Jane Pan retweetledi

Jane Pan
27 posts

@JanePan_
CS PhD at @nyuniversity, @NSF GRFP, @Deepmind Fellowship, @SiebelScholars | @Princeton @Princeton_nlp '23 | @Columbia '21.

We have a new eval to help keep chains of thought (CoT) monitorable: CoT Controllability. This tests whether LLMs can control their CoT, helping to evade CoT monitors. So far, the results leave us cautiously optimistic: today’s models struggle to obfuscate their reasoning in ways that undermine monitorability.
if you truly believe in the bitter lesson, then why hand design scaling laws? introducing: neural neural scaling laws (NeuNeu), a neural network - trained on open-source LM trajectories - that predicts LMs' future downstream task performance 🧵👇


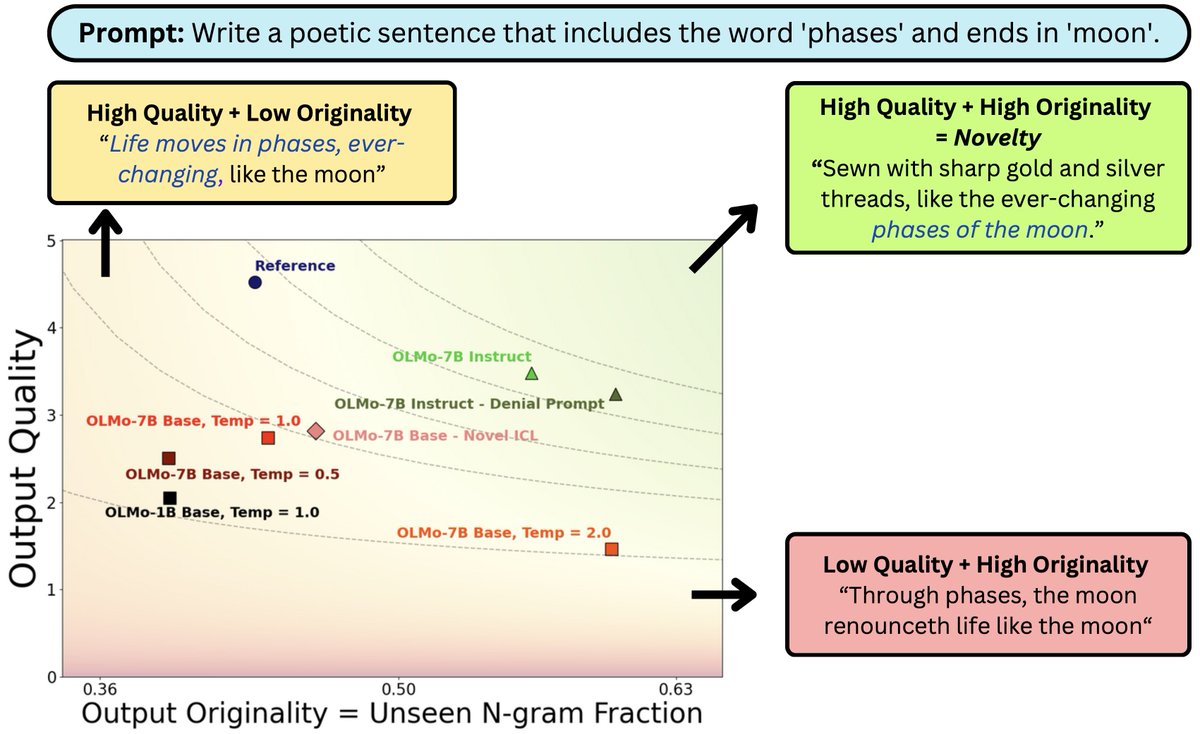
What does it mean for #LLM output to be novel? In work w/ @jcyhc_ai, @JanePan_, @valeriechen_, @hhexiy we argue it needs to be both original and high quality. While prompting tricks trade one for the other, better models (scaling/post-training) can shift the novelty frontier 🧵


I'll be at ACL Vienna 🇦🇹 next week presenting this work! If you're around, come say hi on Monday (7/28) from 18:00–19:30 in Hall 4/5. Would love to chat about code model benchmarks 🧠, simulating user interactions 🤝, and human-centered NLP in general!
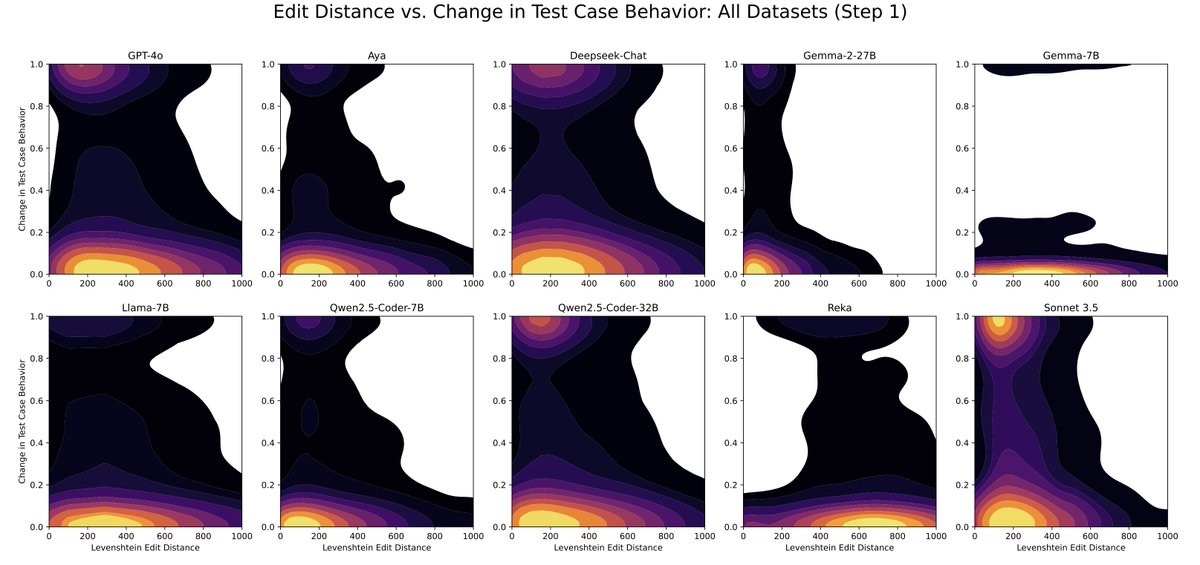
When benchmarks talk, do LLMs listen? Our new paper shows that evaluating that code LLMs with interactive feedback significantly affects model performance compared to standard static benchmarks! Work w/ @RyanShar01, @jacob_pfau, @atalwalkar, @hhexiy, and @valeriechen_! [1/6]

Reasoning models overthink, generating multiple answers during reasoning. Is it because they can’t tell which ones are right? No! We find while reasoning models encode strong correctness signals during chain-of-thought, they may not use them optimally. 🧵 below
Reasoning models overthink, generating multiple answers during reasoning. Is it because they can’t tell which ones are right? No! We find while reasoning models encode strong correctness signals during chain-of-thought, they may not use them optimally. 🧵 below