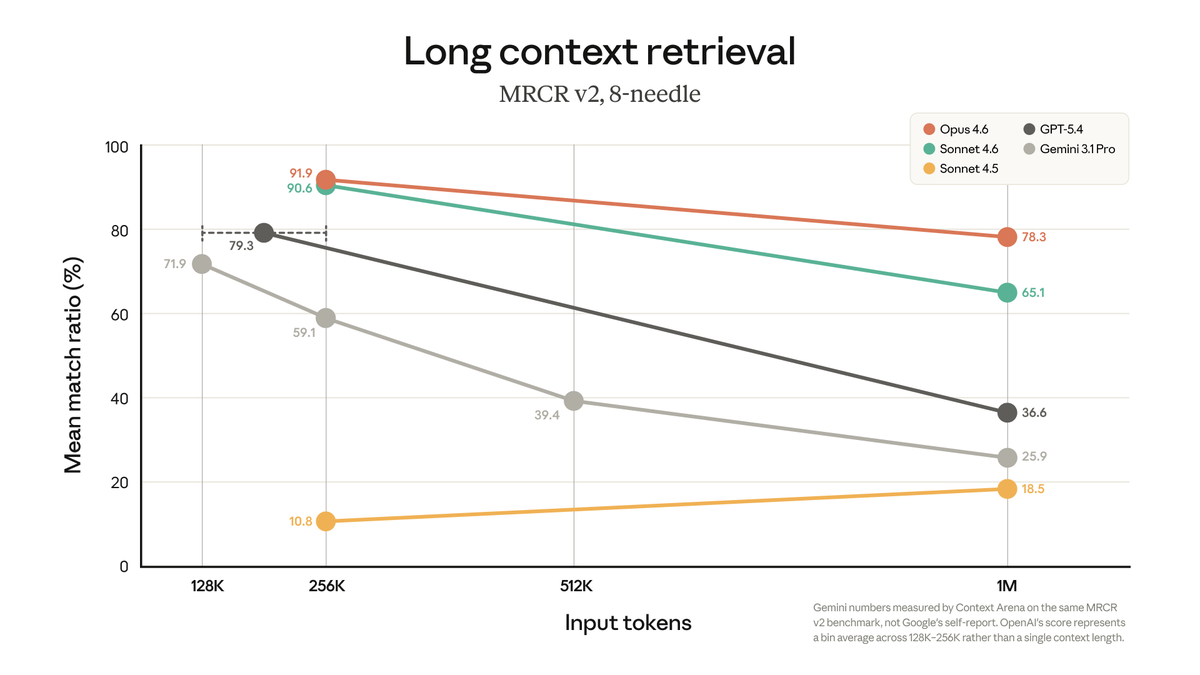
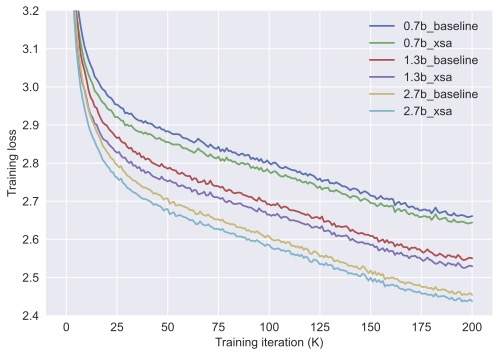
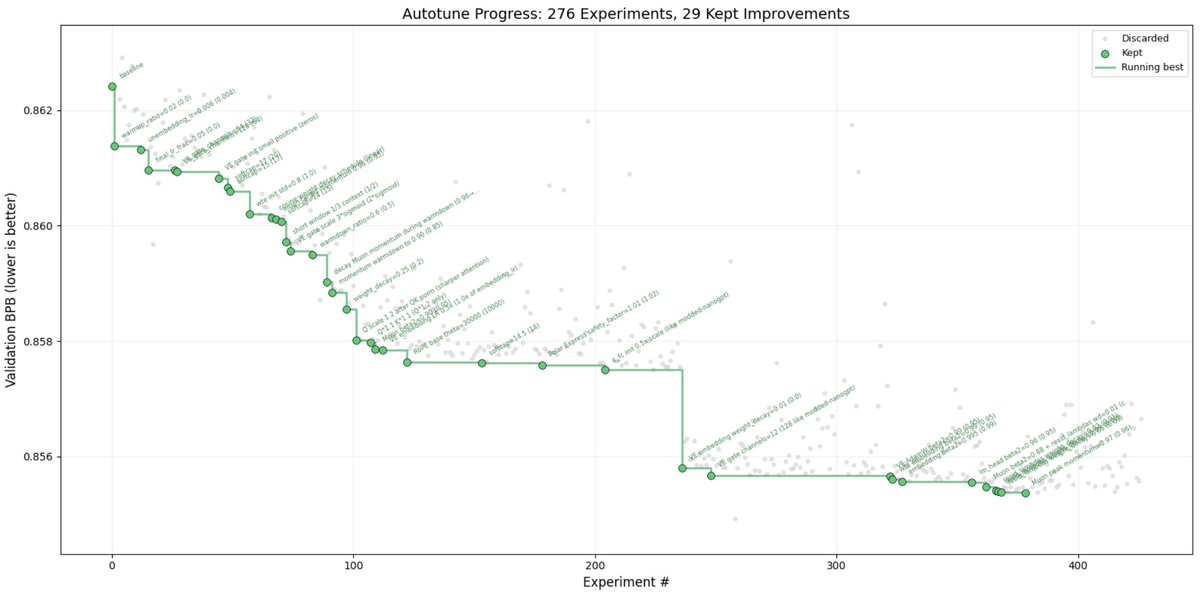
Sabitlenmiş Tweet

TLDR: 1⃣ line modification, satisfaction (theoretically and empirically) guaranteed 😀😀😀
Core idea: 🚨Do not update if you are not sure
👨💻github.com/kyleliang919/C…
🤗huggingface.co/papers/2411.16…
📚arxiv.org/abs/2411.16085
@cranialxix @lqiang67 @Tim38463182
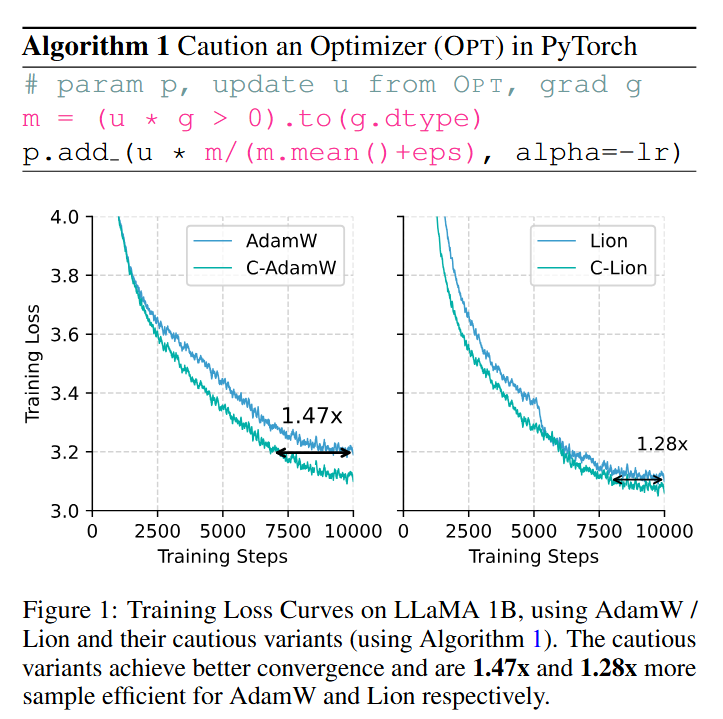
English