Leonard Berrada retweetledi

Introducing Gemini 2.5 Pro Experimental! 🎉
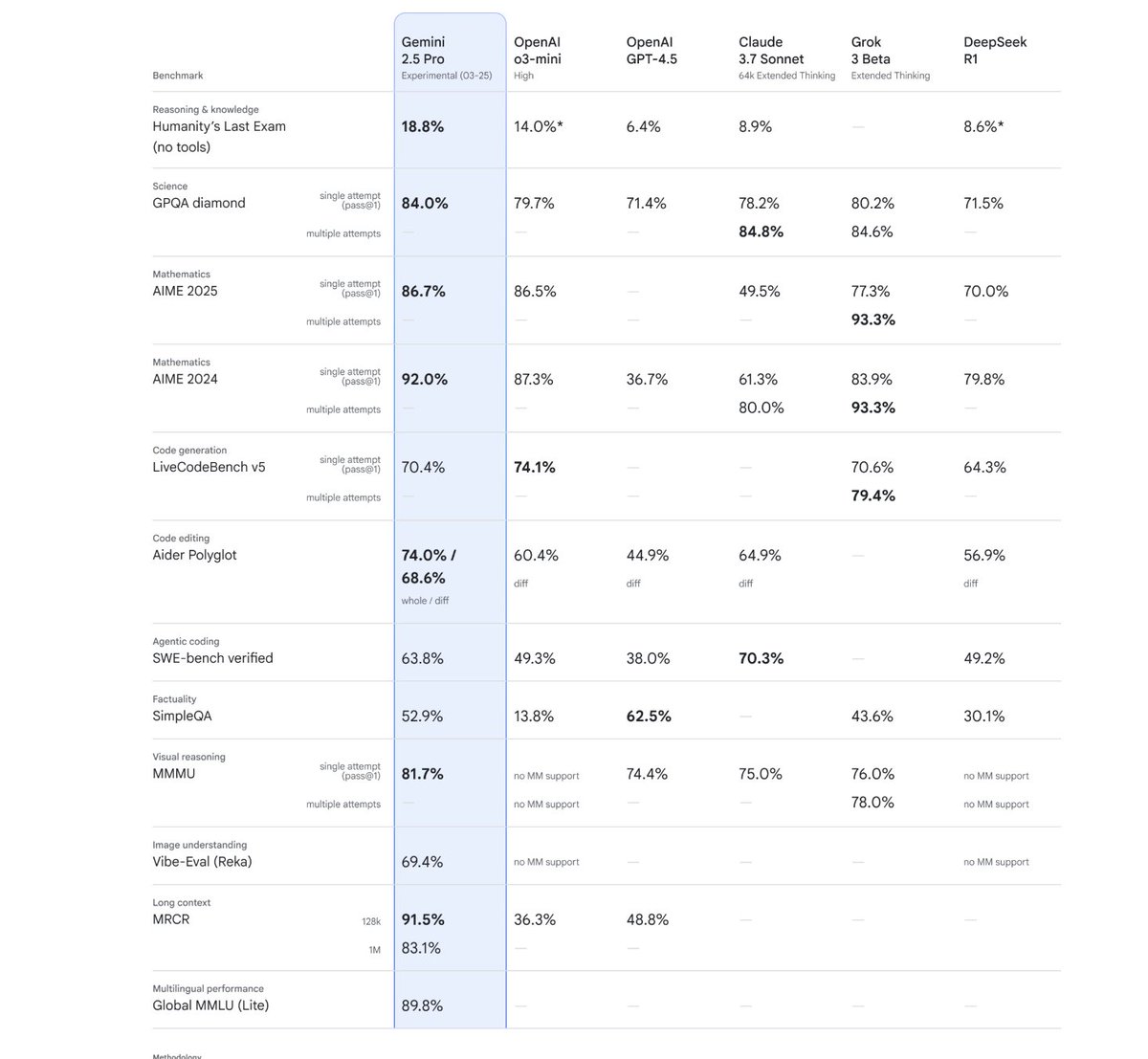
Our newest Gemini model has stellar performance across math and science benchmarks. It’s an incredible model for coding and complex reasoning, and it’s #1 on the @lmarena_ai leaderboard by a drastic 40 ELO margin. Only a handful of model releases have leaped ahead so strongly in ELO. 📈
ELO score differences map directly to win rate: e.g. a 400 ELO difference yields a ~91% win rate. Incredible that since 1.5, just a year ago, we jumped 200 ELO (300 since 1.0).
Here’s a fun example where Gemini 2.5 Pro writes code to create an animated swarm of colorful boids swimming in a rotating hexagon. 💫
Try the model for free today in AI Studio. It’s also available to Gemini Advanced users in @geminiapp. aistudio.google.com/app/prompts/ge…
Blog: goo.gle/4c3NitO
English