonarchAttention as well as concurrent work on VMonarch by @Kling_ai
English