LeapLab@THU retweetledi

LeapLab@THU
15 posts

@LeapLabTHU
LeapLab@THU
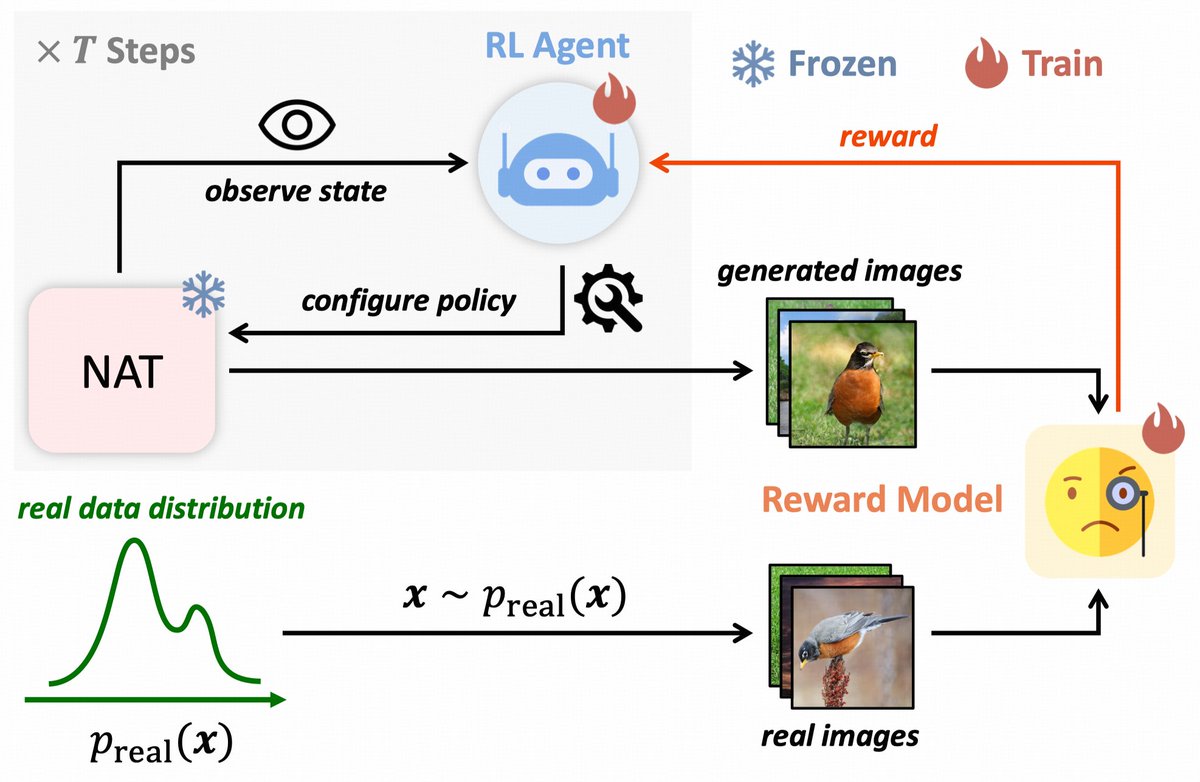
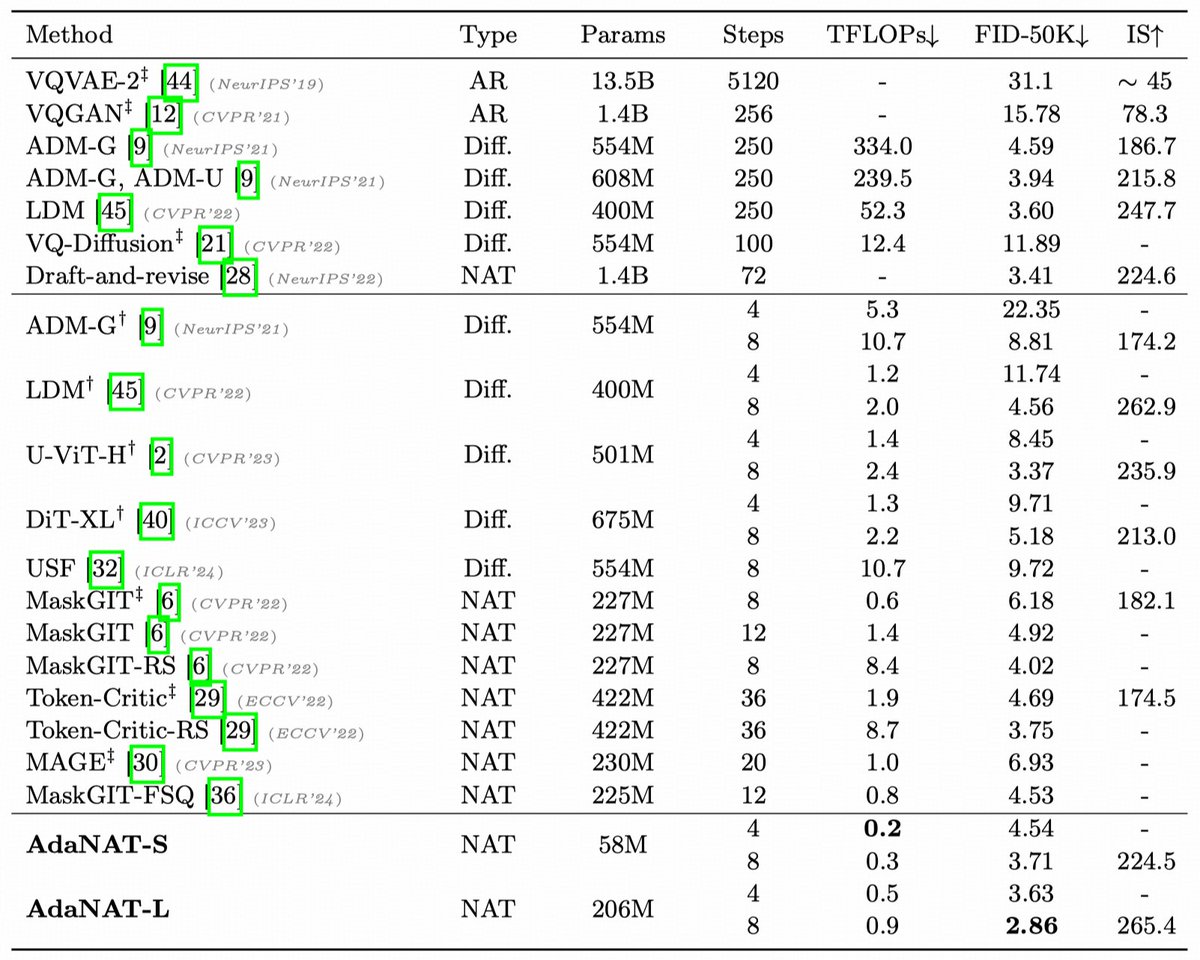
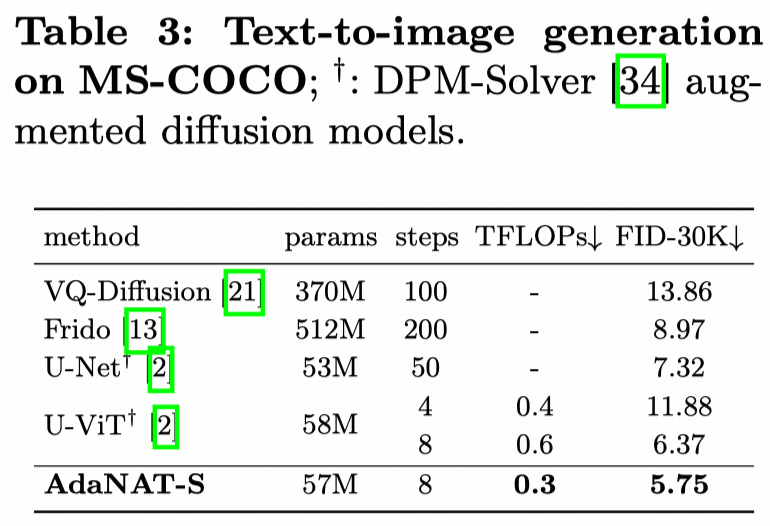
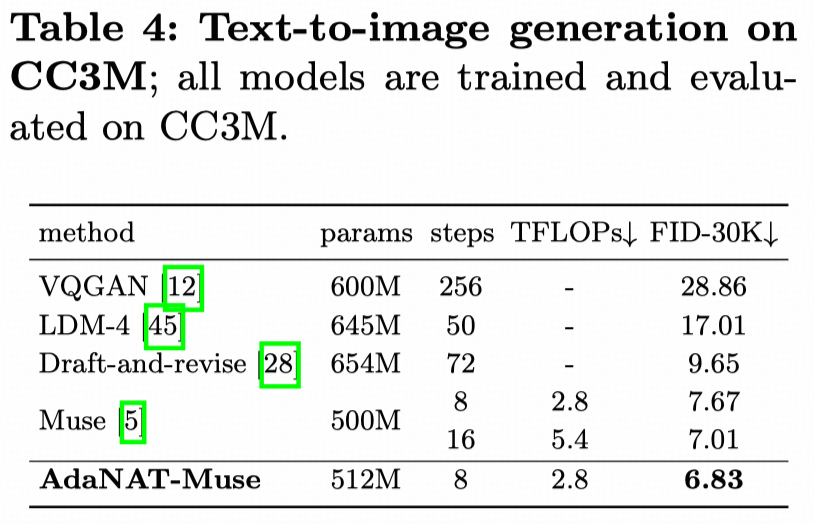

📢 New paper alert! 📢 🧠💉"Model Surgery: Modulating LLM's Behavior Via Simple Parameter Editing" 🚀 Modulate LLM behaviors through direct parameter editing. 🚀 Achieve up to 90% detoxification with inference-level computational cost! 💡🤖 arXiv: arxiv.org/abs/2407.08770










🚀🚀🚀Our new preprint introduces ExpeL, an agent designed for self-improvement in LLM agents🤖. ExpeL can automatically gather experience, extract insights, and recall successful instances across tasks🧠. Checkout our paper at arxiv.org/abs/2308.10144.





