
Kang3s
1.5K posts

Kang3s
@Kang3s
build OctWa ( https://t.co/vscIlsZ5Hb )
Katılım Aralık 2017
405 Takip Edilen125 Takipçiler

351,548,510.984 $OCT 35% of the supply has burn by @octra @octralabs team.
octra labs@octralabs
at epoch 729169, a consensus burn of 351,548,510.984 $OCT occurred based on the first proposal on the @octra network octrascan.io/tx.html?hash=2… this was done ahead of transition to mainnet beta and in preparation for external validator onboarding global info will update shortly
English
Kang3s retweetledi

validators willing to onboard to octra mainnet beta should keep a balance of 10K $oct
octra validators will perform a wide arrange of tasks, including computations on and storage of encrypted data
a separate article with node types and fees will be published ahead of onboarding
octra labs@octralabs
at epoch 729169, a consensus burn of 351,548,510.984 $OCT occurred based on the first proposal on the @octra network octrascan.io/tx.html?hash=2… this was done ahead of transition to mainnet beta and in preparation for external validator onboarding global info will update shortly
English
Kang3s retweetledi

at epoch 729169, a consensus burn of 351,548,510.984 $OCT occurred based on the first proposal on the @octra network
octrascan.io/tx.html?hash=2…
this was done ahead of transition to mainnet beta and in preparation for external validator onboarding
global info will update shortly

English
Kang3s retweetledi

English
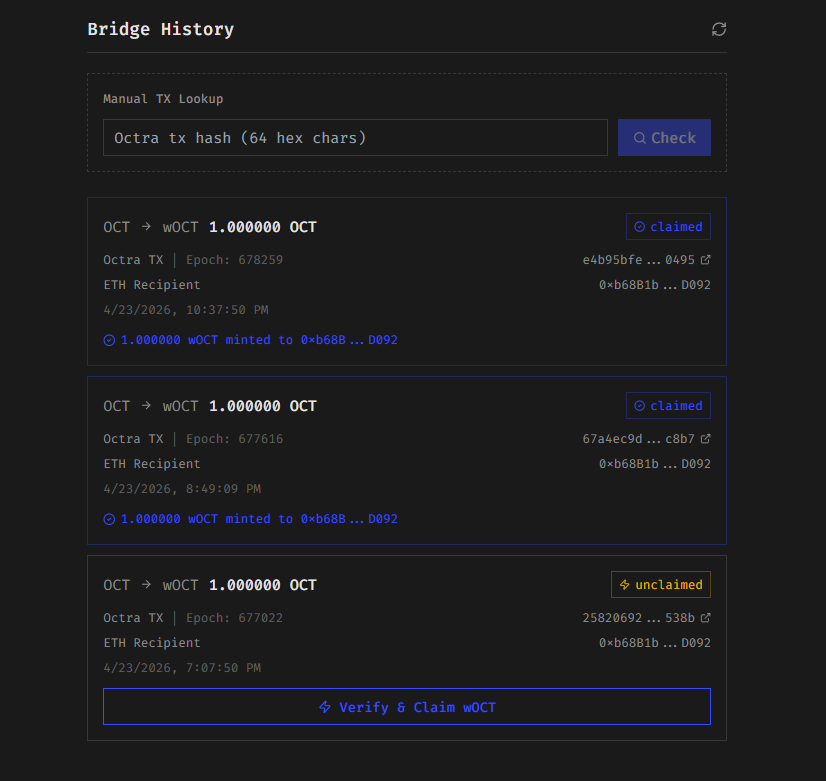
Just an Alt. No Need to Metamask Connection btw.
All in one Wallet.
EVM Asstes -> fund ETH -> Go bridge - That's its.
Bridge Source : github.com/m-tq/OctWa-Bri…
Live : bridge.octwa.pw
Wallet Source : github.com/m-tq/OctWa
Live : chromewebstore.google.com/detail/octwa-o…
English

Name the one #ticker you’re holding through the bears
English

Kang3s retweetledi

The most surreal thing to see as a founder (apart from the token price) is devs and projects actually building, deploying something, preparing serious specs, etc. You never get used to being taken seriously by people who are smarter than you, after years of building in stealth.

English

Kang3s retweetledi

the upcoming webcli update will include a wasm compiler (supporting Rust, C++, Zig, etc.), as well as the first spec and full syntax with the features of the internal octra lang @AppliedLang
λ@lambda0xE
the first octra program with fully public inference for SmolLM2-135M (training, weight loading, and state are fully public) currently, it's only for informational purposes, because the full cycle is expensive (4k OCT) since it performs about 1 billion FP64 arithmetic ops so, wait for an update of the webcli with an interface for interaction via a wrapper (will be available tomorrow) now you can look at the process of loading weights: octrascan.io/epoch.html?id=… (using this epoch as an example) example exec with resp: octrascan.io/tx.html?hash=a… * the program is verified and completely open
English
Kang3s retweetledi
Octra $OCT is now on
CoinMarketCap (supply updating):
coinmarketcap.com/currencies/oct…
Coingecko: coingecko.com/en/coins/octra
DEXScreener: dexscreener.com/ethereum/0x5eb…
Uniswap: app.uniswap.org/explore/tokens…
More soon!
English

Projekt który twoim zdaniem wszyscy ignorują, a nie powinni 👇
Polski
Kang3s retweetledi
Celestia as I understand it is limited to data availability (primary function). Octra explicitly doesn't have one and instead provides you with an isolated execution environment (subnet / Octra Circle) where you can deploy anything, including, theoretically, an LLM, an L2, a Celestia or a Chainlink. It is only an L1 technically because it has its own validator set and programmability, because, in turn, you cannot build FHE on top of existing chains today. However, it is envisioned to be fully integrated with them and act as encrypted middleware for any use case you may need elsewhere that includes persistent encrypted state.
Angelo@AngeloOnChain
Can someone more technically inclined tell me if this is the right way to think about @octra: its relationship to privacy is similar to Celestia and data availability? The L1 operates like any other, with $OCT as its native gas. However, any part of the stack in the chain and app infrastructure can opt to integrate using Octra to encrypt and compute said piece of the stack. Where am I wrong and what am I missing?
English
@jateen2310 Wait for the team’s announcement. You’ll need to take a few steps to claim it.
English



the first octra program with fully public inference for SmolLM2-135M (training, weight loading, and state are fully public)
currently, it's only for informational purposes, because the full cycle is expensive (4k OCT) since it performs about 1 billion FP64 arithmetic ops
so, wait for an update of the webcli with an interface for interaction via a wrapper (will be available tomorrow)
now you can look at the process of loading weights:
octrascan.io/epoch.html?id=… (using this epoch as an example)
example exec with resp: octrascan.io/tx.html?hash=a…
* the program is verified and completely open

London, England 🇬🇧 English