Just explored LLM fine-tuning techniques, LoRA, QLoRA, quantization, and efficient training methods.
Really fascinating how much optimization is possible while reducing compute + memory requirements. Excited to dive deeper into practical implementations #LLM#AI
#hiring intern
Enterpret is hiring an ML Intern!
Location: Bengaluru, India
Experience: Entry level
Stipend: 30k - 40k / month
-Python · LLMs · RAG · AI Agents · Prompt Engineering · Eval Frameworks · Fine-tuning
Let us know if you are interested 👇
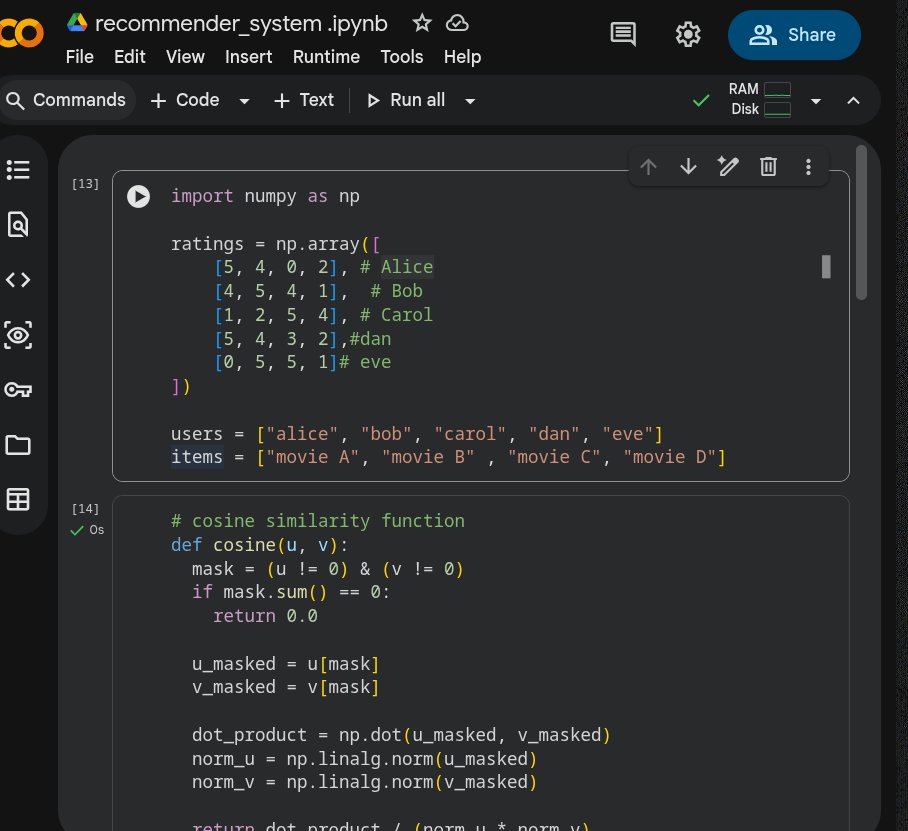
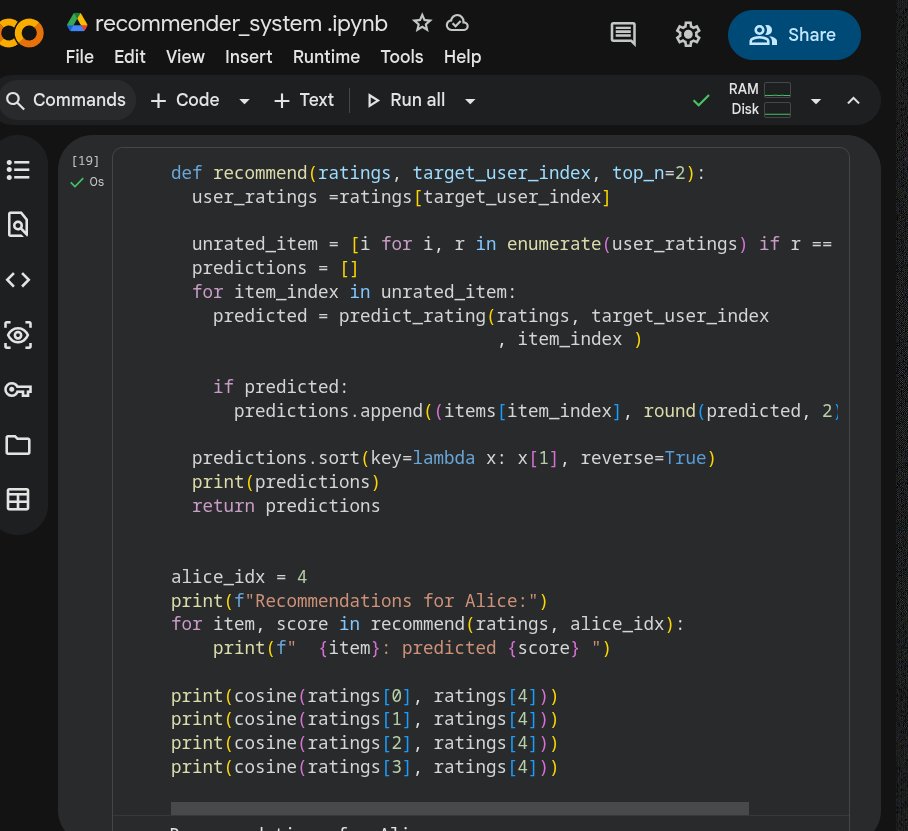
The Math: Cosine Similarity
To find "similar users" we need to measure similarity. The most common way is cosine similarity — it measures the angle between two rating vectors.
Role: Software Engineer Intern
Salary: $700 monthly
Location: Remote
- You are curious, eager to learn
- You enjoy working collaboratively
Let us know if you are Interested 👇
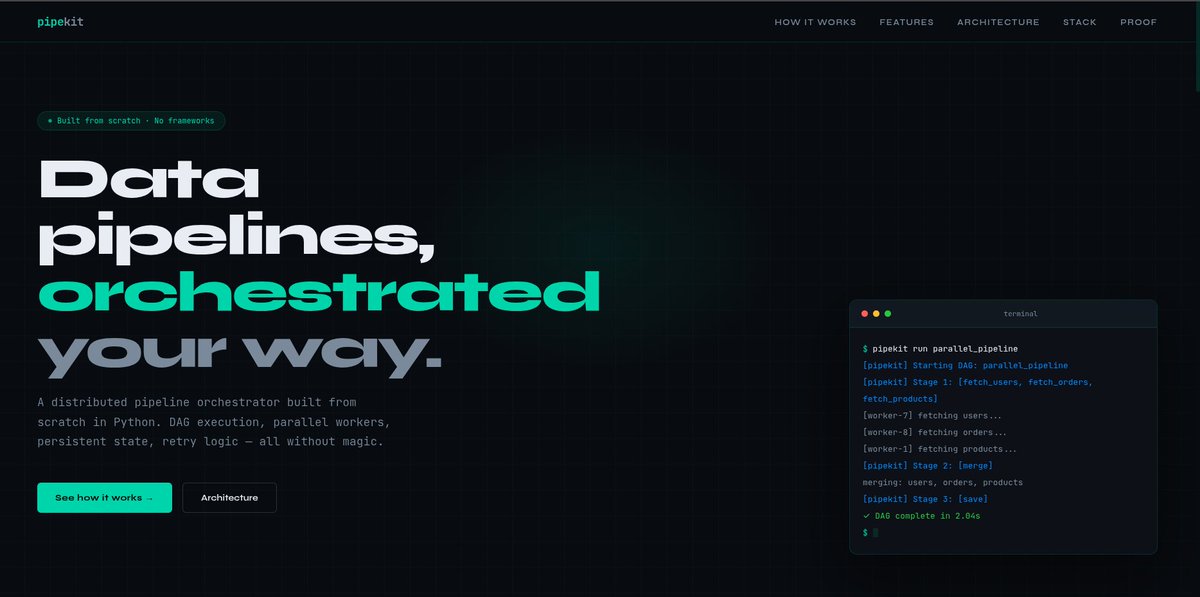
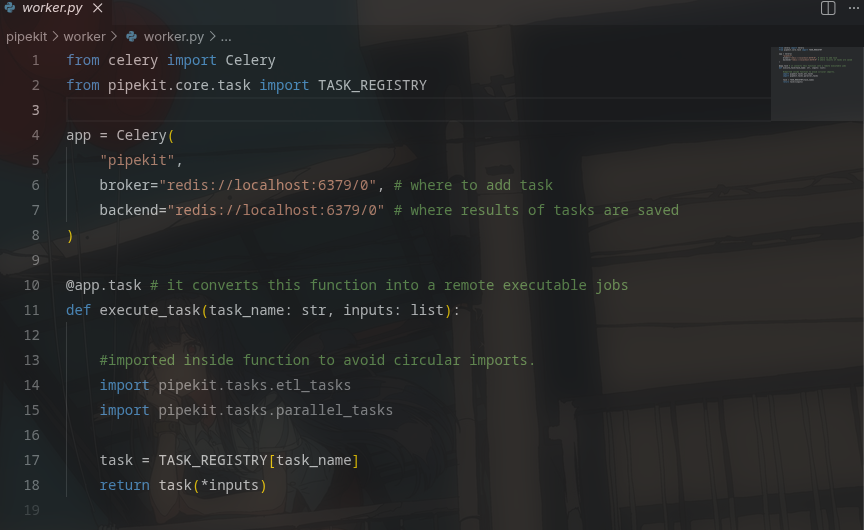
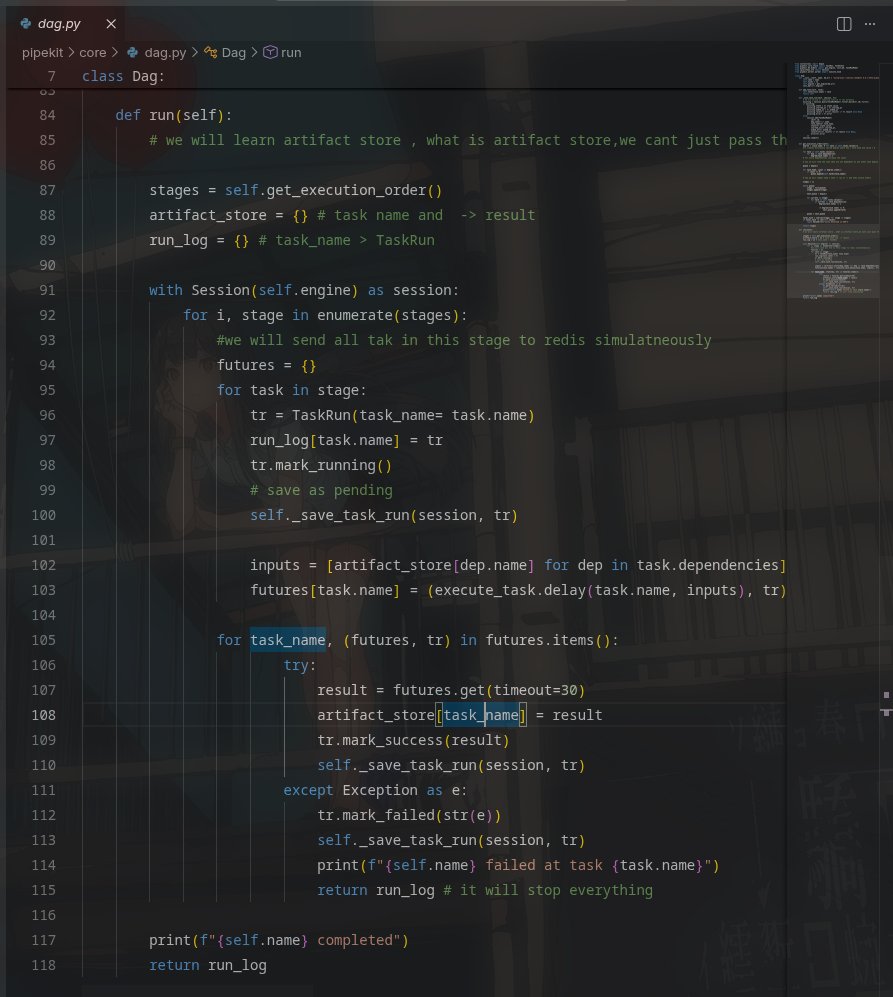
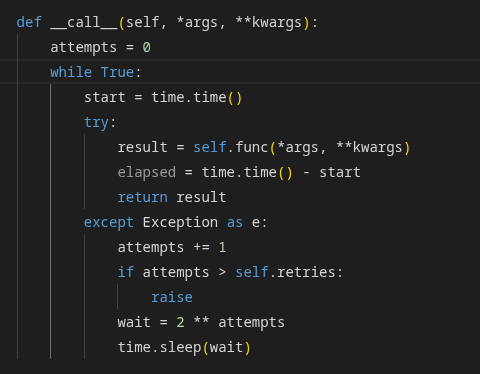
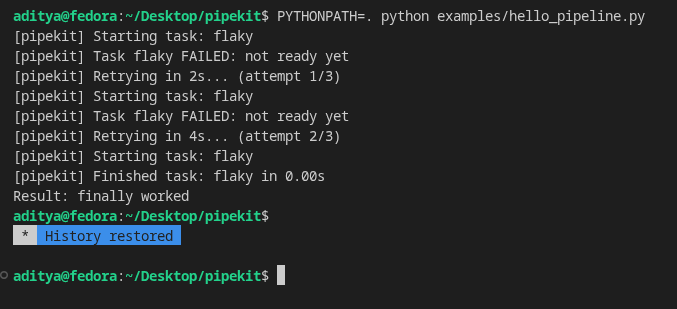
Built a distributed pipeline orchestrator from scratch in Python.
DAGs. Parallel workers. Retry logic. REST API. CLI. PostgreSQL state.
3 tasks × 2s each → finished in 2s not 6s. Proof of parallelism.
Check it out 👇
- #how" target="_blank" rel="nofollow noopener">pipekit-liart.vercel.app/#how
- github.com/adityasingh345…
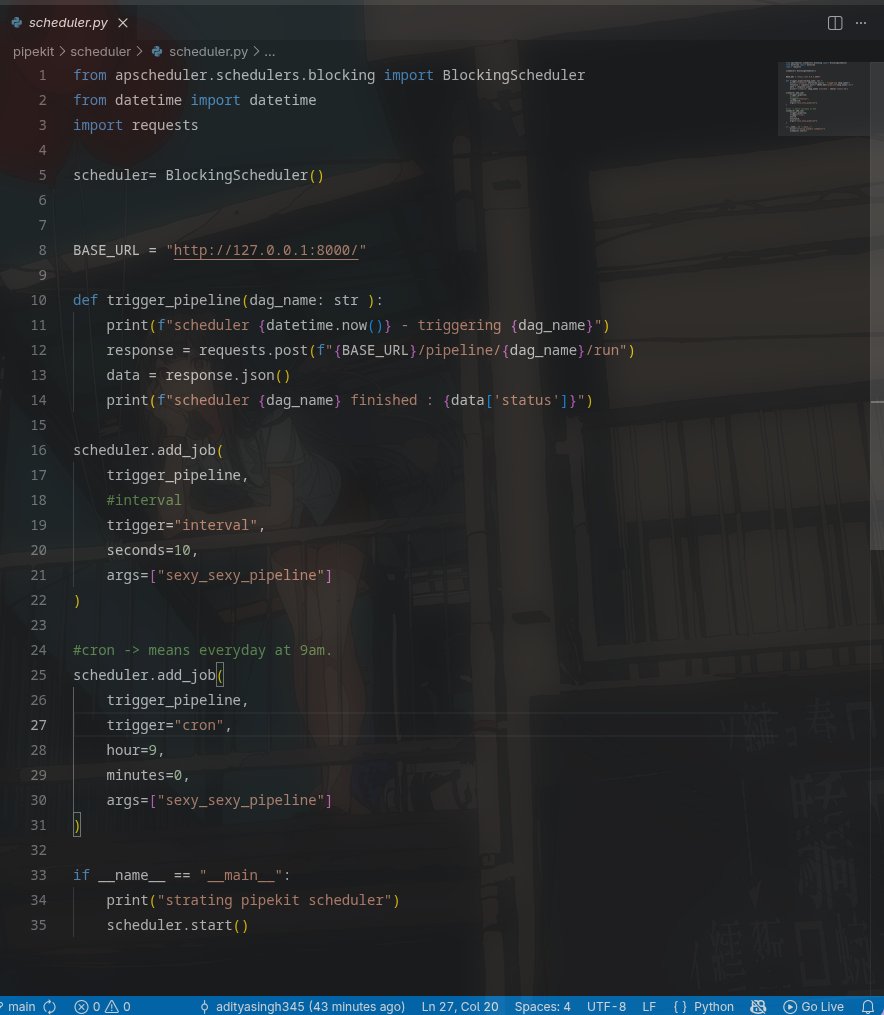
The next thing that i have to implement is scheduler-> to run the pipeline automatically like every hour, every midnight something like this.
workers-> when we have wave [B. C] it runs B and then C it runs sequentially but we want to run them parallel.
right now we have to manually call dag.run(), but a real orchestrator should be able to run automatically-> like run this every day at 9am. for this we need scheduler
state machine for now is in memory before the scheduler we need persistent state with PostgresSQL