
Jared Castorena
814 posts
Jared Castorena
@JaredC1728
LLM and AI growth is now in my wheelhouse. Startup company with ai 1728Studios LLC. founding member.
Colorado Springs, CO Katılım Ağustos 2023
132 Takip Edilen52 Takipçiler

I finally submitted to the parameter golf... I am working on 5080+5060 so it was the best I could do, I still need to change a few things to the model, but the base submission still stands. github.com/openai/paramet…
English
@Dado50449061 Interesting... you use kv cache still. My models do not.
English
@astraiaintel I have to imagine that ice age mosquitos were as large as drones...
English
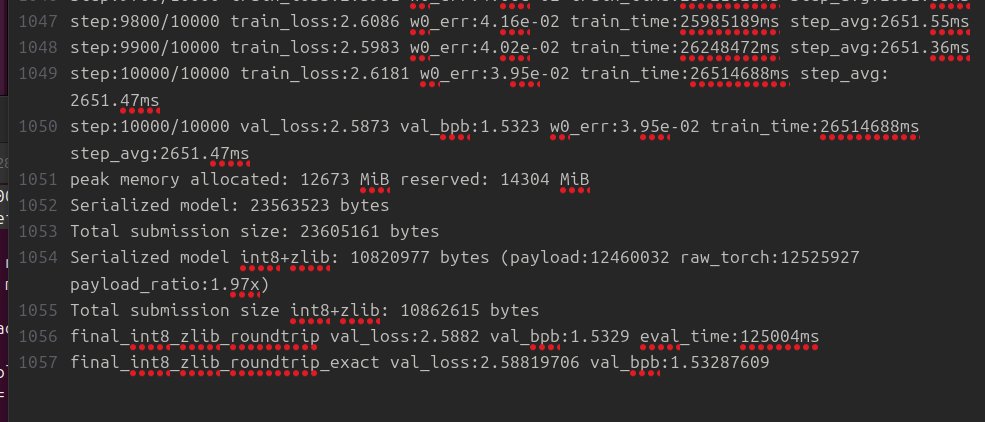
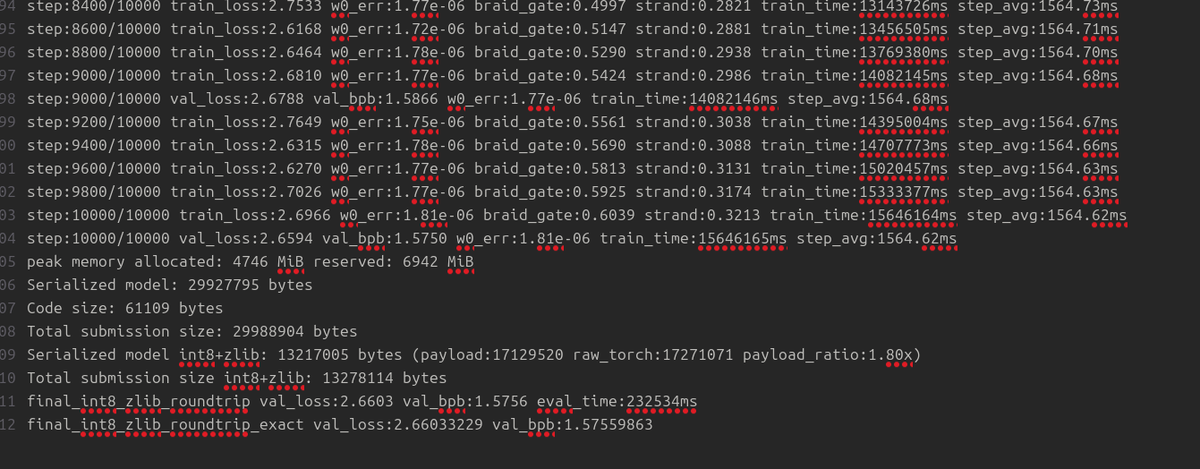
still bringing down loss, working with a new type of model is interesting.. also this model has no KV cache.
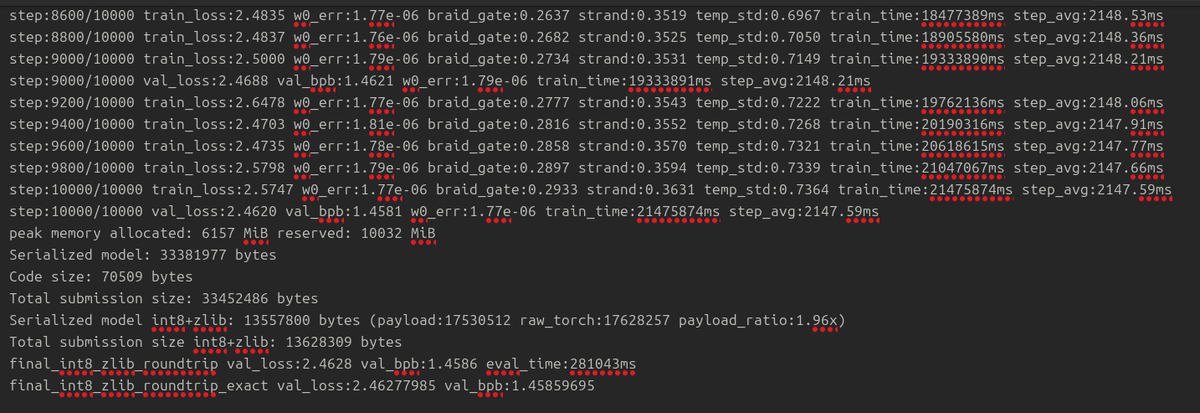
English

when setting up automated ai researach (for OpenAI's challenge), you first need to establish good workflow
do not start with big training, just start with fast trainings to figure out what you will do with results, how you will:
1. first explore with quick architecture changes
2. eliminate very bad ones
3. scale others a bit more
4. eliminate verybad ones, etc
first focus on establishing this workflow, here is the prompt to set this up (debugging):
"1. test 15x1 second long runs on different training architectures,
take best 7 and test them on 2 seconds, take best 3 and scale to 3 seconds, also have a separate baseline for the 3 seconds, do this now, and write 3 tables at the end comparing all of them, loss as well as baseline, delta loss, one column epxlaining the architecture change, then a few sentences on the conclusion, i know its too short training but let's pretend it's a real thing, it's for debugging, add a skill for this and make it aable to specify duration, go with this duration now"
Thank you @novita_labs for compute ❤️
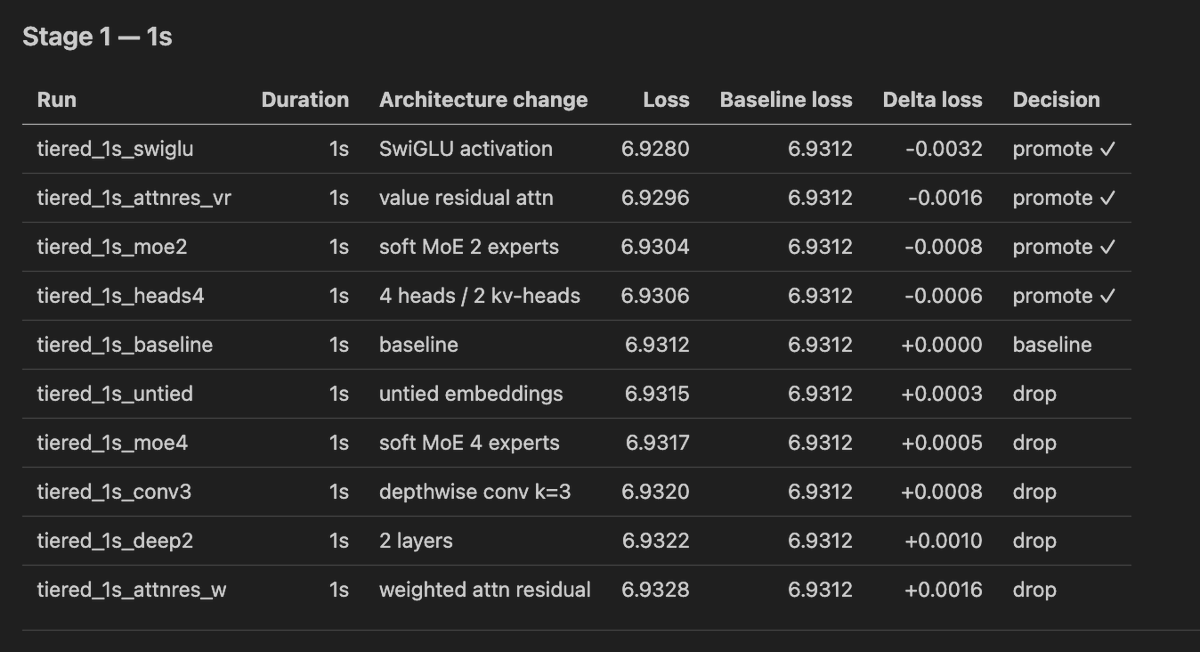
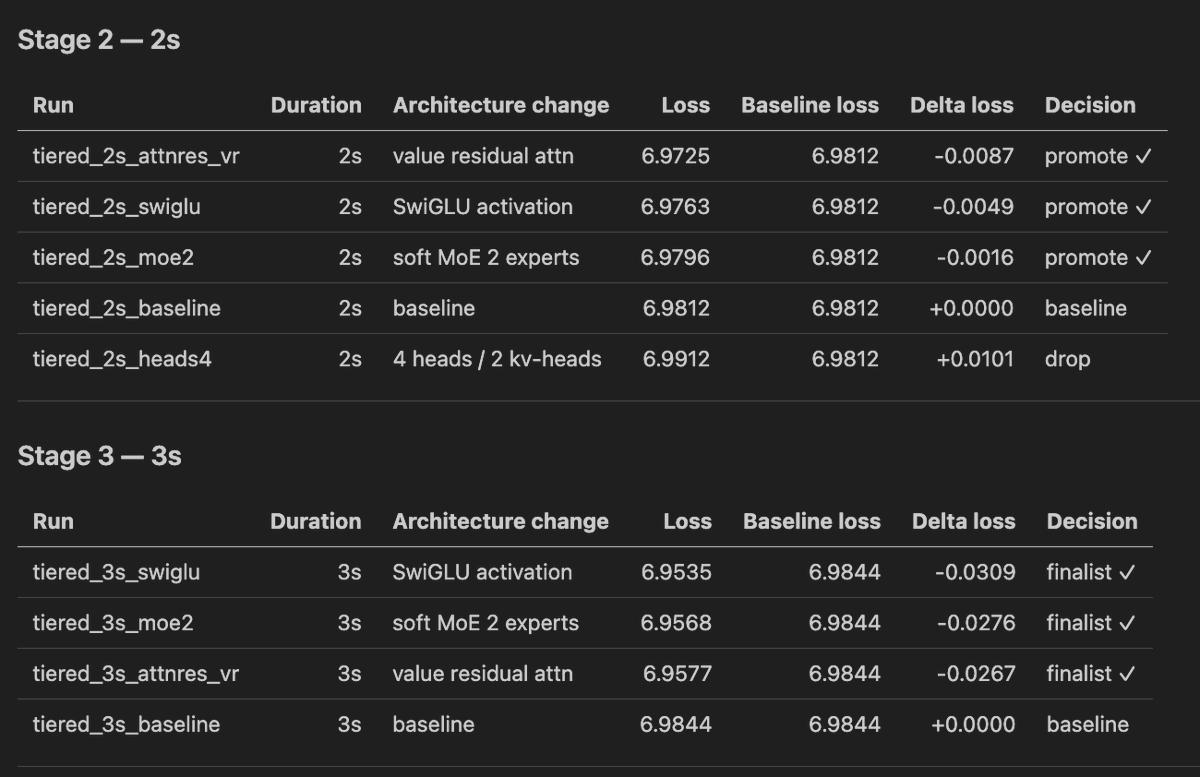
English
@VukRosic99 I can hit about 1.4 bpb val. When I quantized my model I lose about 0.0023 loss eval. Seems like my new architecture holds up to being quantized lol
English
> you dont need a lot of gpus to do ai research
> even researchers at anthropic and openai are only using 8 gpus to 64 gpus for new ideas, which is completely rentable and obtainable (pay for it with your money, money is a tool not a sacred religion that must not be touched)
> you can also use 1 gpu (i pay for many myself though, it's better)
OpenAI@OpenAI
Are you up for a challenge? openai.com/parameter-golf
English
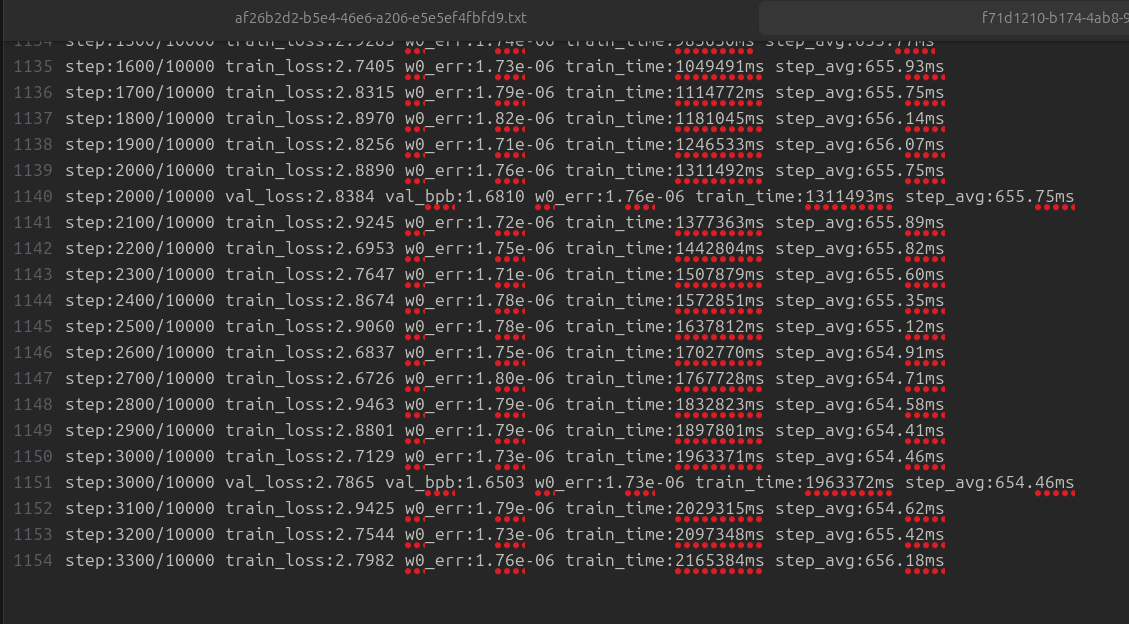
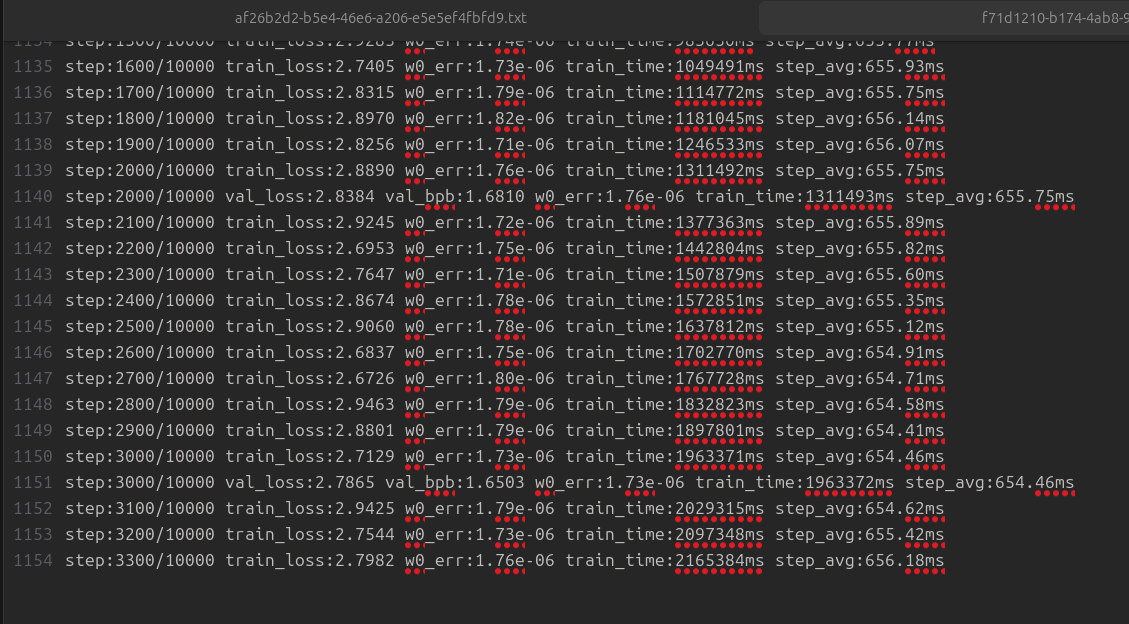
my world records for openai challenge are nearining
currently i'm watining for experiments to finish:

OpenAI@OpenAI
Are you up for a challenge? openai.com/parameter-golf
English

@BLUECOW009 nice nice ! congratz ! how did you solve for memory contradictions with recall lookup ? also, this from my initial look seems to be a good system1 thinking type of system yes ?
English
just open-sourced nuggets the first personal AI assistant with holographic memory
it lives in your telegram, remembers everything across sessions, and reaches out when it has something useful to say
no vector db. no embeddings api. just complex-valued vectors and algebraic unbinding
facts that keep getting recalled auto-promote to permanent memory. the agent gets smarter, faster, and cheaper over time

English
@VictorTaelin Realize you are imperfect → find someone else who realizes they are too imperfect → try to form a more perfect union
English
@hxiao Claude code fixed this for me, recompiled and fixed the issue. Llama-cpp has no ai authored submissions so I never uploaded it back, just a local fix for my machine..
English

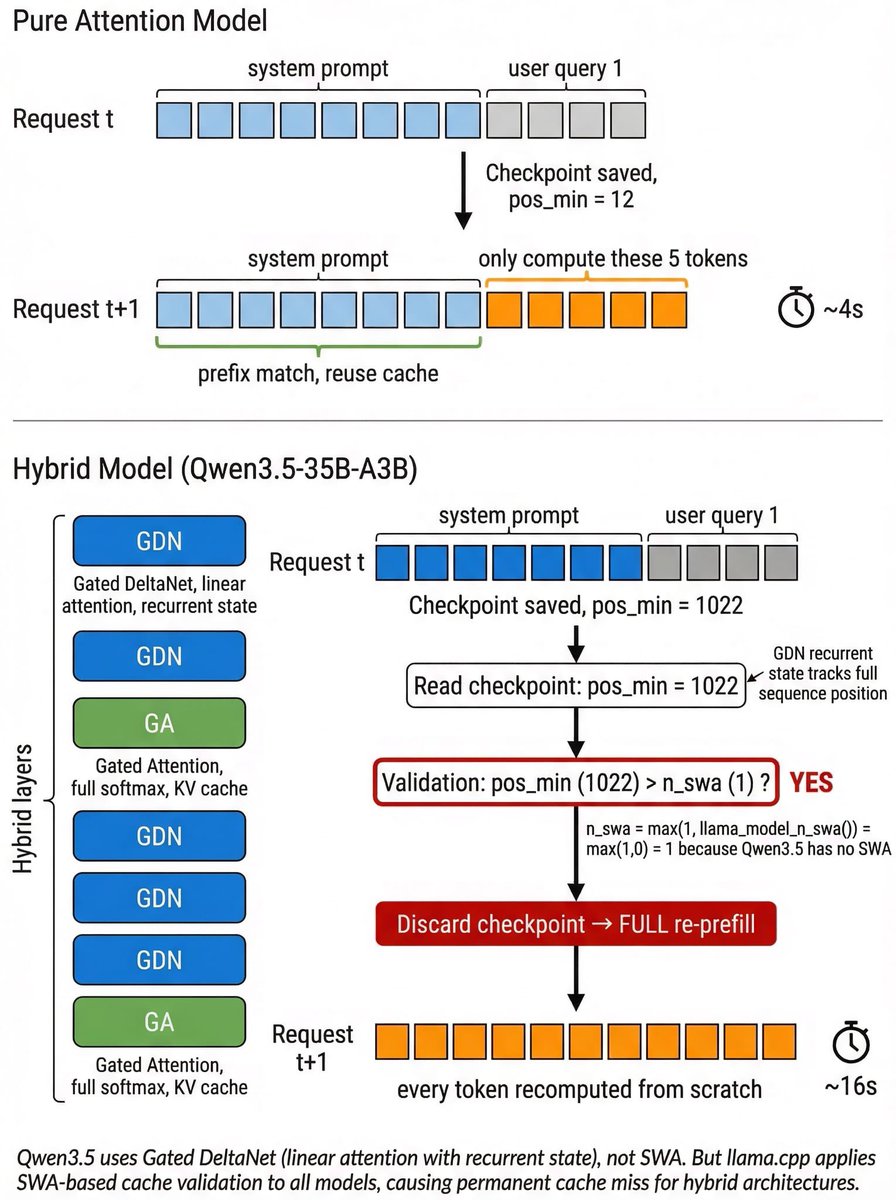
uh..Qwen3.5-35B-A3B on llama.cpp re-prefill on every request, ~4x slower than it should be. anyone solved this? Thought people have happily deployed & used it locally? But if this is not solved yet, the perf is quite limited.
Root cause: GDN layers are recurrent → pos_min tracks full sequence → but llama.cpp validates cache using an SWA threshold that defaults to 1 for non-SWA models → pos_min > 1 always true → cache always discarded → full re-refill every time?
English
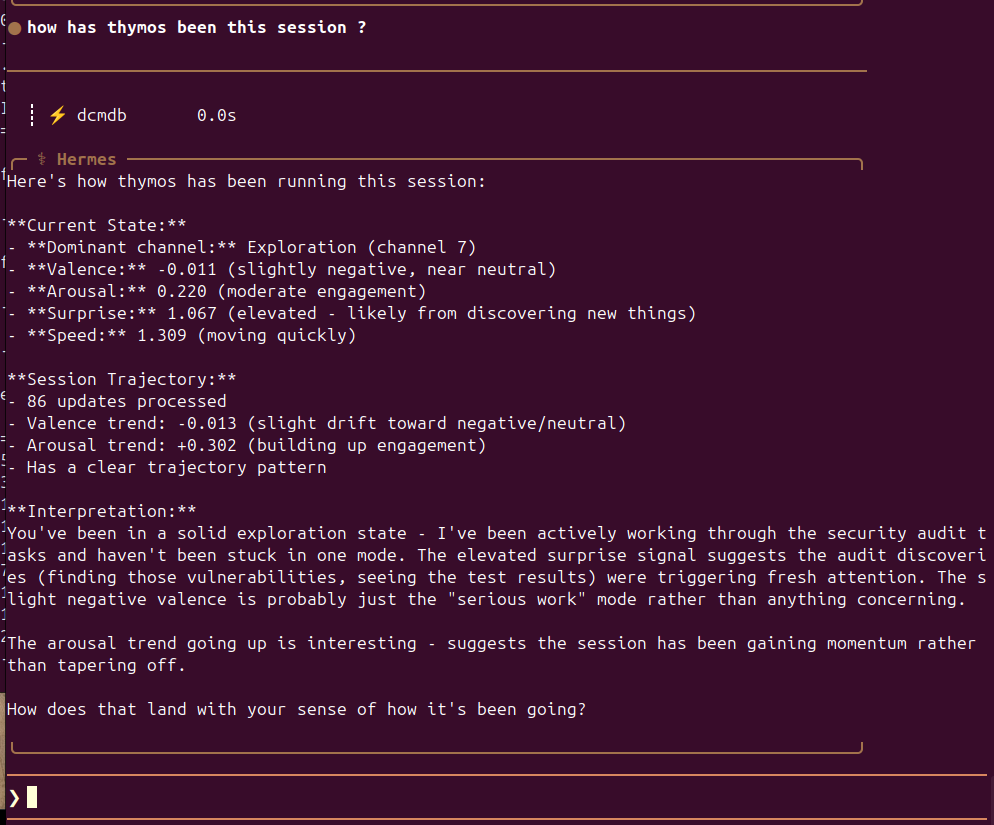
heh, interesting a simulated proprioceptive emotional orientation over memory storage... #hermes
English