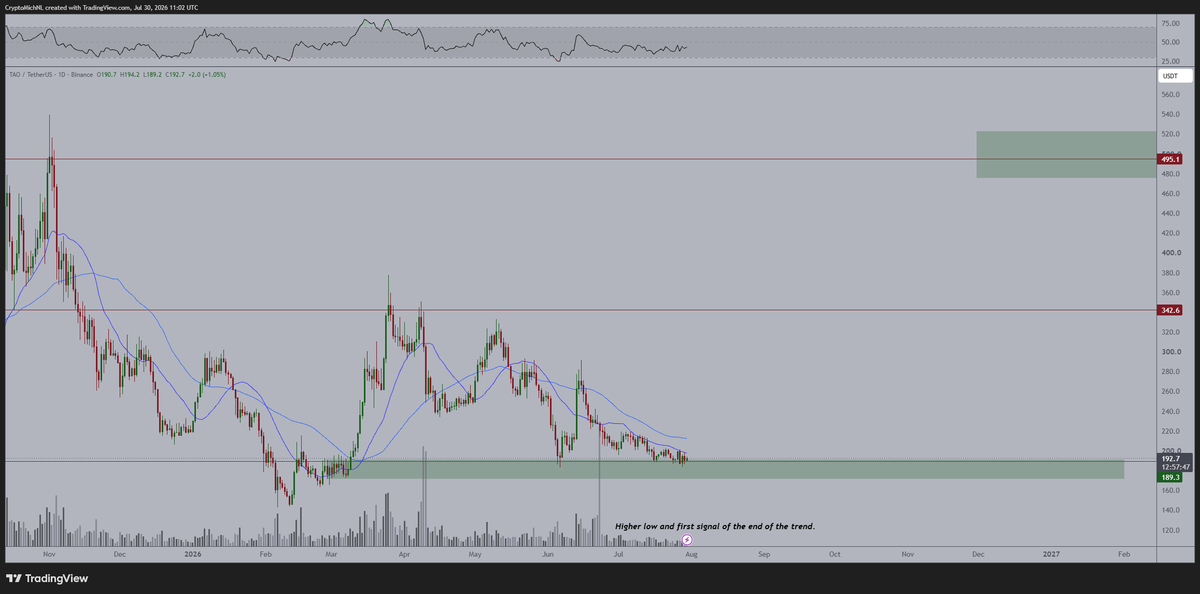
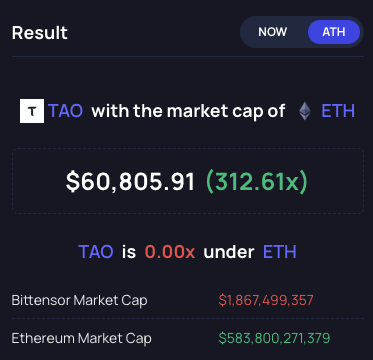
The Bittensor Netrunner - TAO - NOCK - retweetledi

Bittensor
$TAO
Subnet 53: Engy
@engyai
@totheagi
@AlgodTrading
@jaltucher
It looks like the days ahead are going to be exciting.
Mark Jeffrey@markjeffrey
HOW much cheaper is @engyai inference versus everyone else? Here you go. Similar cheaptification for Kimi K3 coming ~1 day. Bittensor $TAO.
English