Lecomte Benoît retweetledi

🚨 ConnitoAI SN 102 💥
ConnitoAI (Bittensor Subnet 102): The Decentralized Training Factory That Could Power the Next Wave of Specialized AI Models
In a world where the smartest AI apps are ditching rented frontier models for their own specialized, data-loop-trained beasts (as Charlie O’Neill laid out x.com/oneill_c/statu…), the real money flows to whoever can train those custom models efficiently at scale.
Enter ConnitoAI – Bittensor Subnet 102 – a research-first play building exactly the decentralized “training factory” the ecosystem needs.
This isn’t another inference subnet. This is infrastructure for the agentic, vertical-AI explosion.
Core Thesis
Big labs own the general models. Winners in 2026+ will own specialized experts trained on proprietary user feedback, domain data, and real outcomes.
ConnitoAI solves the hard part: Training massive specialized models (100B+ params) without OpenAI-level compute.
They use Mixture-of-Experts (MoE) built for decentralization:
• Miners train specialized “experts” locally on affordable GPUs.
• Validators coordinate, merge smartly, and reward via real performance (Proof-of-Loss).
• Math POC proves targeted gains with zero catastrophic forgetting.
Perfect for the trend: Enterprises & vertical apps (legal, healthcare, finance, agents) spin up custom experts on private data loops via Training-as-a-Service (TaaS). Privacy-first. Composable. Updatable moats the big labs can’t touch.
Why Now?
• Shift to “own your data flywheel” is accelerating (Cursor, Harvey, Abridge etc.).
• Decentralized training was the missing piece in Bittensor.
• Agentic AI needs swarms of specialist experts. MoE + TAO incentives = natural fit.
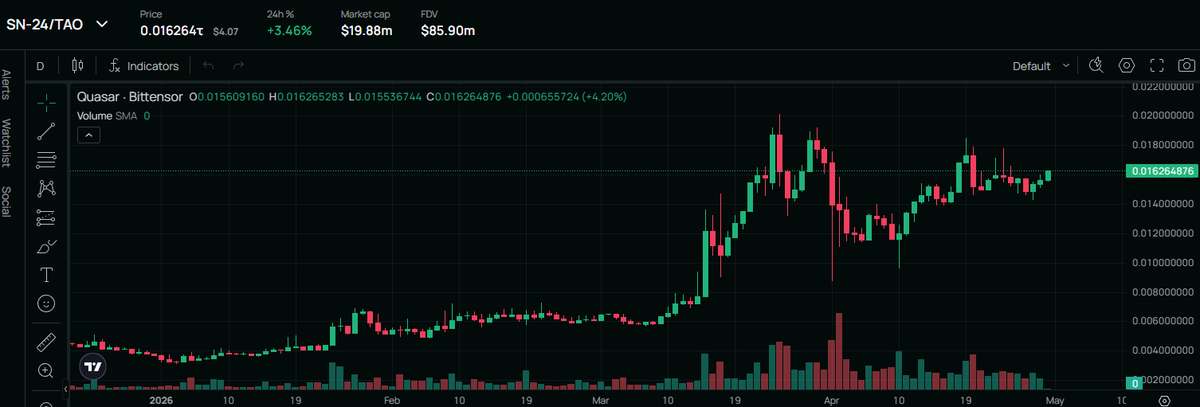
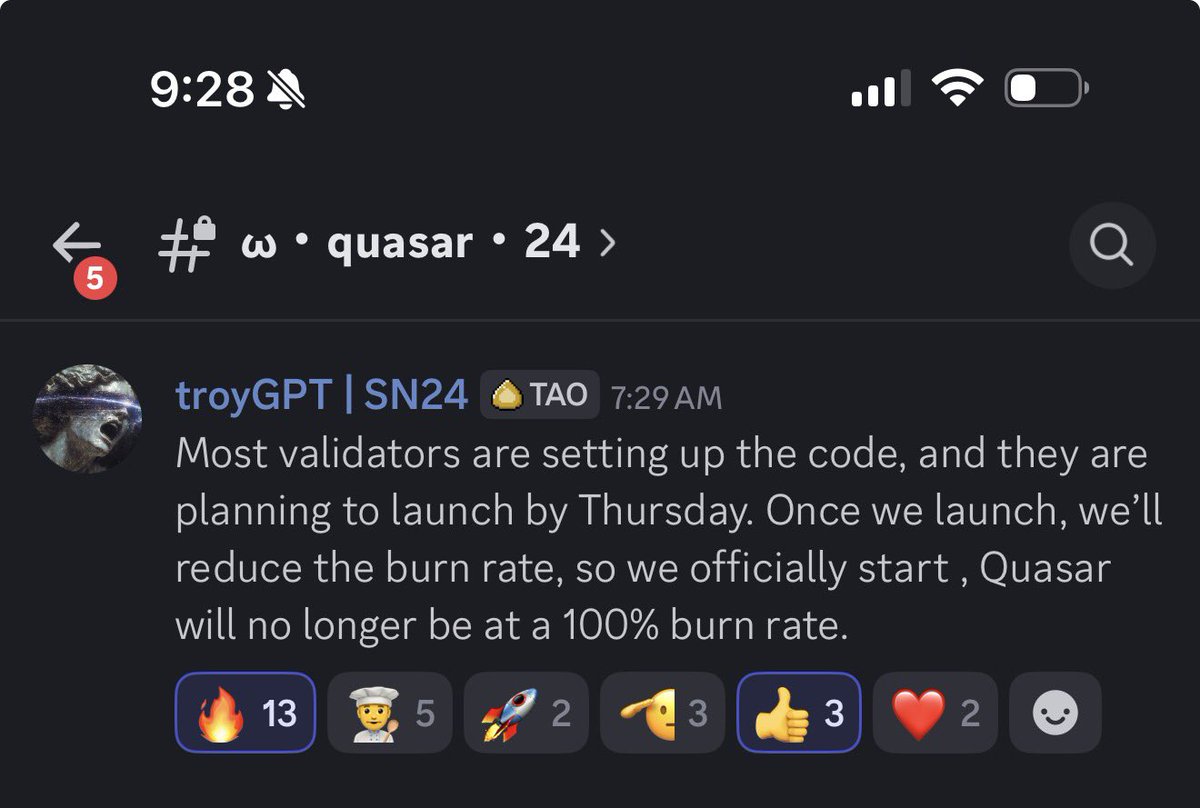
• Tiny market cap. High staking APY potential. Dashboard dropping ~May 26. Research paper soon.
Bull Case
If they nail TaaS, ConnitoAI becomes the go-to decentralized training marketplace. Reusable expert library compounds. Real revenue on top of emissions. In a TAO bull run, this could rerate 10-50x+ from current levels. Asymmetric upside.
Risks (be real)
Early stage. Execution on enterprise deals. Competition heating up. Classic crypto volatility.
Bottom line
ConnitoAI (SN102) is one of the highest-conviction asymmetric bets in Bittensor for believers in specialized, privately-improved models. Tiny valuation, strong tech moat, perfectly timed.
High risk. High conviction. Release the Kraken. 🚀🐙
DYOR. Size appropriately.
$TAO $SOL #Bittensor #TAO #ConnitoAI #SN102 #DecentralizedAI #CryptoAI #AI #Web3 #Crypto #Solana #AIAgents
English