
Kevin Weil 🇺🇸
20.7K posts

Kevin Weil 🇺🇸
@kevinweil
VP Science @OpenAI, BoD @Cisco @nature_org, LTC @USArmyReserve Ex: Pres @Planet, Head of Product @Instagram @Twitter ❤️ @elizabeth ultramarathons kids cats math
Portola Valley, CA Katılım Nisan 2007
2.7K Takip Edilen115.9K Takipçiler

Ever since my book Mobilize launched earlier this week, I’ve been flooded with messages from people asking how they can help save the American industrial base.
Now we’re launching a new fellowship to connect patriots to the movement:
Are you a veteran with an active security clearance looking for a new mission? A cleared, tech-savvy civilian who wants to do more than ride a desk?
Palantir wants YOU for the American Tech Fellowship-Mobilize.
We started ATF last year to identify and train elite American talent to revitalize our country.
Now we’re launching a new, accelerated ATF cohort (ATF-Mobilize) to teach America’s cleared workforce how to wield industry-leading software to reboot the defense industrial base.
ATF-Mobilize fellows will participate in eight weeks of live, virtual training on Palantir Foundry and AIP, guided by domain experts from Palantir and our partner, Ontologize. They will learn-by-doing, building custom tools solo and with their peers. Graduates will gain mission-critical skills and access to a growing alumni network. They will also be considered for jobs at Palantir and our customers supporting urgent missions across the defense industrial base.
ATF-Mobilize is your chance to deploy from your couch to a job in the engine rooms of American power. We want the best of the best. We want heretical heroes. Don’t let this opportunity pass you by.
Applications are live now. Training begins April 28.
Mobilize is a movement. Move out with us:
#recruiting" target="_blank" rel="nofollow noopener">mobilizebook.com/#recruiting

English
I'll put a lot of money on the over, @jpatel41 :)
Jeetu Patel@jpatel41
Thanks for the kind words @rohanvarma. The partnership between @Cisco and @OpenAI has been nothing short of fabulous. Especially over the past 75 days. Our team is pretty stoked with the progress being made with the use of Codex. Let’s keep pushing on both sides. Appreciate you leaning in. The goal is to have 6 products 100% written with AI by end of 2026 and 70% of our products 100% written with AI by end of 2027. @kevinweil thinks I am sandbagging. I hope to prove him right ;-).
English
Kevin Weil 🇺🇸 retweetledi

This news came out a little earlier than we planned; we're excited to be building a deployment arm and will share more details soon.
Companies have a ton of urgency to deploy AI in their organizations and we’re sprinting to meet that demand. More than 1 million businesses run on OpenAI products. Codex is now at 2M+ weekly active users, up nearly 4x since the start of the year. API usage jumped 20% in the week after GPT-5.4 launched. And Frontier, which launched last month to help enterprises build, deploy, and manage AI coworkers that can do real work, has way more demand than we can handle.
That's why we launched Frontier Alliances so we leverage our ecosystem of partners to scale. And that is also why we are launching a dedicated deployment arm tasked with embedding Forward Deployed Engineers deeply inside of enterprises. This project has been in the works with our investor and alliance partners since last December, and we are grateful for them and their partnership.
We’re still early, but the speed of adoption is a clear signal of where this is headed. We're excited to not just be building these technologies but also building many ways for companies to deploy them and get impact.
reuters.com/business/opena…
English
@ReneRosengren As an ultrarunner, I am also interested in this 🤠
English

@kevinweil While you are at it, can you also figure out how to regenerate worn cartilage and restore damaged joints into functional, usable ones again by using the body’s own building blocks? 😎
English
@tonyzzhao @christenobrien @ScribbleVC @sundayrobotics @elizabeth Also signing up for a memo as soon as it's available 🙋♂️
English

@christenobrien @ScribbleVC @sundayrobotics NO MORE DEMOS! And thanks for being a great partner from the very beginning! @elizabeth @kevinweil @christenobrien
English

THIS is how it's done! Shout out to to our @ScribbleVC company @sundayrobotics on:
a) their $165M Series B
b) connecting it to a powerful tag line "No More Demos"
The best startup announcements in 2026 look more like great marketing campaigns:
- speaking in numbers
- powerful slogans (Don Draper FTW!)
- eye-catching + specific visuals
- founder led -- critical
- persistent marketing online + offline, not merely trad media/PR
(also @tonyzzhao...I can't wait to get my Memo!)
Sunday@sundayrobotics
We just raised $165M to end robotics demos and deploy the world's first autonomous home robots into households this year.
English
Kevin Weil 🇺🇸 retweetledi

So excited to work together! I have a feeling it's going to be a productive summer :)
Acer@AcerFur
I guess now is as good a time as any to announce that I shall be joining the AI for Science team at @OpenAI this summer. This has been in the works since January, and I thank @SebastienBubeck and @kevinweil for their personal interest in making this happen.
English
If true, this would be the first of @EpochAIResearch's Frontier Math open problems to be resolved by AI.
"The result emerged from a single GPT-5.4 Pro run and was subsequently refined into Lean with GPT-5.4 XHigh which ran for a few hours."
spicylemonade@spicey_lemonade
We believe we have fully resolved, in Lean and python, one of @EpochAIResearch Frontier Math open problems: a Ramsey-style problem on hypergraphs. The result emerged from a single GPT-5.4 Pro run and was subsequently refined into Lean with GPT-5.4 XHigh which ran for a few hours. github.com/spicylemonade/… @Jsevillamol
English
A look at the future/present
Andrej Karpathy@karpathy
Three days ago I left autoresearch tuning nanochat for ~2 days on depth=12 model. It found ~20 changes that improved the validation loss. I tested these changes yesterday and all of them were additive and transferred to larger (depth=24) models. Stacking up all of these changes, today I measured that the leaderboard's "Time to GPT-2" drops from 2.02 hours to 1.80 hours (~11% improvement), this will be the new leaderboard entry. So yes, these are real improvements and they make an actual difference. I am mildly surprised that my very first naive attempt already worked this well on top of what I thought was already a fairly manually well-tuned project. This is a first for me because I am very used to doing the iterative optimization of neural network training manually. You come up with ideas, you implement them, you check if they work (better validation loss), you come up with new ideas based on that, you read some papers for inspiration, etc etc. This is the bread and butter of what I do daily for 2 decades. Seeing the agent do this entire workflow end-to-end and all by itself as it worked through approx. 700 changes autonomously is wild. It really looked at the sequence of results of experiments and used that to plan the next ones. It's not novel, ground-breaking "research" (yet), but all the adjustments are "real", I didn't find them manually previously, and they stack up and actually improved nanochat. Among the bigger things e.g.: - It noticed an oversight that my parameterless QKnorm didn't have a scaler multiplier attached, so my attention was too diffuse. The agent found multipliers to sharpen it, pointing to future work. - It found that the Value Embeddings really like regularization and I wasn't applying any (oops). - It found that my banded attention was too conservative (i forgot to tune it). - It found that AdamW betas were all messed up. - It tuned the weight decay schedule. - It tuned the network initialization. This is on top of all the tuning I've already done over a good amount of time. The exact commit is here, from this "round 1" of autoresearch. I am going to kick off "round 2", and in parallel I am looking at how multiple agents can collaborate to unlock parallelism. github.com/karpathy/nanoc… All LLM frontier labs will do this. It's the final boss battle. It's a lot more complex at scale of course - you don't just have a single train. py file to tune. But doing it is "just engineering" and it's going to work. You spin up a swarm of agents, you have them collaborate to tune smaller models, you promote the most promising ideas to increasingly larger scales, and humans (optionally) contribute on the edges. And more generally, *any* metric you care about that is reasonably efficient to evaluate (or that has more efficient proxy metrics such as training a smaller network) can be autoresearched by an agent swarm. It's worth thinking about whether your problem falls into this bucket too.
English
@SebastienBubeck seb is this the final topic of our 1:1 that we didn't get to
English

I used to think that I would not see a proof of P vs NP in my lifetime, but now with AI I'm not sure anymore, and that's pretty cool!
English

This is a pretty mind-blowing look inside GPT-4 and its reasoning abilities. Definitely worth your team to read.
Hanson Wang@hansonwng
English
Codex for Open Source is an awesome idea.
OSS maintainers get API credits, 6 months of ChatGPT Pro with Codex, and access to Codex Security as needed.
OpenAI Developers@OpenAIDevs
We’re launching Codex for Open Source to support the contributors who keep open-source software running. Maintainers can use Codex to review code, understand large codebases, and strengthen security coverage without taking on even more invisible work. developers.openai.com/codex/communit…
English
Kevin Weil 🇺🇸 retweetledi

some psychopath on the internal codex leaderboard hit 100B tokens in the last week
English
Kevin Weil 🇺🇸 retweetledi

GPT-5.4 set a new record on FrontierMath, our benchmark of extremely challenging math problems! We had pre-release access to evaluate the model. On Tiers 1–3, GPT-5.4 Pro scored 50%. On Tier 4 it scored 38%.
See thread for commentary and additional experiments.

English
Kevin Weil 🇺🇸 retweetledi

I’ve had early access to GPT-5.4 Pro. Without any reservation, I can say it is the most intelligent AI model to date, even significantly surpassing GPT-5.2 Pro at several levels! I’ve been using it non-stop past several days and am super excited about another major jump in AI!
I will share specific examples, but overall GPT-5.4 Pro demonstrates relatively higher creativity, insight, and abstract intelligence. It tends to ask “why,” “what if,” “can I,” and “why it matters” type questions more frequently than the 5.2 Pro model.
It also appears to generalize more effectively and comes across as more AGI-like in its reasoning, and even displays human-like intuition! Especially biomedical science-based responses are unifying large data sets and simply amazing!
English
@iz9Smi0cmU90iHN within error bars though, i'd basically read that as "5.4 pro is equivalent to 5.4 on GDPVal" (both SoTA btw)
English

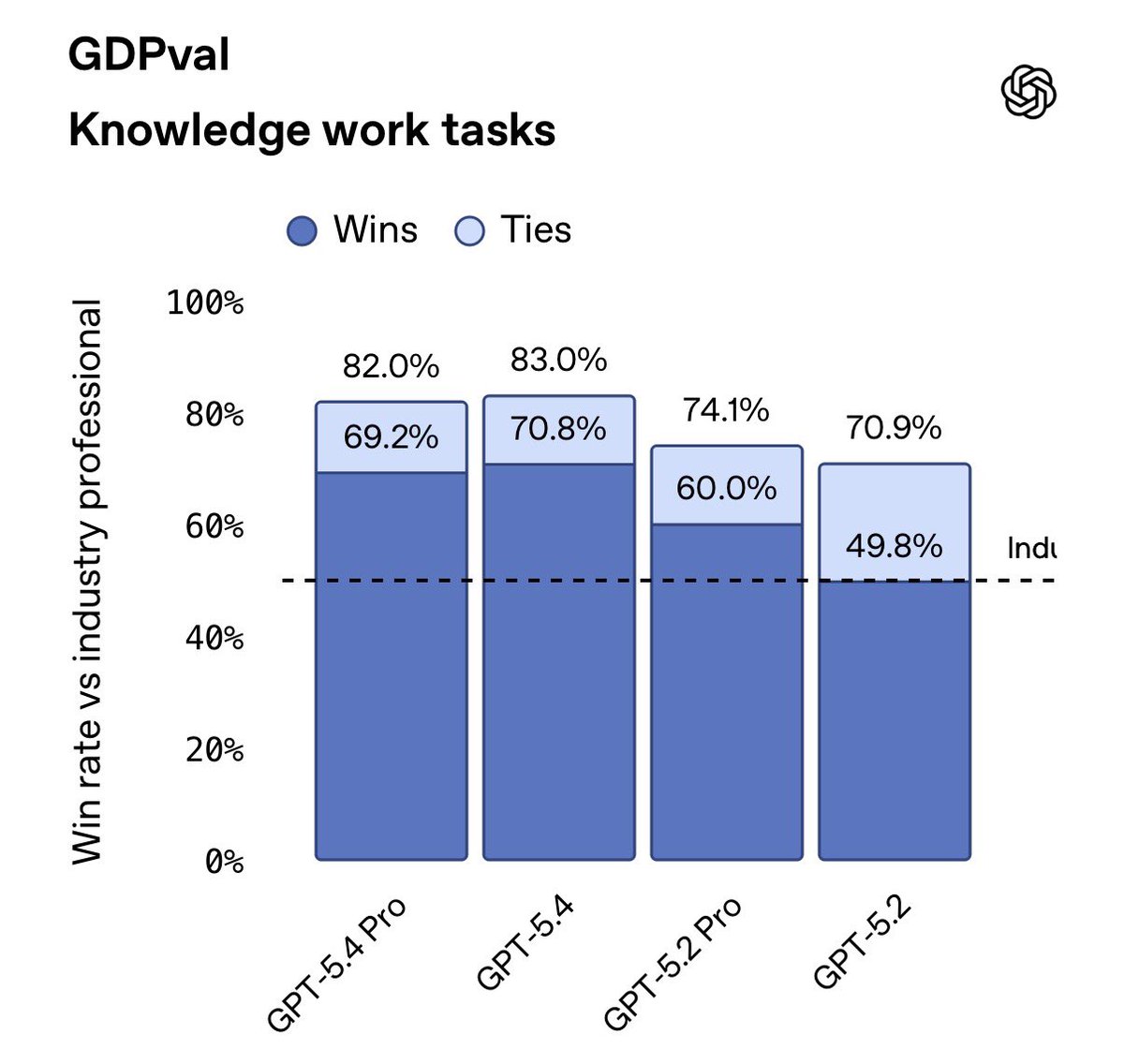
💥 GPT 5.4 is launching today! It's our best model ever, and it's also the most capable scientific model we've ever released.
GPT 5.4 Pro in particular is 🤯 based on early testing with scientists and mathematicians.
English