Sabitlenmiş Tweet

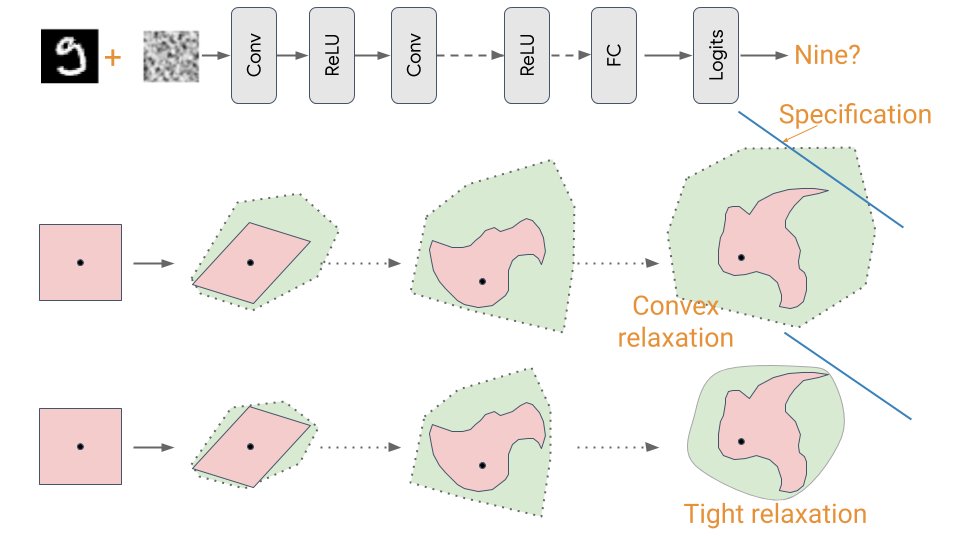
Deploying ML in high-stakes situations will require new evaluation techniques beyond static hold-out sets. It's exciting to share out views and recent progress on this problem from our team at DeepMind and so many others in the community.
Pushmeet Kohli@pushmeet
Over several decades, software engineers have developed a toolkit for debugging - from unit testing to formal verification. Our Robust & Verified AI team works on analogous approaches for ensuring that machine learning systems are robust at deployment: deepmind.com/blog/robust-an…
English