Logan Grasby
2.4K posts


Logan Grasby
@LoganGrasby
Training something. Prev: ML Eng @ Cloudflare


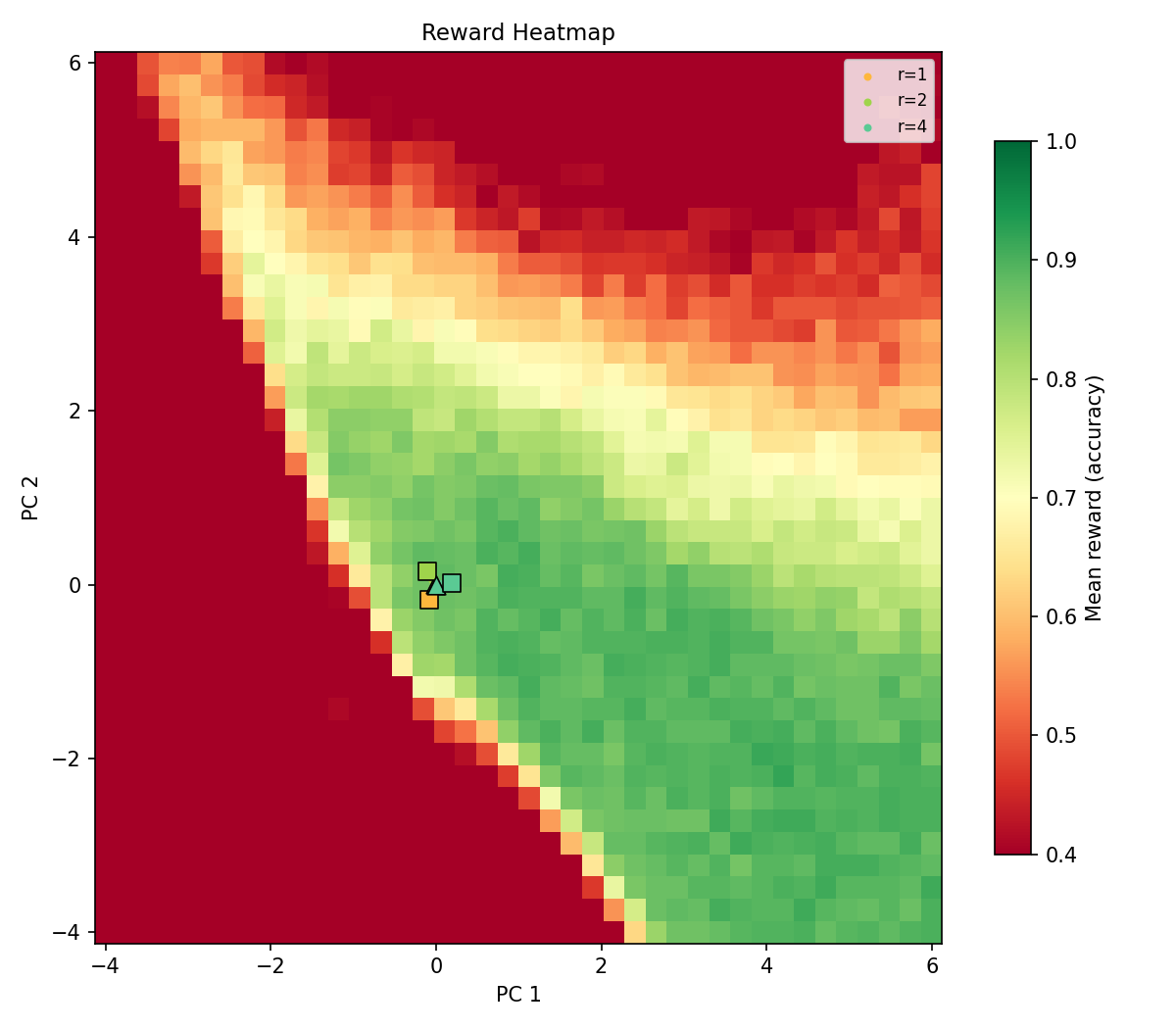
can we train a model in single RL step? During recent experiments, @Logangrasby found that a single step of OAPL increased model performance from ~0 to 48% on a clinical reasoning and prediction task. Turns out, data staleness might matter less than we think. with @pathos :

Everyone is slowly coming to this realization, and I assure you, no one is running multitudes of agents overnight. No one that is doing anything of substance at least. There _are_ people pretending to be scientists, or fully caught up in their drug infused AI overdose, that think their slop machines are changing the world. They're not tho, and they're just wasting a bunch of money and compute to create a lot of LoC that will just get thrown away. The state of the art is still "can we even one shot a production quality patch that we wont regret later", and its rarer than you'd expect based on discourse.
Talking to smarter folks than me, I'm convinced many of the AI folks in my timeline are full of shit. Nobody is "running 20 agents over night" and building stuff for actual users. Maybe some are building internal tools or disposable software. Maybe. But building software people like using? That doesn't get hacked on day one or blow up after the 3rd user? Nope. I don't even understand what that's supposed to look like. Do you work out a 57 pages document that perfectly describes what you want to build and then summon 14 agents and have them run wild for 6 hours? And what comes out on the other end isn't a broken pile of shit? Nope. Not buying it. PS: it may also be that I have an IQ of 82 and can't figure it out.

We post-trained MedGemma to be SoTA in visual medicine ddx, outperforming Opus 4.6, Gemini 3.1 and GPT-5.4 while running at ~1/30th the cost. @getnolla Part 1 - improving visual reasoning 🧵1/6



New in Claude Code: auto mode. Instead of approving every file write and bash command, or skipping permissions entirely, auto mode lets Claude make permission decisions on your behalf. Safeguards check each action before it runs.


1/4 LLMs solve research grade math problems but struggle with basic calculations. We bridge this gap by turning them to computers. We built a computer INSIDE a transformer that can run programs for millions of steps in seconds solving even the hardest Sudokus with 100% accuracy


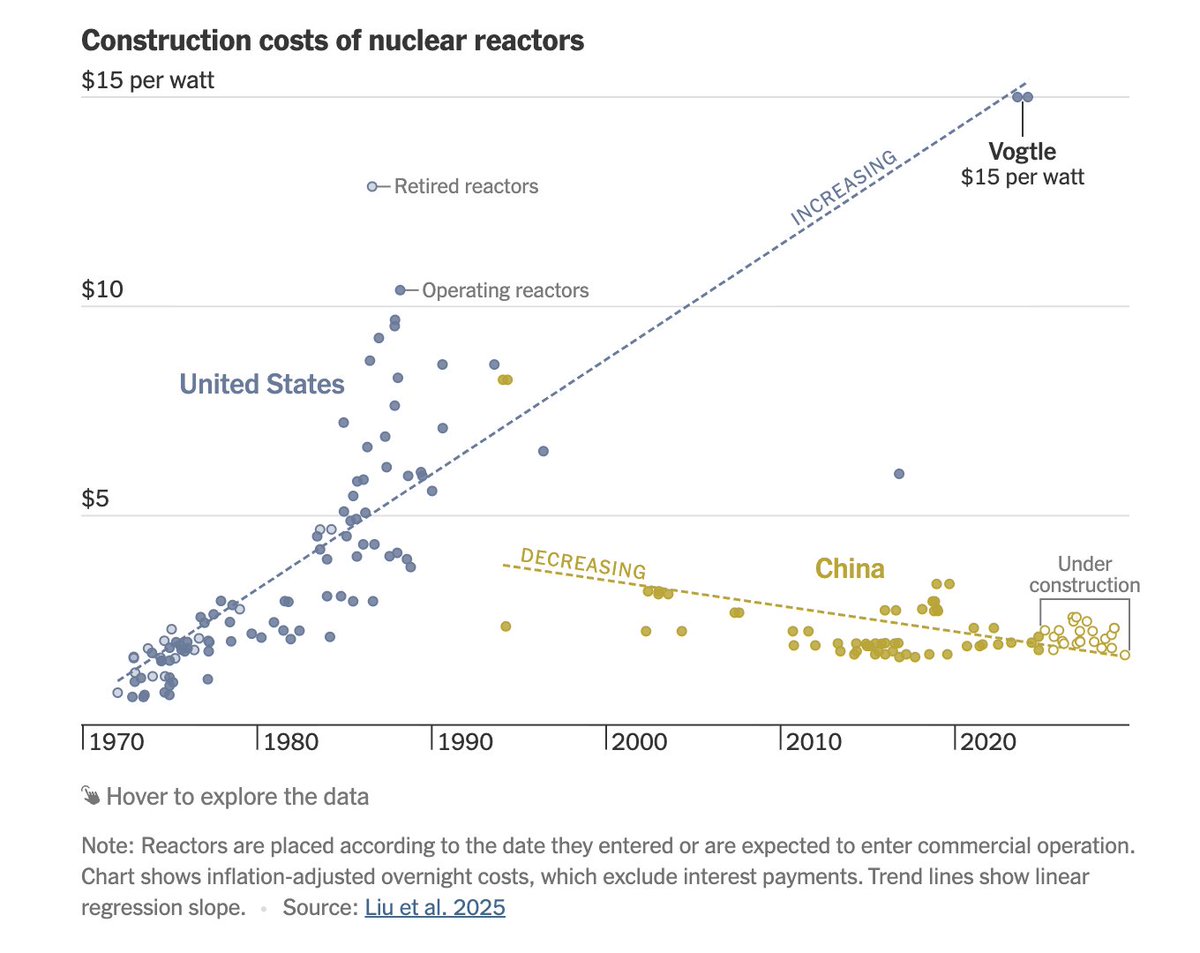

Whatever you think of China, their recent drug development success is incredibly impressive. Pharmaceutical developments were practically unheard of in China prior to their 2016 reforms, and now they're either ahead of the U.S. or close to it. From zero to leading in <10 years.