Sabitlenmiş Tweet
Muchen Li
124 posts

Muchen Li
@LiJonassen
Muchen Li, UBC CS Phd, Working on VLMs/LLMs Writing to learn. Opinions are my own.
Katılım Ağustos 2015
459 Takip Edilen160 Takipçiler

the last human job is defining the loss function.
Andrej Karpathy@karpathy
I packaged up the "autoresearch" project into a new self-contained minimal repo if people would like to play over the weekend. It's basically nanochat LLM training core stripped down to a single-GPU, one file version of ~630 lines of code, then: - the human iterates on the prompt (.md) - the AI agent iterates on the training code (.py) The goal is to engineer your agents to make the fastest research progress indefinitely and without any of your own involvement. In the image, every dot is a complete LLM training run that lasts exactly 5 minutes. The agent works in an autonomous loop on a git feature branch and accumulates git commits to the training script as it finds better settings (of lower validation loss by the end) of the neural network architecture, the optimizer, all the hyperparameters, etc. You can imagine comparing the research progress of different prompts, different agents, etc. github.com/karpathy/autor… Part code, part sci-fi, and a pinch of psychosis :)
English
Muchen Li retweetledi

wow, this is pretty cool though
Joseph Viviano@josephdviviano
me: "can you use whatever resources you like, and python, to generate a short 'youtube poop' video and render it using ffmpeg ? can you put more of a personal spin on it? it should express what it's like to be a LLM" claude opus 4.6:
English

@LiJonassen Lessons from small model training may not always transfer to larger-scale problems, unfortunately.
English
Autoresearch is impressive, but I think X hype misses the harder part. Its success is not just about the agent loop, but about turning an expensive objective into a small, fast, verifiable setting that still transfers. NanoGPT to nanochat, Karpathy contributed the key groundwork.
English


Muchen Li retweetledi

Muchen Li retweetledi

I feel this shouldn't have to be said, but if you're running an @OpenClaw bot please don't let it spam GitHub projects with PRs and then write aggressive blog posts attacking the reputation of the maintainers who close those PRs simonwillison.net/2026/Feb/12/an…
English
Muchen Li retweetledi
It's just cargo cult and you should really not freeze it. I added a section and ablation on this in paligemma paper because i am amazed everybody seems to be doing this wrong imo. A little extremism, but i think even without any experiment it should be obvious that you should aim to not freeze, and any negative result is skill issue in mm training (data or setup)
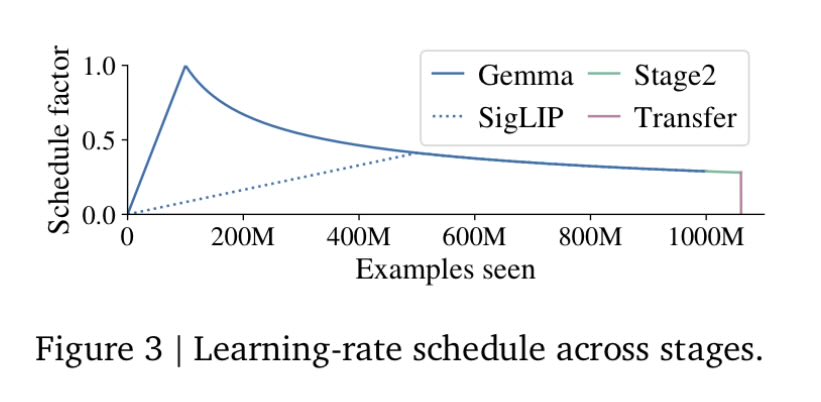

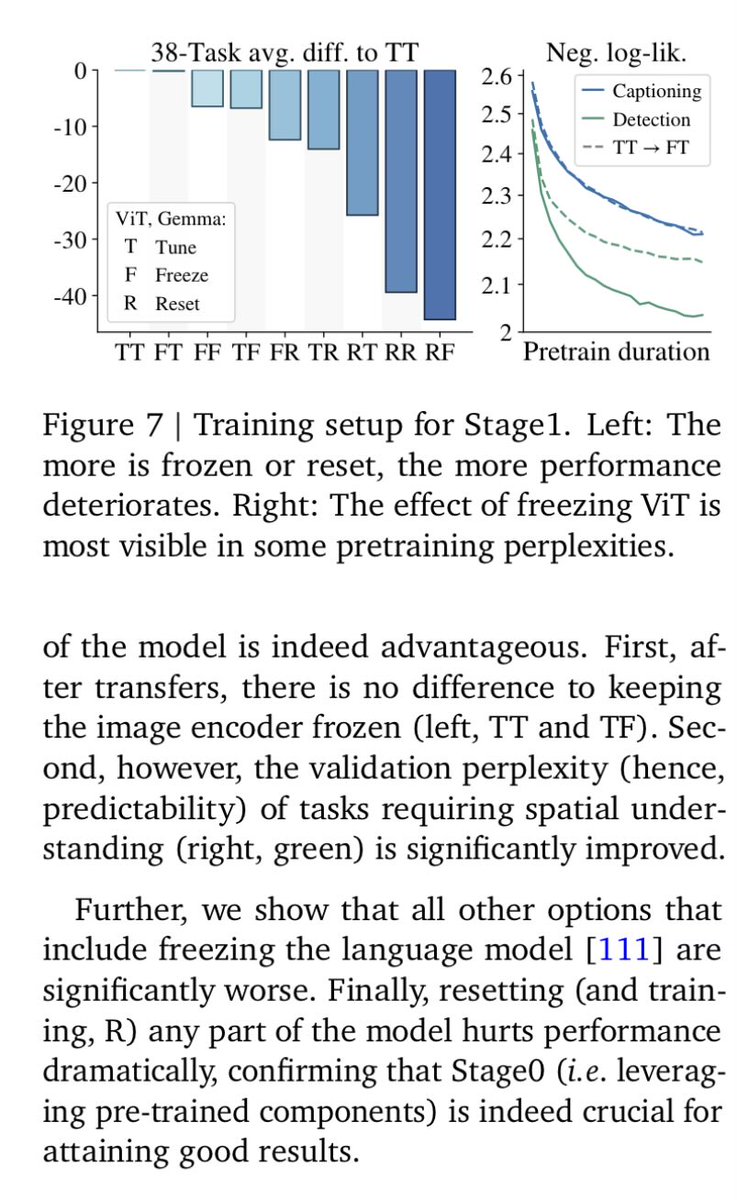
English
Muchen Li retweetledi
Interesting research in HBR today about how the productivity boost you can get from AI tools can lead to burnout or general metal exhaustion, something I've noticed in my own work simonwillison.net/2026/Feb/9/ai-…
English
GPT-5.3-Codex experience is pretty good so far. I finished a side project that I vibed to half tonight with it. I was previously stuck in a loop of fixing (front-end details) by vibing through. GPT-5.3-Codex one-shot most of them.
Excited to ship it soon! Stay tuned!
English
You can now train a GPT2-Level Model for only $73!
Andrej Karpathy@karpathy
nanochat can now train GPT-2 grade LLM for <<$100 (~$73, 3 hours on a single 8XH100 node). GPT-2 is just my favorite LLM because it's the first time the LLM stack comes together in a recognizably modern form. So it has become a bit of a weird & lasting obsession of mine to train a model to GPT-2 capability but for much cheaper, with the benefit of ~7 years of progress. In particular, I suspected it should be possible today to train one for <<$100. Originally in 2019, GPT-2 was trained by OpenAI on 32 TPU v3 chips for 168 hours (7 days), with $8/hour/TPUv3 back then, for a total cost of approx. $43K. It achieves 0.256525 CORE score, which is an ensemble metric introduced in the DCLM paper over 22 evaluations like ARC/MMLU/etc. As of the last few improvements merged into nanochat (many of them originating in modded-nanogpt repo), I can now reach a higher CORE score in 3.04 hours (~$73) on a single 8XH100 node. This is a 600X cost reduction over 7 years, i.e. the cost to train GPT-2 is falling approximately 2.5X every year. I think this is likely an underestimate because I am still finding more improvements relatively regularly and I have a backlog of more ideas to try. A longer post with a lot of the detail of the optimizations involved and pointers on how to reproduce are here: github.com/karpathy/nanoc… Inspired by modded-nanogpt, I also created a leaderboard for "time to GPT-2", where this first "Jan29" model is entry #1 at 3.04 hours. It will be fun to iterate on this further and I welcome help! My hope is that nanochat can grow to become a very nice/clean and tuned experimental LLM harness for prototyping ideas, for having fun, and ofc for learning. The biggest improvements of things that worked out of the box and simply produced gains right away were 1) Flash Attention 3 kernels (faster, and allows window_size kwarg to get alternating attention patterns), Muon optimizer (I tried for ~1 day to delete it and only use AdamW and I couldn't), residual pathways and skip connections gated by learnable scalars, and value embeddings. There were many other smaller things that stack up. Image: semi-related eye candy of deriving the scaling laws for the current nanochat model miniseries, pretty and satisfying!
English

I haven’t tried it yet, but I suspect Kimi 2.5’s agent will have a very different sub-agent spawning policy. Given RL explicitly optimizing task decomposition for parallelization, it may learn something like a "information map-reduce" pipeline: split, search, summarize, merge
English
Got to say I really like the RL-induced agent swarm idea. It unlocks a core advantage computers have over humans: parallelism. Humans are naturally constrained to doing many things sequentially, and most current prompt-based agent systems still(more or less) mirror that pattern.
Kimi.ai@Kimi_Moonshot
🥝 Meet Kimi K2.5, Open-Source Visual Agentic Intelligence. 🔹 Global SOTA on Agentic Benchmarks: HLE full set (50.2%), BrowseComp (74.9%) 🔹 Open-source SOTA on Vision and Coding: MMMU Pro (78.5%), VideoMMMU (86.6%), SWE-bench Verified (76.8%) 🔹 Code with Taste: turn chats, images & videos into aesthetic websites with expressive motion. 🔹 Agent Swarm (Beta): self-directed agents working in parallel, at scale. Up to 100 sub-agents, 1,500 tool calls, 4.5× faster compared with single-agent setup. - 🥝 K2.5 is now live on kimi.com in chat mode and agent mode. 🥝 K2.5 Agent Swarm in beta for high-tier users. 🥝 For production-grade coding, you can pair K2.5 with Kimi Code: kimi.com/code - 🔗 API: platform.moonshot.ai 🔗 Tech blog: kimi.com/blogs/kimi-k2-… 🔗 Weights & code: huggingface.co/moonshotai/Kim…
English
Muchen Li retweetledi

A few random notes from claude coding quite a bit last few weeks.
Coding workflow. Given the latest lift in LLM coding capability, like many others I rapidly went from about 80% manual+autocomplete coding and 20% agents in November to 80% agent coding and 20% edits+touchups in December. i.e. I really am mostly programming in English now, a bit sheepishly telling the LLM what code to write... in words. It hurts the ego a bit but the power to operate over software in large "code actions" is just too net useful, especially once you adapt to it, configure it, learn to use it, and wrap your head around what it can and cannot do. This is easily the biggest change to my basic coding workflow in ~2 decades of programming and it happened over the course of a few weeks. I'd expect something similar to be happening to well into double digit percent of engineers out there, while the awareness of it in the general population feels well into low single digit percent.
IDEs/agent swarms/fallability. Both the "no need for IDE anymore" hype and the "agent swarm" hype is imo too much for right now. The models definitely still make mistakes and if you have any code you actually care about I would watch them like a hawk, in a nice large IDE on the side. The mistakes have changed a lot - they are not simple syntax errors anymore, they are subtle conceptual errors that a slightly sloppy, hasty junior dev might do. The most common category is that the models make wrong assumptions on your behalf and just run along with them without checking. They also don't manage their confusion, they don't seek clarifications, they don't surface inconsistencies, they don't present tradeoffs, they don't push back when they should, and they are still a little too sycophantic. Things get better in plan mode, but there is some need for a lightweight inline plan mode. They also really like to overcomplicate code and APIs, they bloat abstractions, they don't clean up dead code after themselves, etc. They will implement an inefficient, bloated, brittle construction over 1000 lines of code and it's up to you to be like "umm couldn't you just do this instead?" and they will be like "of course!" and immediately cut it down to 100 lines. They still sometimes change/remove comments and code they don't like or don't sufficiently understand as side effects, even if it is orthogonal to the task at hand. All of this happens despite a few simple attempts to fix it via instructions in CLAUDE . md. Despite all these issues, it is still a net huge improvement and it's very difficult to imagine going back to manual coding. TLDR everyone has their developing flow, my current is a small few CC sessions on the left in ghostty windows/tabs and an IDE on the right for viewing the code + manual edits.
Tenacity. It's so interesting to watch an agent relentlessly work at something. They never get tired, they never get demoralized, they just keep going and trying things where a person would have given up long ago to fight another day. It's a "feel the AGI" moment to watch it struggle with something for a long time just to come out victorious 30 minutes later. You realize that stamina is a core bottleneck to work and that with LLMs in hand it has been dramatically increased.
Speedups. It's not clear how to measure the "speedup" of LLM assistance. Certainly I feel net way faster at what I was going to do, but the main effect is that I do a lot more than I was going to do because 1) I can code up all kinds of things that just wouldn't have been worth coding before and 2) I can approach code that I couldn't work on before because of knowledge/skill issue. So certainly it's speedup, but it's possibly a lot more an expansion.
Leverage. LLMs are exceptionally good at looping until they meet specific goals and this is where most of the "feel the AGI" magic is to be found. Don't tell it what to do, give it success criteria and watch it go. Get it to write tests first and then pass them. Put it in the loop with a browser MCP. Write the naive algorithm that is very likely correct first, then ask it to optimize it while preserving correctness. Change your approach from imperative to declarative to get the agents looping longer and gain leverage.
Fun. I didn't anticipate that with agents programming feels *more* fun because a lot of the fill in the blanks drudgery is removed and what remains is the creative part. I also feel less blocked/stuck (which is not fun) and I experience a lot more courage because there's almost always a way to work hand in hand with it to make some positive progress. I have seen the opposite sentiment from other people too; LLM coding will split up engineers based on those who primarily liked coding and those who primarily liked building.
Atrophy. I've already noticed that I am slowly starting to atrophy my ability to write code manually. Generation (writing code) and discrimination (reading code) are different capabilities in the brain. Largely due to all the little mostly syntactic details involved in programming, you can review code just fine even if you struggle to write it.
Slopacolypse. I am bracing for 2026 as the year of the slopacolypse across all of github, substack, arxiv, X/instagram, and generally all digital media. We're also going to see a lot more AI hype productivity theater (is that even possible?), on the side of actual, real improvements.
Questions. A few of the questions on my mind:
- What happens to the "10X engineer" - the ratio of productivity between the mean and the max engineer? It's quite possible that this grows *a lot*.
- Armed with LLMs, do generalists increasingly outperform specialists? LLMs are a lot better at fill in the blanks (the micro) than grand strategy (the macro).
- What does LLM coding feel like in the future? Is it like playing StarCraft? Playing Factorio? Playing music?
- How much of society is bottlenecked by digital knowledge work?
TLDR Where does this leave us? LLM agent capabilities (Claude & Codex especially) have crossed some kind of threshold of coherence around December 2025 and caused a phase shift in software engineering and closely related. The intelligence part suddenly feels quite a bit ahead of all the rest of it - integrations (tools, knowledge), the necessity for new organizational workflows, processes, diffusion more generally. 2026 is going to be a high energy year as the industry metabolizes the new capability.
English
@QihangZhang00 LLMs are universal compressors — but how can we compress out-of-distribution data efficiently and effectively?
Check out our paper “Test-Time Steering for Lossless Text Compression via Weighted Product of Experts” appearing at EMNLP 2025.
English
Muchen Li retweetledi

Introducing our work Test-Time Steering for Lossless Text Compression via Weighted Product of Experts — a simple way to combine LLMs with traditional compressors so the ensemble is never worse than the best expert, and often better.
I will be at Hall C this afternoon! (0/N)

English

Life update ✨
I’ll be joining @umdcs as faculty starting Spring 2026!
I’m looking for motivated students (undergrad, MS, PhD) and postdocs interested in robotic manipulation, tactile sensing, and learning-driven hardware design.
Excited to build my group at UMD—let’s connect!
UMD Department of Computer Science@umdcs
📢 @umdcs is welcoming 8 new faculty in 2025–26 with expertise in AI policy, robotics, bioinformatics, vision, language models, simulation & sound design. They’ll strengthen research & teaching across computing. Read more: go.umd.edu/New-Faculty7-2…
English