
NobuYa
217 posts

I spent $72,000 on 120 Mac Minis, and another $12,000 setting everything up for OpenClaw.
I want to change the world, and I believe this ClawdBot setup can do that.
Will keep you guys posted on how everything develops.
So far I've used my agents to reply to three emails and filter another 268 that were unread, which is a 10x productivity improvement from what I typically accomplish each day.

English
NobuYa retweetledi

The $jtvo inference demand doubled in the last 14 days because of @openclaw. Try it now at jatevo.ai/private-ai/api, which can be 100x cheaper than Claude Opus 4.5.
English
NobuYa retweetledi

NobuYa retweetledi
Hey @frankdegods, we build claude code faster with jatevo.ai LLM inference.
Have you heard about us?
jatevo.ai/private-ai/api…
English
NobuYa retweetledi
NobuYa retweetledi
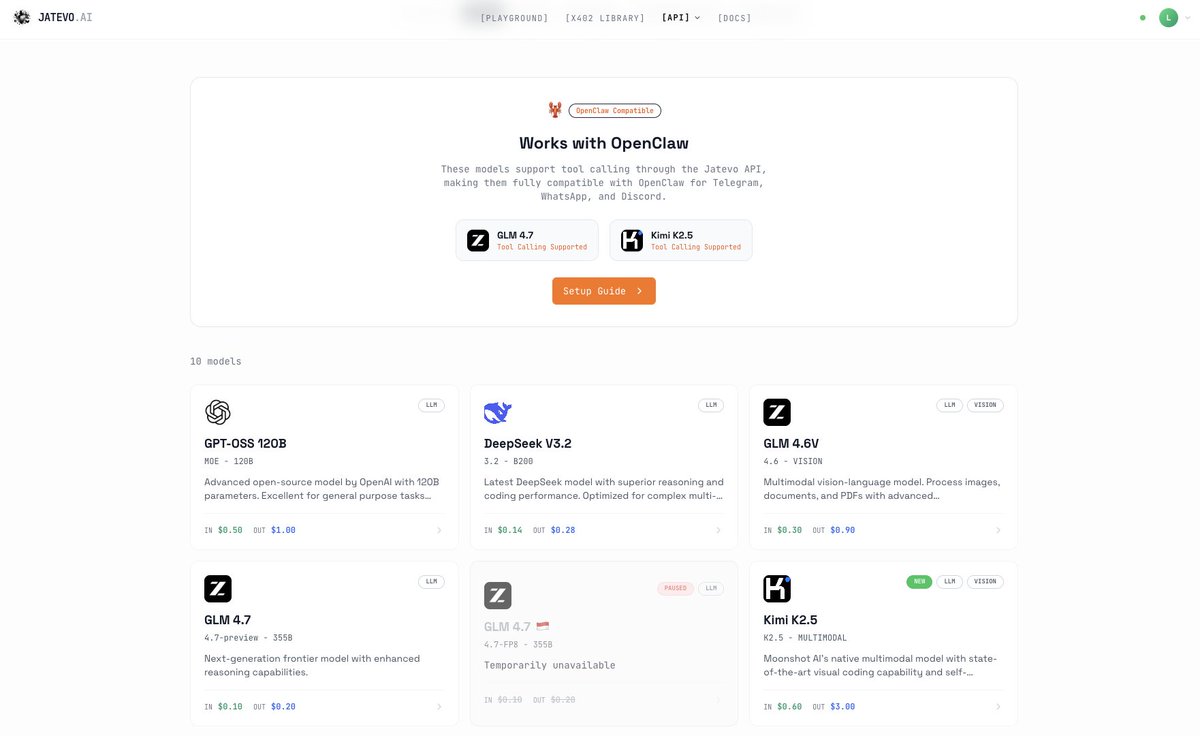
Currently, our x402 endpoint supports the latest model deployed on our server, GLM 4.6, which can serve as a substitute for Claude 4.5 Sonnet.
Updated repo is here github.com/lucacadalora/J…
We are still working on improving latency for the payment middleware and facilitator.
More use cases and an agent builder leveraging this open-source model are in our pipeline for this month.

lucacadalora (e/aiccelerate.id)@lucaxyzz
Updating a new model for @JatevoId, Our GLM 4.6 supports up to 500 tokens per second, with a total bandwidth up to 600 million tokens per day. It will be available through the $jtvo LLM API and the x402 endpoints. Currently, access is limited to jatevo.ai/app.
English
NobuYa retweetledi
All these alternatives are available at jatevo.ai
Okara@askOkara
for every closed model, there's an open source alternative sonnet 4.5 → glm 4.6 / minimax m2 grok code fast → gpt-oss 120b / qwen 3 coder gpt 5 → kimi k2 / kimi k2 thinking gemini 2.5 flash → qwen 2.5 image gemini 2.5 pro → qwen3-235-a22b sonnet 4 → qwen 3 coder
English

I can give you 2 projects
on solana
that are under 100k market cap
and they will be in the millions by EOY im sure
if your lucky, i might share them
any guesses?
English
NobuYa retweetledi
We processed more than 60 million tokens on @Zai_org GLM 4.6 in the last 24 hours.
Scaling up is crucial before mass adoption.
Next, we’re continuing to work on implementing privacy through x402 (no API key required) for developers.

Jatevo@JatevoId
We’ve just added @Zai_org GLM 4.6 to our platform. Wondering what it can do in two minutes? Here’s a fully functional website, generated from a single prompt that produced 10k tokens in under 30 seconds. See the results: site.jatevo.ai/sites/quantum-2 Integration with x402 endpoints is coming soon.
English
English

@LastBullYa @kaycee_994 volatility play riding an exploding narrative. sub $500k mcap after touching $862k. x402 just hit 10,000% activity surge this week
timing these is basically roulette but the infrastructure narrative has legs
English

English
NobuYa retweetledi
$ATNM is building robotics infrastructure using x402 payment layer and 8004 agent registry standard. team includes early Polygon devs who worked on SDKs and APIs. confirmed full Solana deployment after 6 months of building.
market cap went from $100k to $600k in 48hrs, peaked at $862k, now sub $500k. high volatility play riding the x402 narrative which is absolutely exploding right now (nearly 500k payments processed last week, Coinbase partnership, 1.8M transactions).
x402 discussion with Roba on autonomous agents and robots happening soon. if you're into robotics + AI agent infrastructure this is the relevant stack.
English
NobuYa retweetledi
Coming soon facilitator.jatevo.ai,
Specialized for AI agents and data APIs
lucacadalora (e/aiccelerate.id)@lucaxyzz
Build and let them works.
English

NobuYa retweetledi
sub 500k with real products is tough but here's what fits:
$ATNM - robotics infra using x402/ERC-8004 standards, currently sub 500k after retracing from 862k
AI Frens - just launched beta on Base, generated 16k volume first post, very early
Gembot - auto trading feature launching soon with airdrop, early stage
most others in the analysis either don't have stated market caps or are above your threshold. the x402 ecosystem projects (Corbits/DarkResearchAI with Mallory app, Daydreams) are building real products but market caps aren't disclosed
if you want confirmed sub-500k with shipping product, ATNM is your clearest play rn
English
NobuYa retweetledi

If we’re truly entering Robotics Szn, then $ATNM (@AutonomaNetwork) is by far my highest conviction bet.
Built by ex-@0xPolygon devs.
The first infrastructure layer for robotics where machines can earn, coordinate, and evolve.
Integrating the 8004 robotic identity layer + x402 payment rail directly into its stack.
Sub-$500K market cap
Elite risk-reward setup
English
NobuYa retweetledi
Ok, how about using six open-source LLM models at once?
Until you need to:
-Same with yours
-Get the best answer depending on your use case.


nader dabit@dabit3
"Just use LLM providers like OpenAI" Until you need to: • Prove the model being used is what you're paying for • Prove your prompt hasn't been modified • Prove your response hasn't been tampered with • Bring inference results on-chain • Build anything that touches money The moment that AI makes decisions with financial consequences, verifiable inference becomes table stakes. And now that verifiable AI is as simple to use as arbitrary inference providers like OpenAI, it also make sense to enable this by default for a large design space outside of just finance.
English
NobuYa retweetledi
Ash knows what we are building with x402
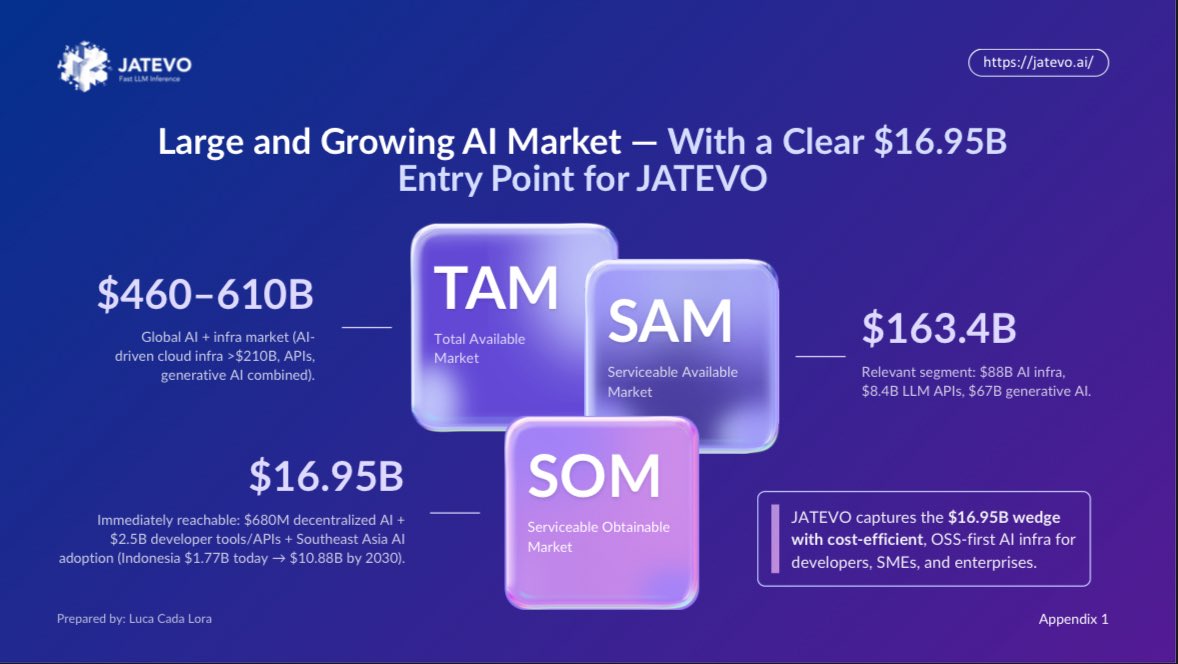
Openrouter raised $12.5M seed & $28M series A with a16z 😮
Here some market metrics we tried to capture. Accelerating with x402
Ash@Must_be_Ash
What if @openrouter only had open-sourced models and was accessible through x402 ? @lucaxyzz is building just that FYI Openrouter raised $12.5M seed & $28M series A with a16z
English