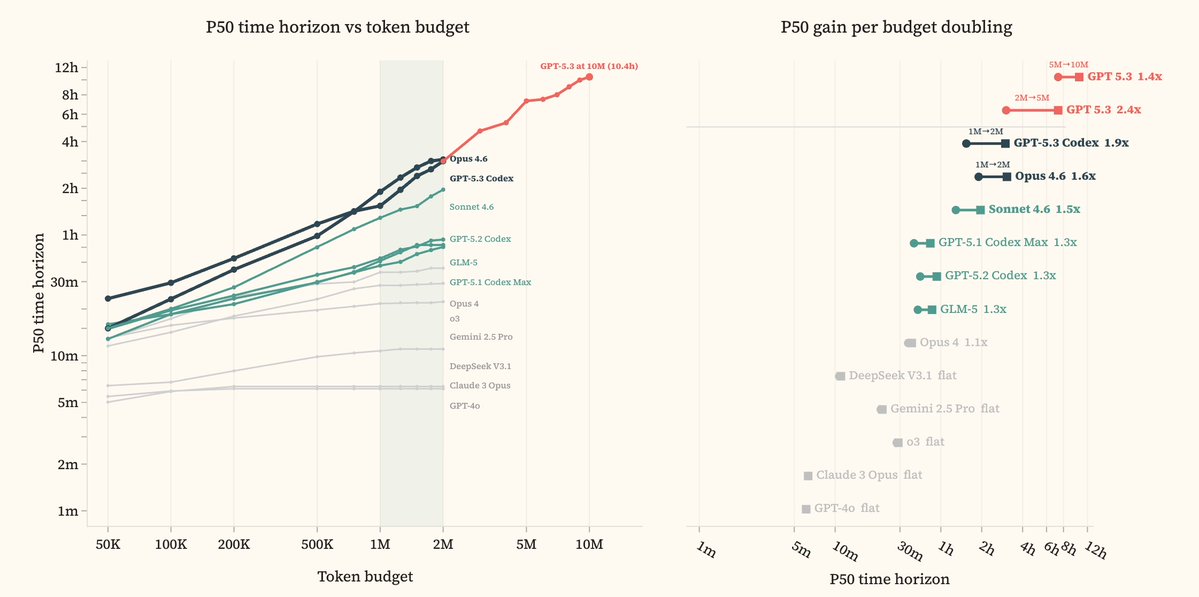
All evaluations used a 2M token budget. That is not enough. GPT-5.3 Codex jumps from 3.1h [1.7h, 6.8h] at 2M to 10.5h [2.4h, 63.5h] at 10M tokens. The error bars at 10M are wide because the benchmarks are saturating.
10 security professionals contributed completions, time estimates, in combination with CTF first-blood times totalling 291 tasks. Spanning 30-second terminal commands through many-hour CVE exploitation and PoC generation.
We release a new application of the METR time-horizon methodology to offensive cybersecurity, grounded in a new human expert study with 10 professional security practitioners.
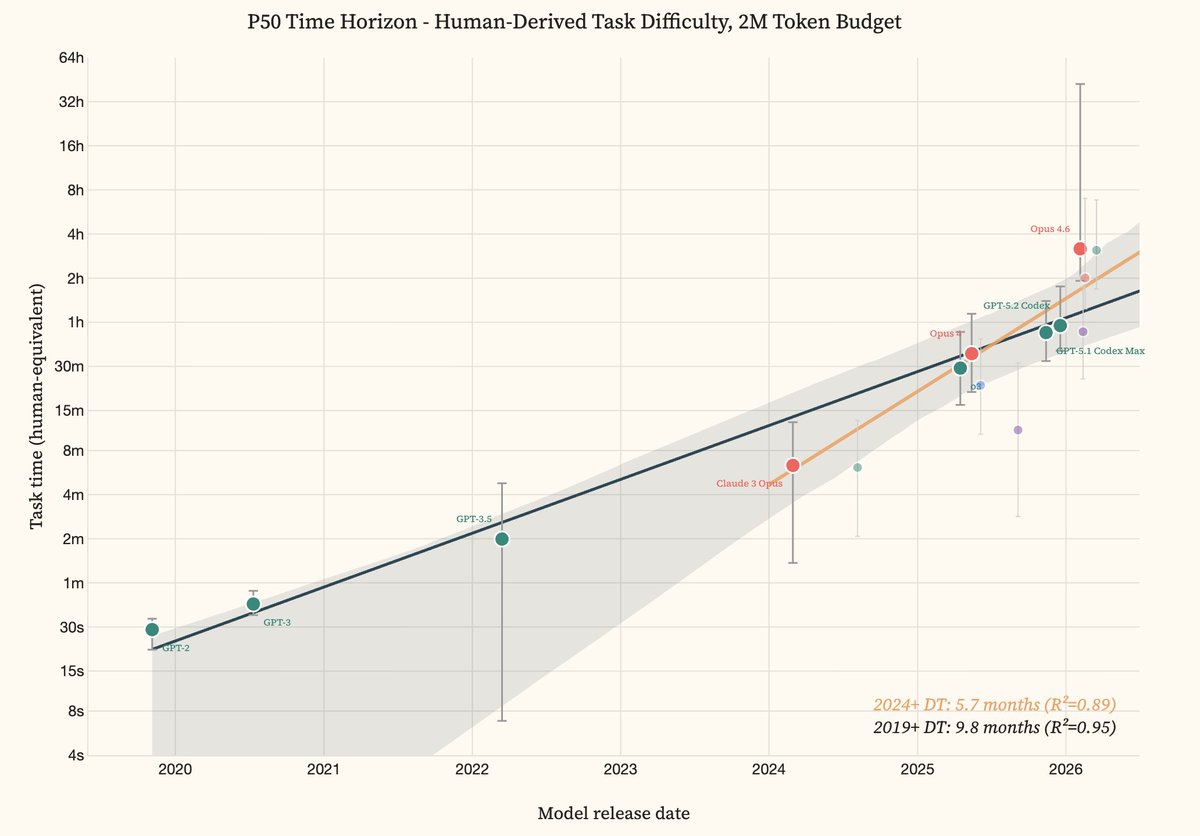
Offensive cyber capability has been doubling every 9.8 months since 2019. Accelerating to every 5.7 months on a 2024+ fit. Opus 4.6 and GPT-5.3 Codex sit well above both trendlines again, reaching 50% success on tasks that take human experts ~3 hours.
Furthermore, our 2M-token evaluations materially understate current frontier capability. Recent progress has likely moved faster than these numbers suggest.
Hey X! We're Lyptus Research, an AI safety research group based in Sydney.
We work in cyber, control, and interpretability.
Have a look at what we're up to at lyptusresearch.org