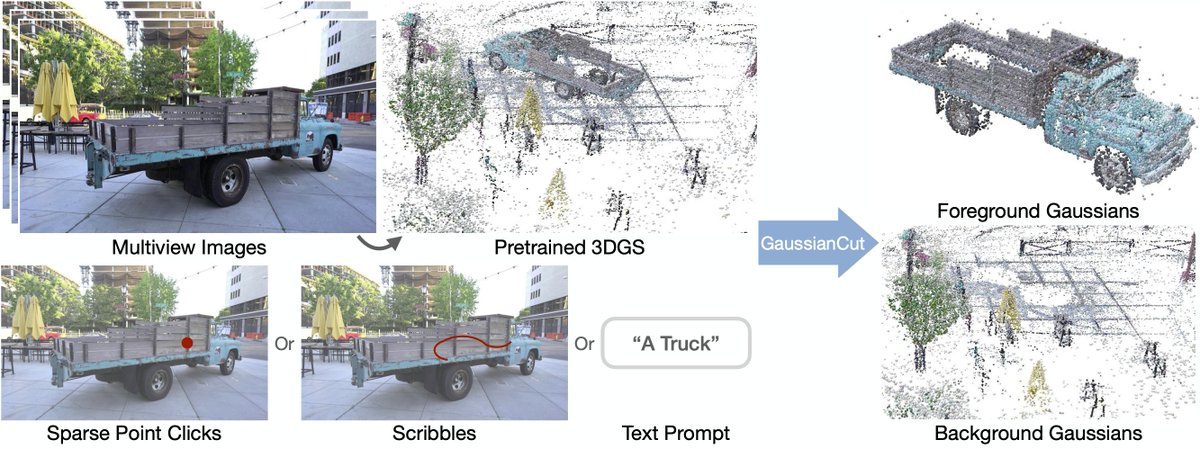
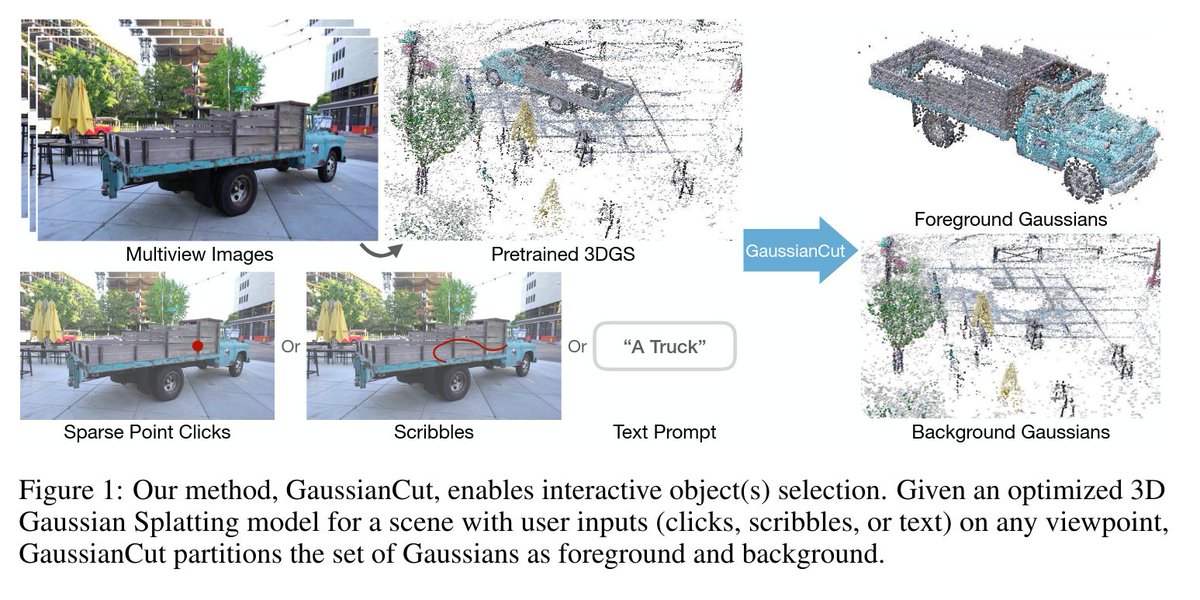
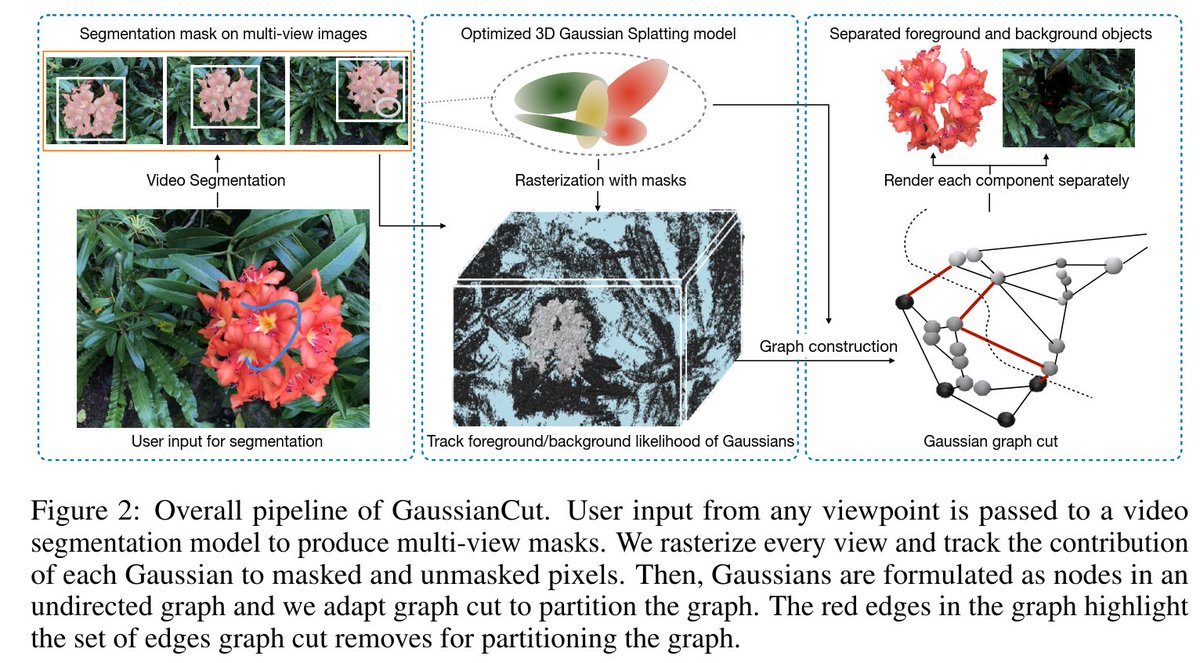
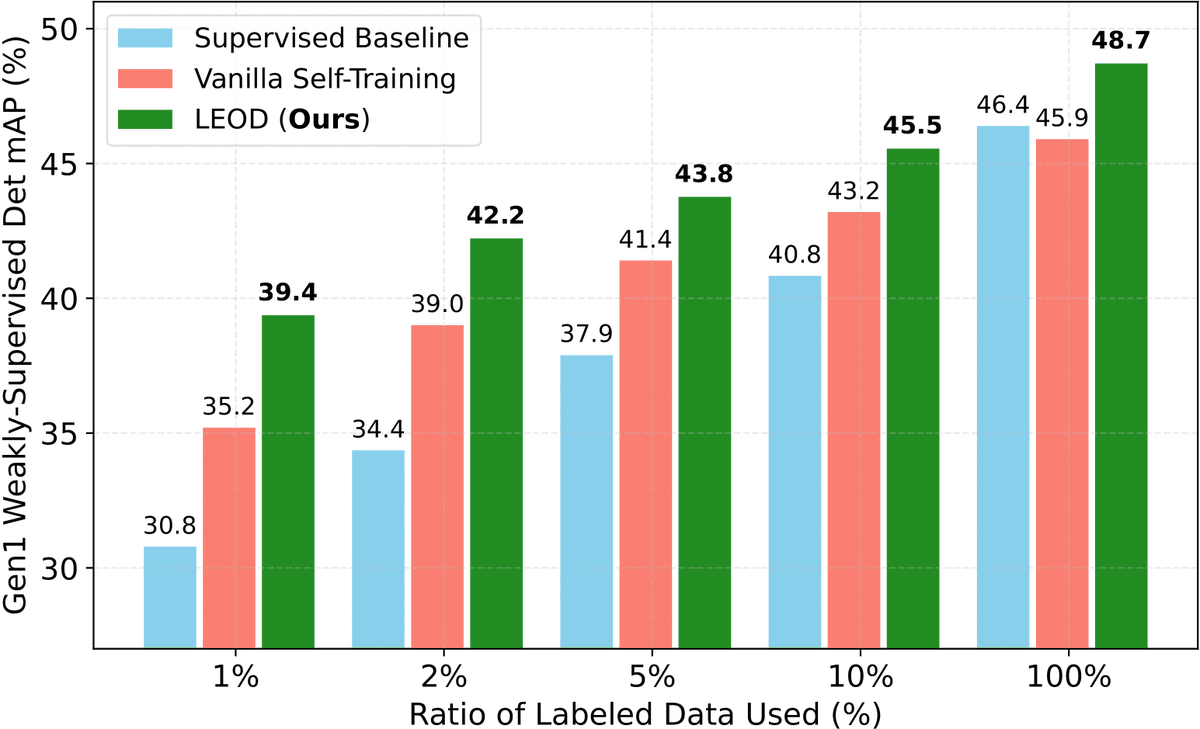
For evaluation, we create a 100-mesh benchmark with manually refined material groups.
Material Magic Wand outperforms geometry, vision foundation embeddings, and 3D part-feature baselines.
We hope this work enables faster material assignment workflows!
English