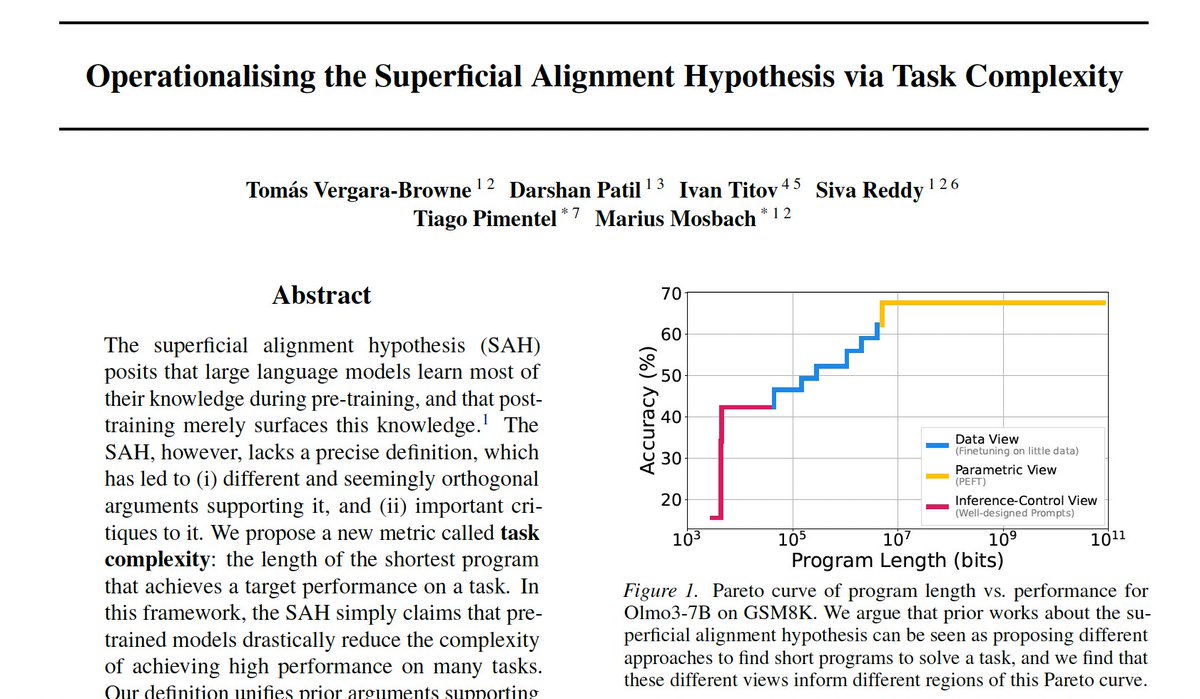
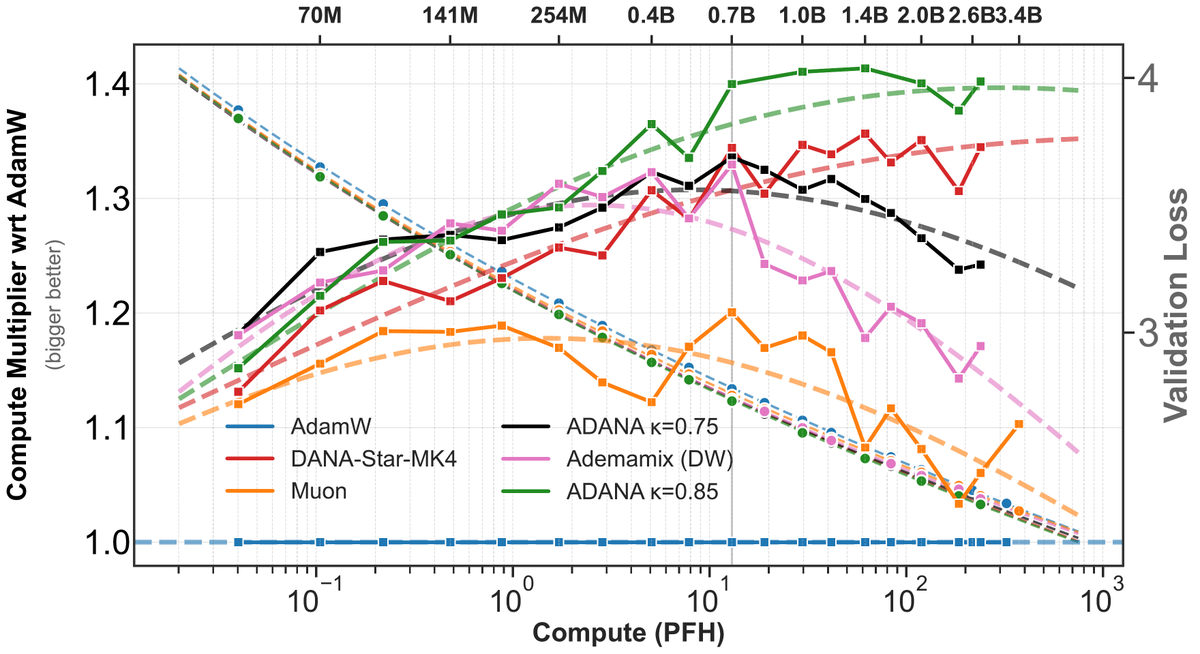
Sabitlenmiş Tweet

Our new paper got #ACL2025 oral! 🎉
If you're interested in LLM training dynamics, its phases, and how scaling affects them — check it out!
@Mila_Quebec
x.com/mirandrom/stat…
Andrei Mircea@mirandrom
Step 1: Understand how scaling improves LLMs. Step 2: Directly target underlying mechanism. Step 3: Improve LLMs independent of scale. Profit. In our ACL 2025 paper we look at Step 1 in terms of training dynamics. Project: mirandrom.github.io/zsl Paper: arxiv.org/pdf/2506.05447
English