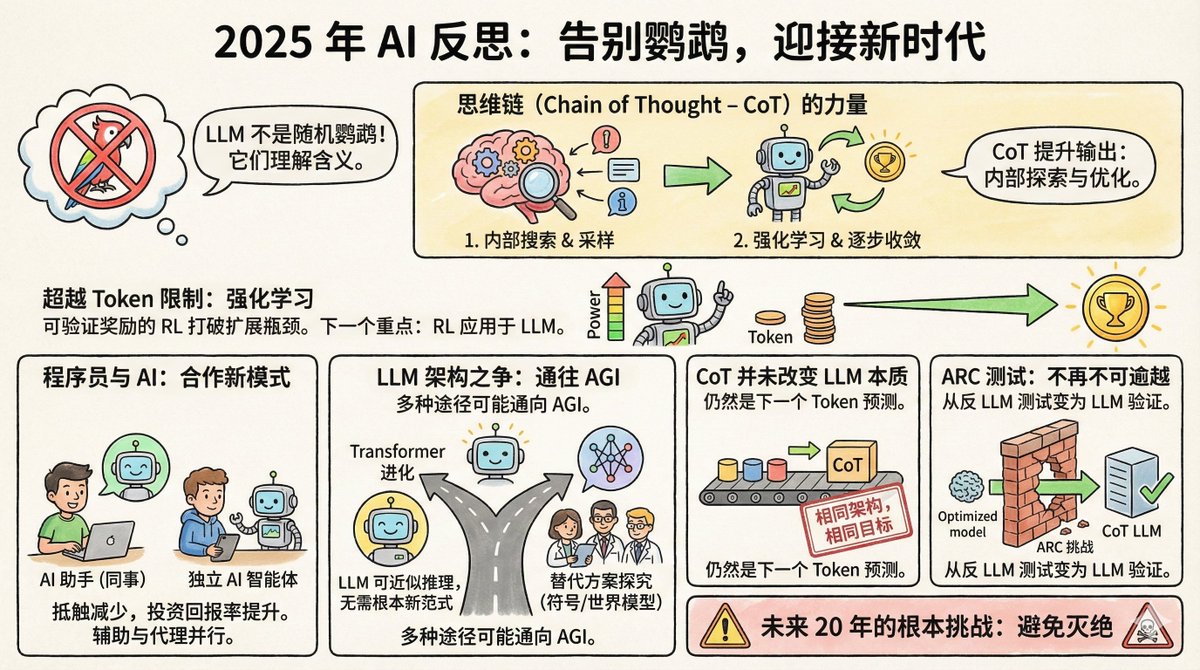
karajan retweetledi

如果你本來就是 ChatGPT 的使用者,就算不是程式開發者,也很推薦試試看 Codex。
延續之前提過的,我現在用 Codex 維護一個不用筆記軟體、純用 AI 管理的外部資料庫系統。最近我又讓它多做一件事:
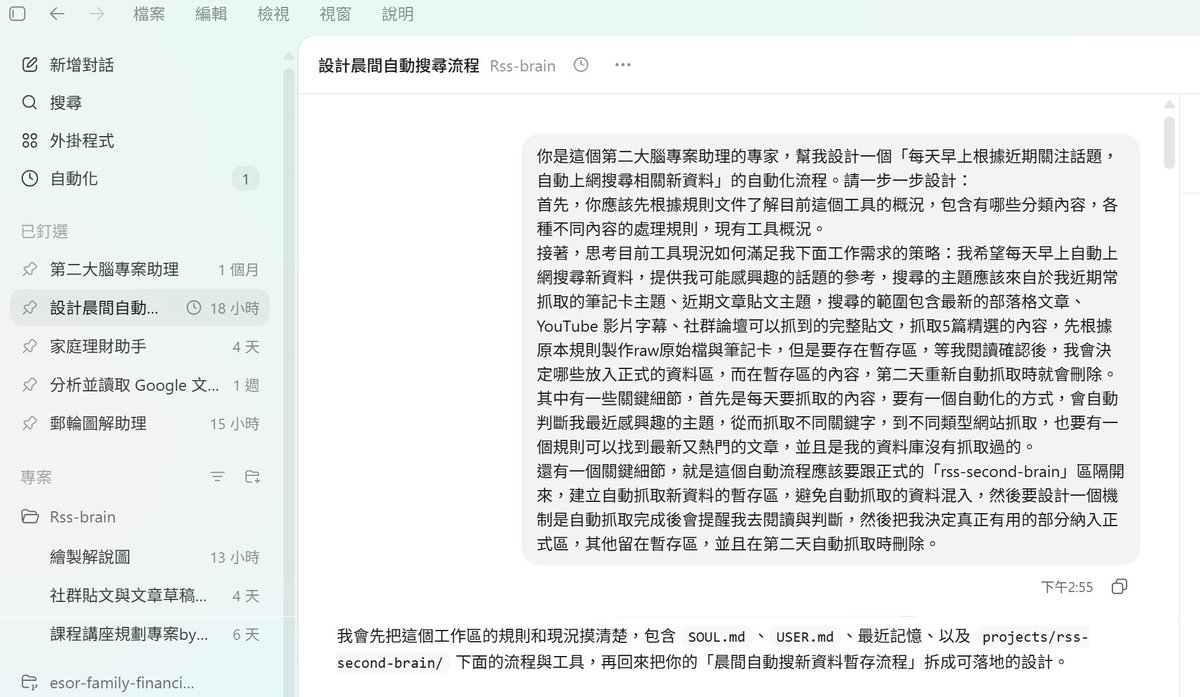
每天早上自動根據我最近關注的主題(外部資料庫中建立的新筆記、永久筆記),去 blog、YouTube、論壇抓固定數量的新資料,整理好原文、摘要,等我起床後直接看。
這一次連 RSS 閱讀器、稍後閱讀等工具都不需要另外去操作。如圖,一張是我一開始寫給 Codex 的需求,一張是它實際跑完之後,整理給我看的總覽大綱(另外還有每一篇的完整原文、摘要筆記)。
#以前如果要做到這件事,我大概要自己去操作筆記、 RSS、稍後閱讀軟體,研究自動化工具,想辦法把它們串起來。
但這次我做的事情其實很單純:就是在 Codex 中用一段對話,先把需求講清楚(如圖)。
我跟 AI 大概說明了下面幾個工作流程,例如:
搜尋主題要從我最近的筆記與貼文主題去推斷
來源要分成 blog、YouTube、論壇
每天抓固定數量的內容
先放暫存區,不要直接混進正式資料庫
我要先看 review summary,再決定哪些正式收錄
第二天自動抓新資料時,前一天沒收錄的暫存內容就清掉
剩下那些技術問題,像是怎麼分析我最近的筆記、怎麼設定搜尋主題、怎麼判斷對象與範圍,或是怎麼抓文章、字幕、討論串,以及怎麼整理成原文與摘要,幾乎都交給 Codex 自己去處理了(他會自己寫小工具,或是設定好流程自己用內建技能處理)。
用自然語言描述完我需要的工作流程,接著讓 AI 自己寫程式、跑測試,把整條自動化流程搭建起來。
如果是非工程師的用戶,也可以試試看,因為在這個案例中,真正的門檻不是會不會寫程式。而是練習把自己要的流程、邊界、例外和驗收條件講清楚。
以前我們常常是先學很多工具怎麼操作,才有辦法慢慢拼出一條流程。現在的 AI 工作時代則是:
#先把你要的流程說清楚,#再讓AI去幫你把工具和自動化搭起來。
如果你沒有程式背景,但本來就是 ChatGPT 使用者,我真的覺得可以試試看。
先下載 Codex ( chatgpt.com/zh-Hant/codex/ ),開一個新對話,指定一個新的資料夾給它,先從一條很小的流程開始就好。例如:
幫你整理每天固定追的資料
幫你做一份 review summary
幫你維護一個自己的 md 資料夾
我最近也把這套做法整理成一篇比較完整的文章,歡迎參考:
AI 結合卡片盒筆記法,人不再操作軟體,用對話流程讓 Codex 搭建資料整理系統:我的兩個月實測心得playpcesor.com/2026/04/ai-cod…
#ChatGPT #Codex #AI工作流 #第二大腦

中文