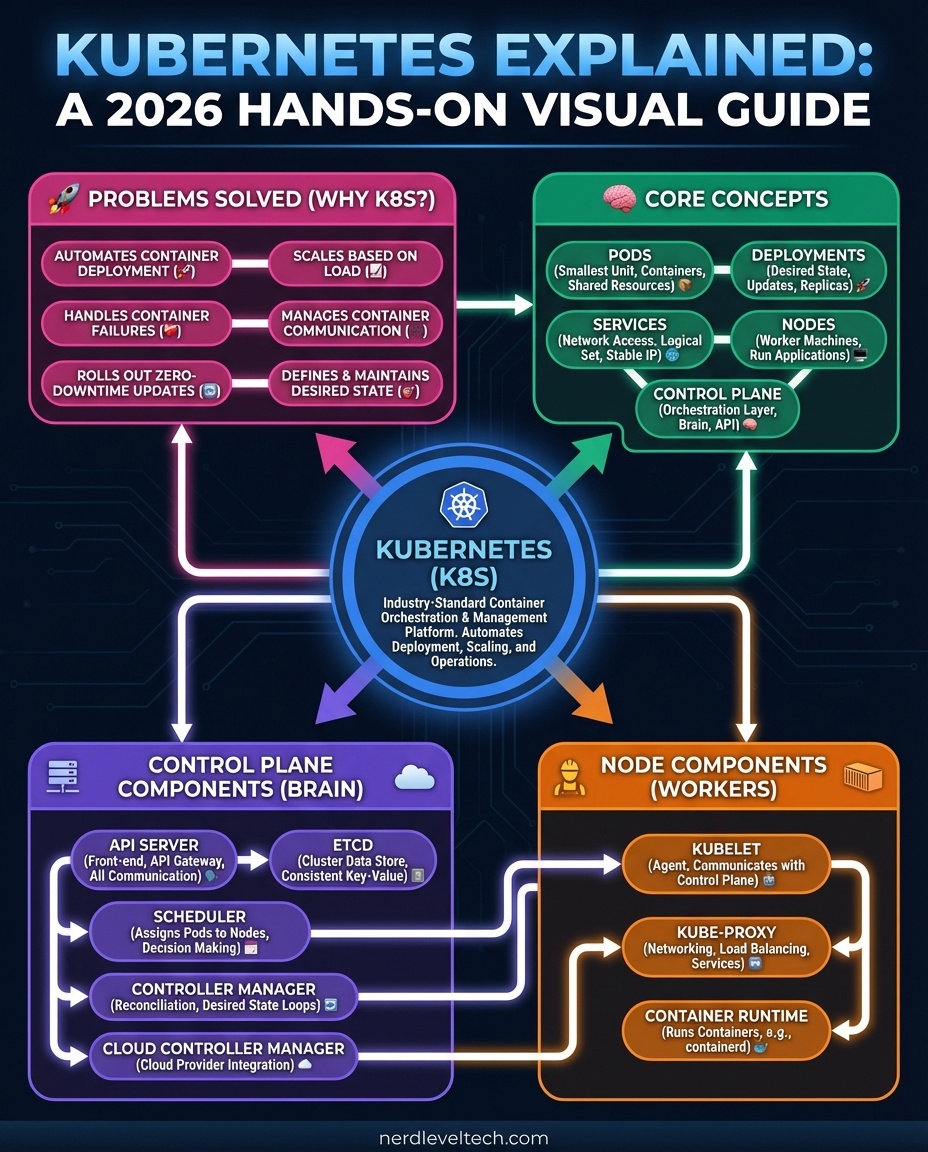
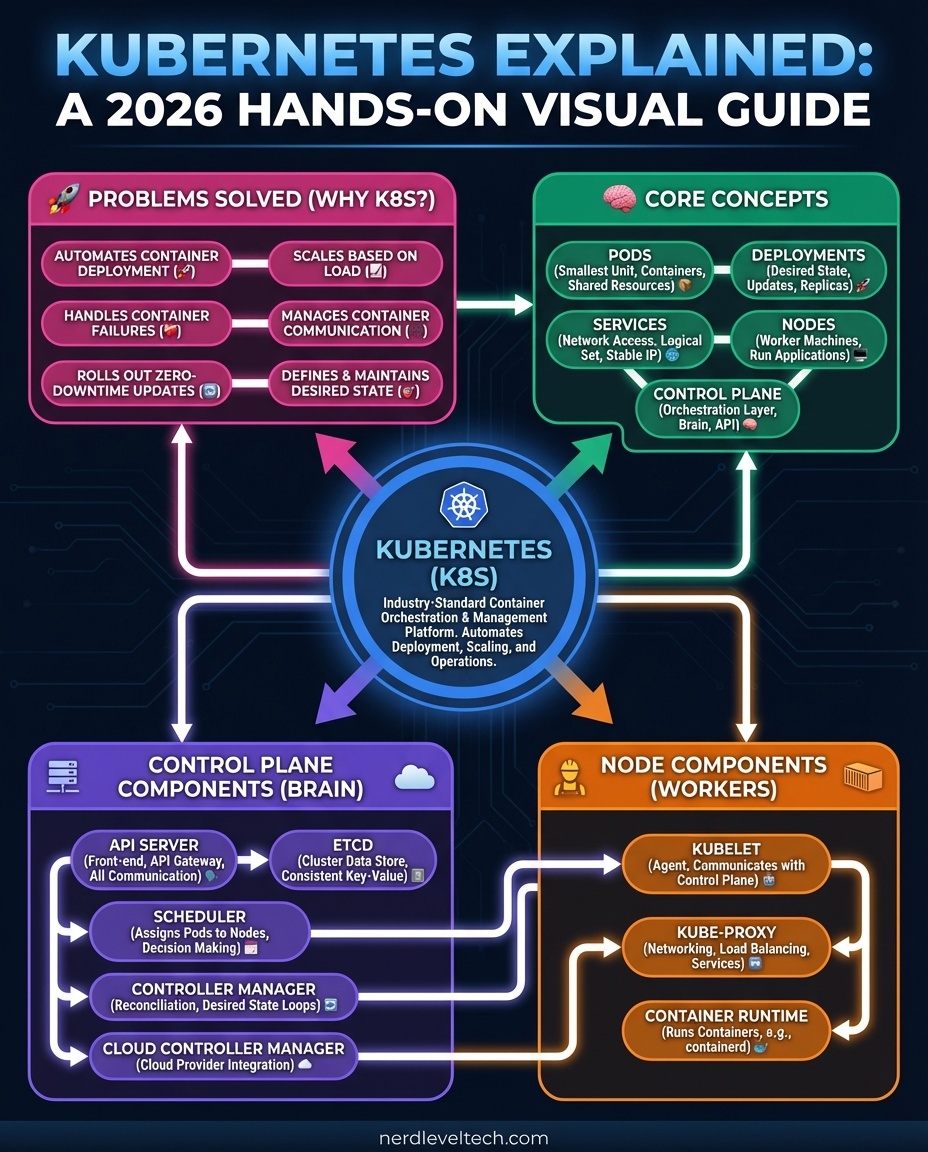
Sabitlenmiş Tweet

Stop adding Redis for simple real-time presence. Postgres LISTEN/NOTIFY handles it in ~120 lines of Node.js. The trade-off: an 8000-byte payload cap and a global mutex that serializes commits. Use a dedicated Client, not a pool, or your subscriptions will silently die.
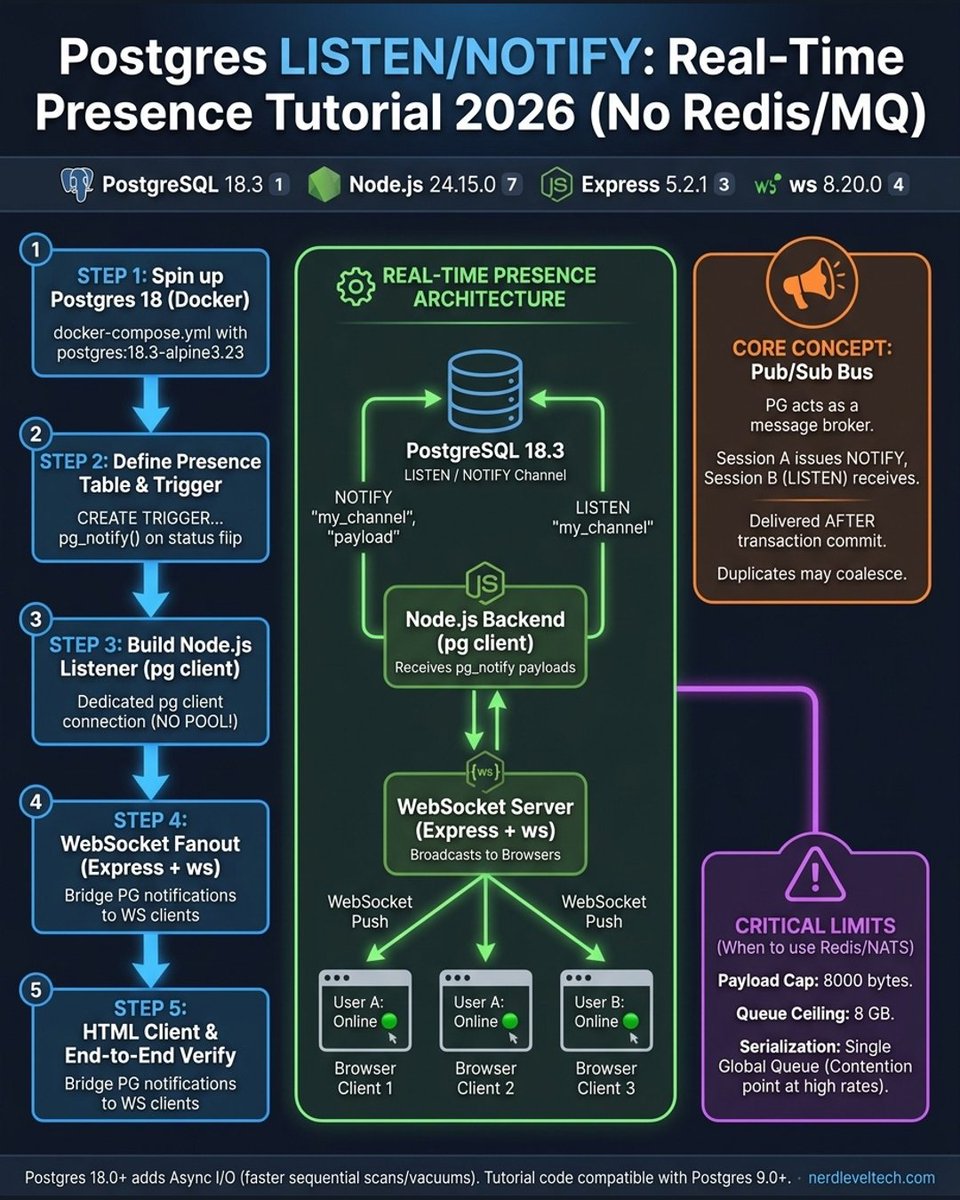
English