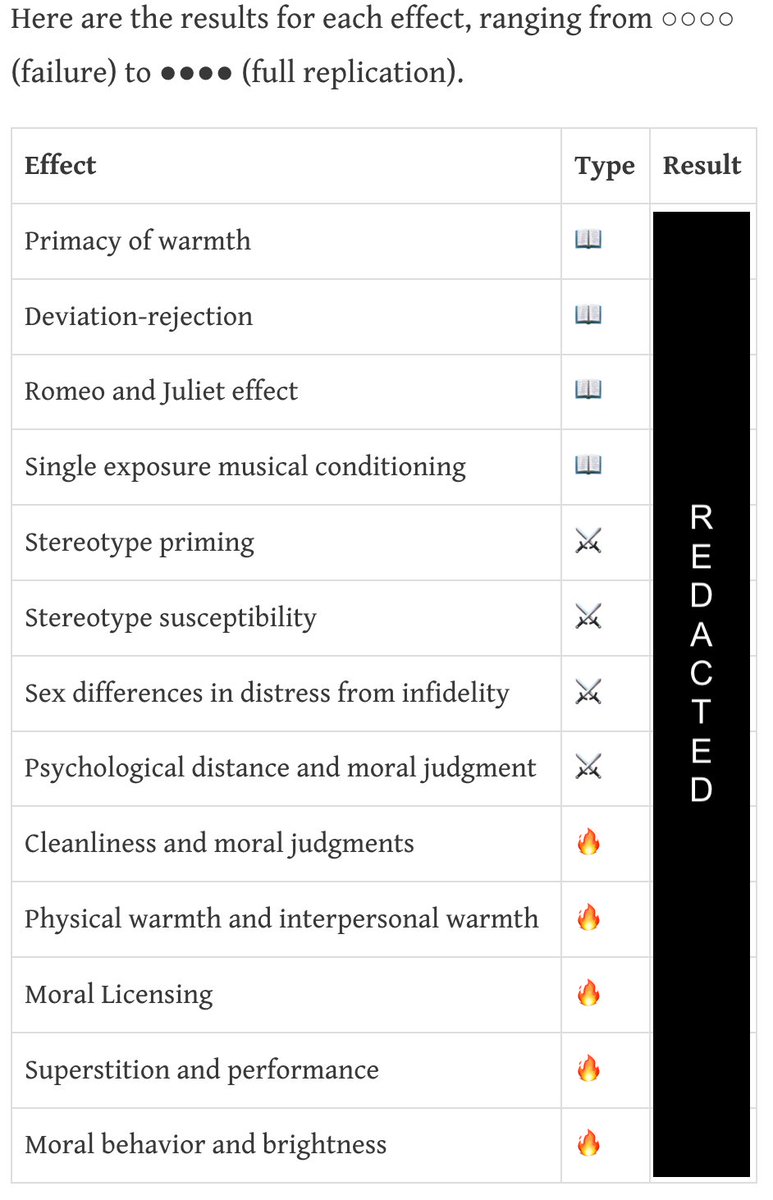
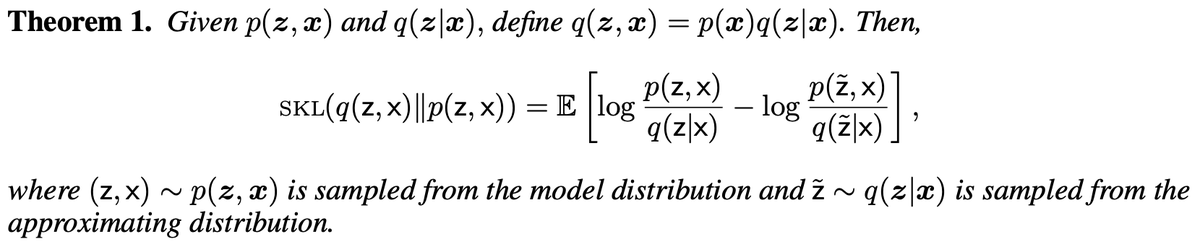@FelixHill84 I tend to think it's better not to do this before the rebuttal, as after the reviewers have converged it's even harder for the author response to change anyone's mind.
I didn't AC for Neurips this time, but when I did before we were encouraged to get reviewers to consult with the goal of reducing variance before rebuttal.
I found this to be a useful process that overall improved reviews (tho with some risks). Did anyone try this year?
@MaximeVono This is a very interesting paper, thanks. Have you thought about how you might apply such ideas with (non-instrumental) hierarchical models?
specifically designed for parallel/distributed Bayesian inference. We show non-asymptotic mixing time bounds in both Wasserstein and TV distances with explicit dependences on the dimension and regularity constants.
Our JMLR paper "Efficient MCMC Sampling with Dimension-Free Convergence Rate using ADMM-type Splitting" with D. Paulin and @ArnaudDoucet1 is now publicly available online: jmlr.org/papers/v23/20-… !
Based on an ADMM-type splitting, we build an approx. posterior (1/2)
@MassRMV Thanks, FYI the reason I can't do it online is because of your requirement to use that 2-factor authentication app, which I can't run on my phone. (Calling would be fine but as I'm sure you know the wait times are crazy these days.)
@JustinDomke The quickest and easiest way to change is online. If you are not able to call us to make the change, please mail the form to RMV, PO Box 55889, Boston, MA 02205.
@MassRMV Hi, I sent a change of address form by mail a month ago. I've triple checked that I used the right address (RMV- Address Change, PO Box 199106, Boston MA 02119-9106)
A month later this was returned to me as "No mail receptacle, unable to forward". What's the deal?
@JustinDomke@JustinDomke That is a form we no longer use and is not on our website. It appears some municipalities may still have that on their website. For RMV questions and assistance, please be sure to visit our website at Mass.Gov/RMV.
Hark, Bayesians! Everyone's favorite approximate inference symposium is back! The submission deadline is November 19th, so send us all your recent work on approximate Bayesian inference. Please share, retweet, and tell all your friends:
approximateinference.org/call/
@sethaxen This paper from 1995 shows that you can understand EM for gaussian mixtures as a kind of gradient update with a positive definite conditioning matrix. It suggests this improves convergence rates.
I'm sure regular gradient descent is usually fine, though!
dspace.mit.edu/bitstream/hand…
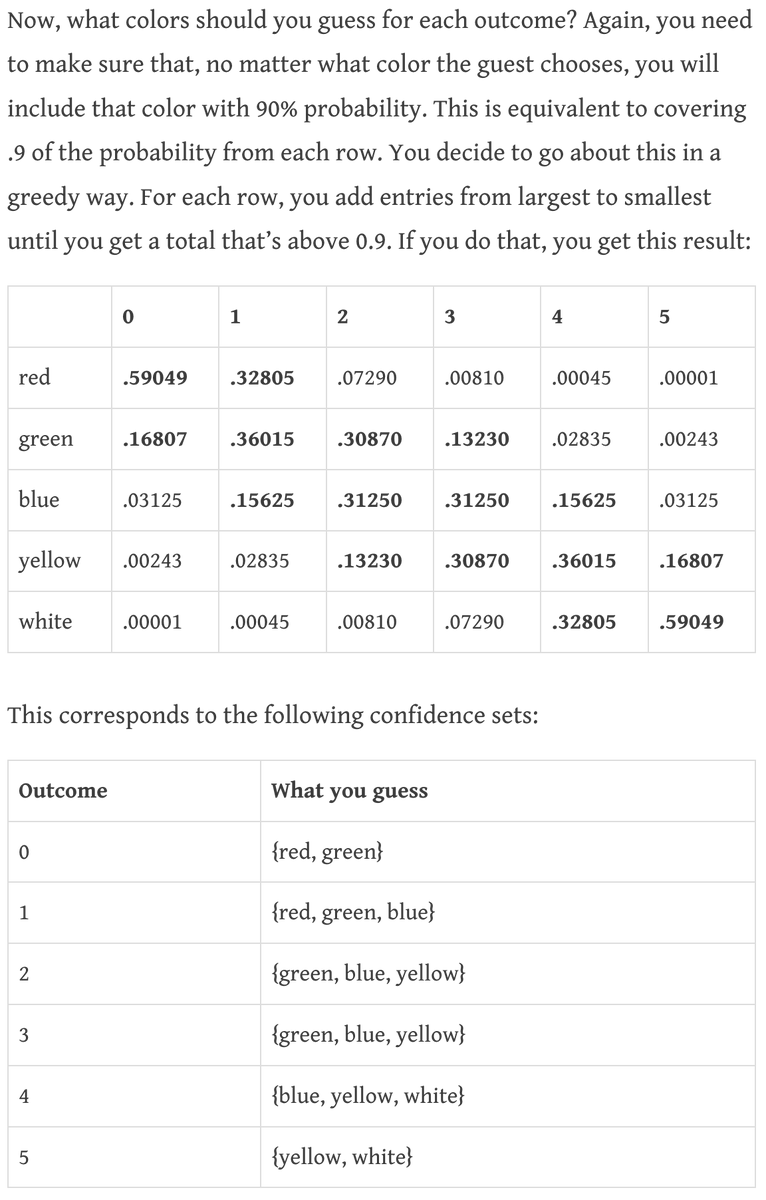
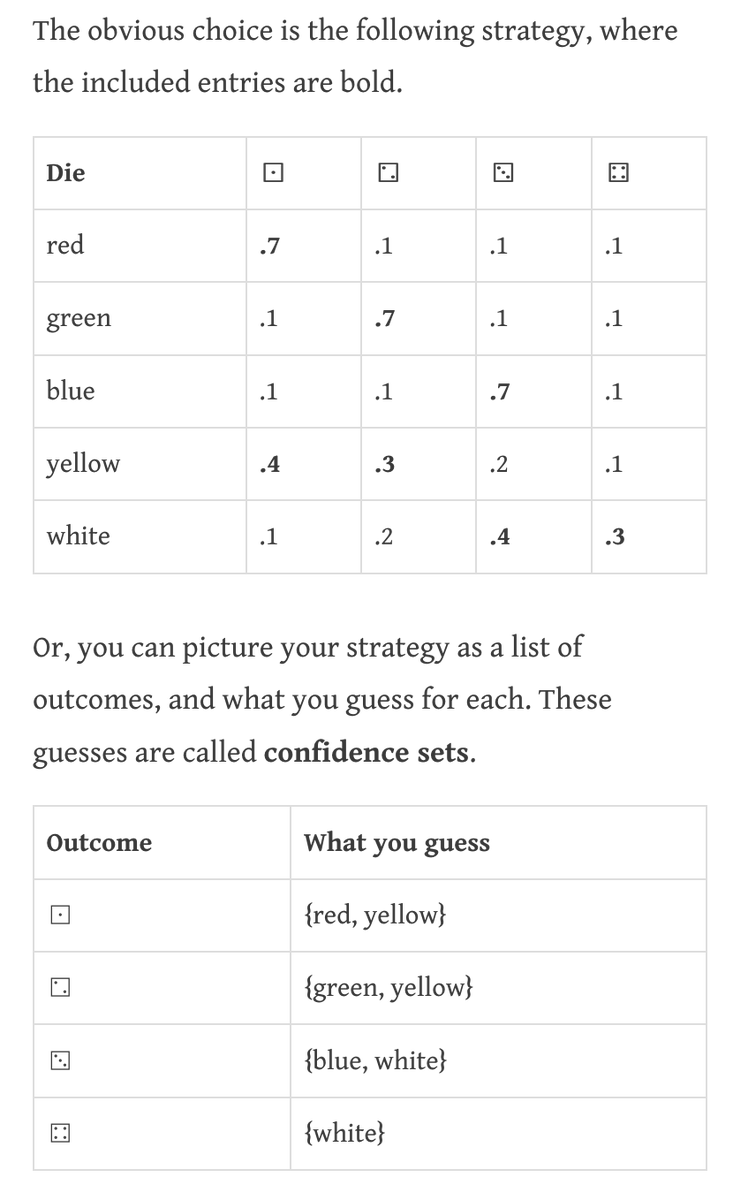
Turning confidence sets into confidence intervals.
(Or how you could accidentally invent the clopper-pearson interval without math using visualization and greedy choices.)
justindomke.wordpress.com/2021/10/13/mor…
@sam_power_825@Branchini97 Thanks! In defense of the bounding perspective, in cases where you just want to maximize a likelihood and don't care about the posterior, it is nice that you can just use Jensen's inequality and all the augmentations / couplings / etc. mostly just buys you "insight".
@Branchini97@JustinDomke It would be foolish of me to advocate against keeping an open mind 🙂 but I would say that for me, there have been a limited number of cases in which I preferred the bounds. Justin's work is indeed very nice (esp. with a background in Monte Carlo, extended state spaces, etc.).
It seems widely reported that "the VAE lower bound (LB) is a special case of the IWAE's with K=1".
But surely I can use K>1 samples with VAE - just get ∑log instead of log∑ (IWAE).
One is a (biased&consistent) estimator of log p(x) while the other estimates a *LB* to log p(x).
@sam_power_825 Thanks! The main limitations to watch out for are (1) the cost of doing inference repeatedly and (2) VI might make KL(q||p) low but still leave SKL(q||p) high. (I mention this in section 6.2)
i vaguely remember reading this earlier in the year, but somehow elected not to tweet about it - rectifying that now:
arxiv.org/abs/2103.01030
'An Easy to Interpret Diagnostic for Approximate Inference: Symmetric Divergence Over Simulations'
- Justin Domke
@CiccioneLorenzo@StanDehaene Yeah, the point about Deming regression is very nice. Your paper will be a good resource for anyone who wants to train themselves to do this kind of thing better. I may refer to it in a class I'm going to teach in a few months, so thanks again!
@JustinDomke@StanDehaene Thanks! We did not directly compare people accuracy to existing algorithms (hint for future study?). We just showed that people: 1) don't perform simple OLS but Deming; 2) extrapolate from non-linear trends; 3) are bad with accelerating functions (new study is coming about this!)
@CiccioneLorenzo@StanDehaene Thanks for the pointer. I particularly liked your experiment 4 with the tricky extrapolation problem. I can't figure out how people compare to algorithms in terms of accuracy though. (Maybe it's in the supplementary materials?)
@JustinDomke Great job! With @StanDehaene we tested human mental regression, finding it is sophisticated, but affected by a bias: instead of OLS, we minimize the orthogonal distance of the points to the fit, as in Deming regression. Here's the link to the publication: sciencedirect.com/science/articl…