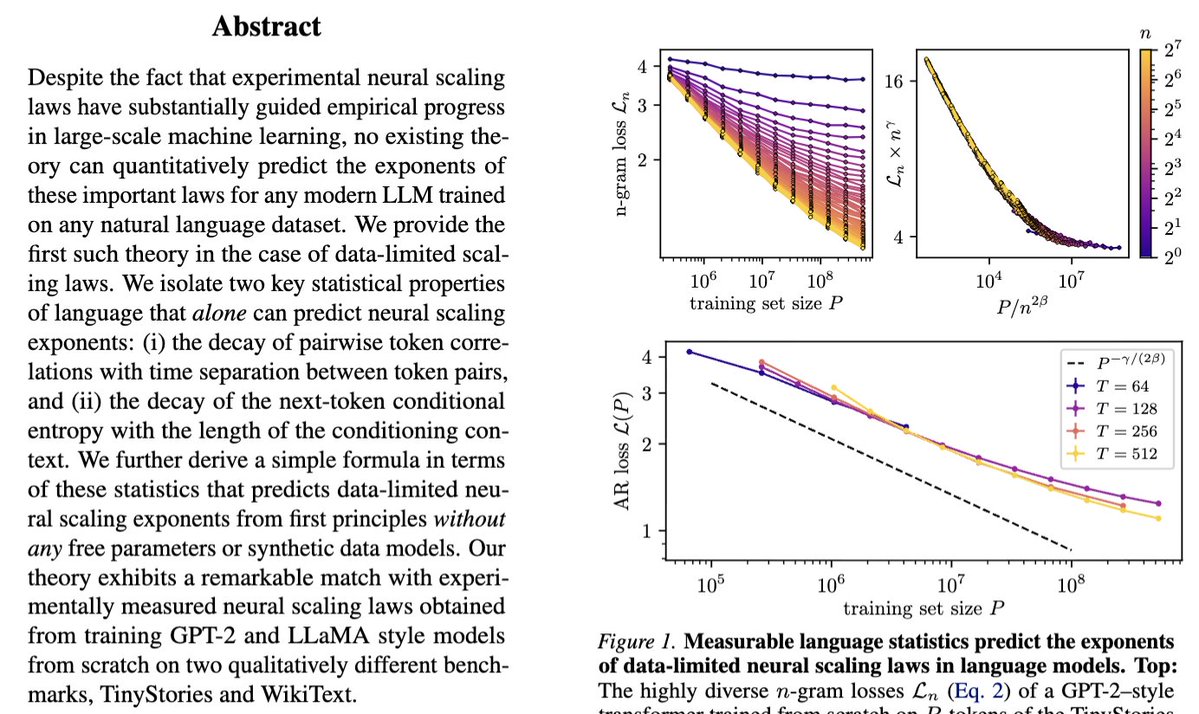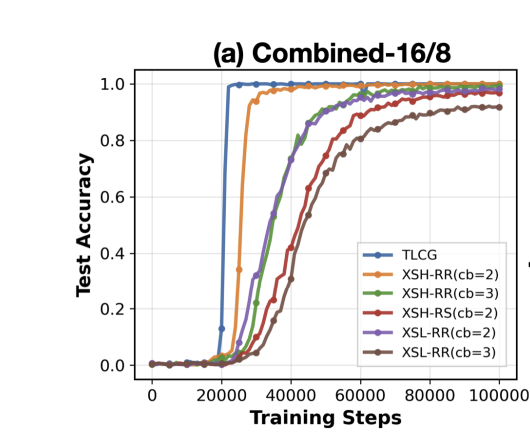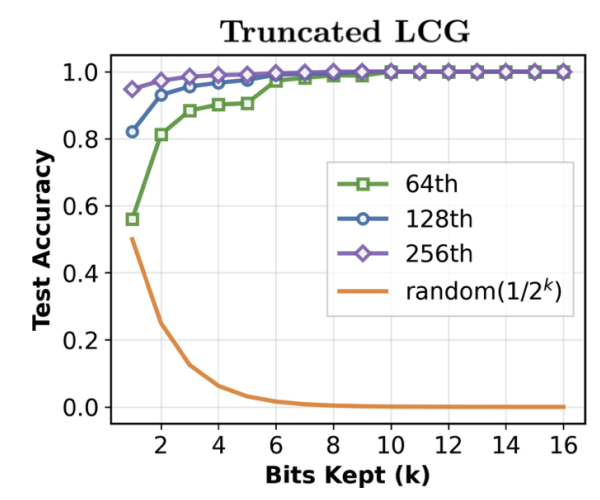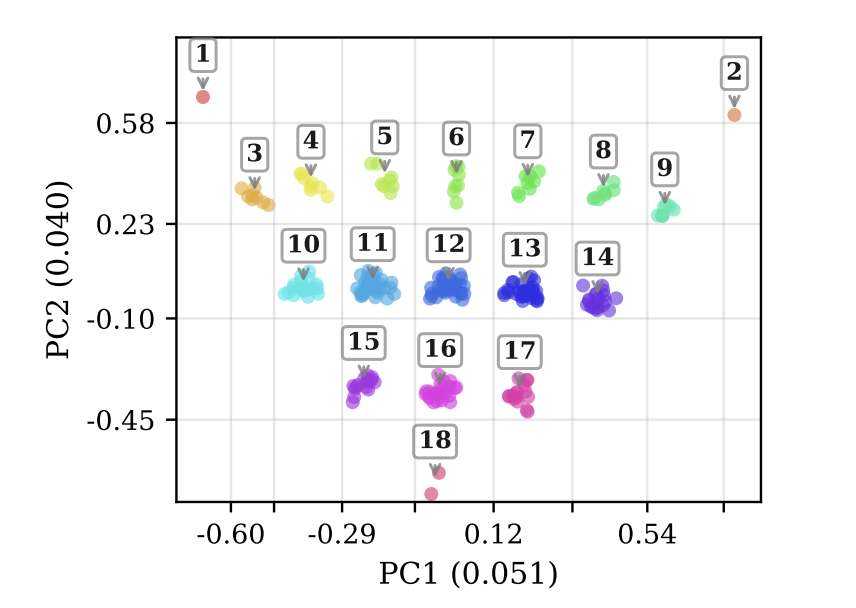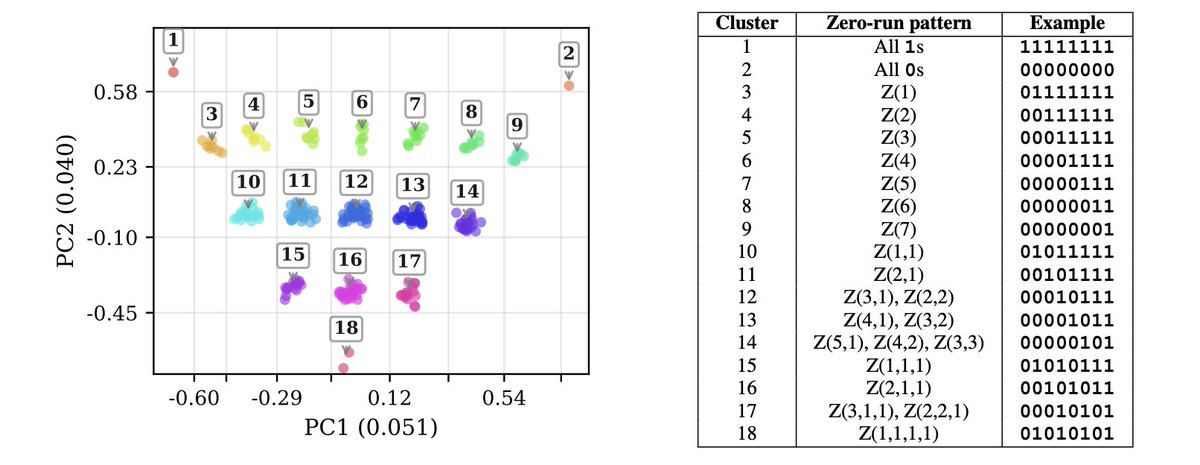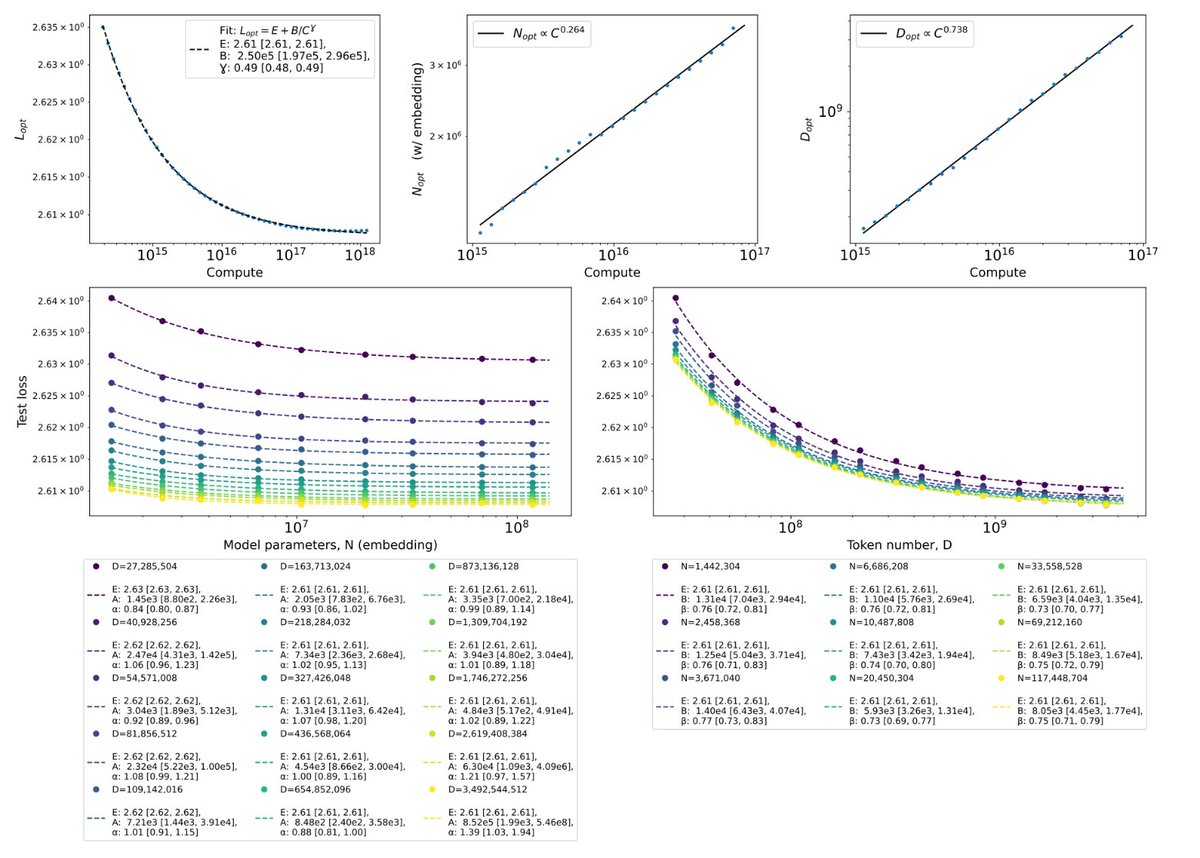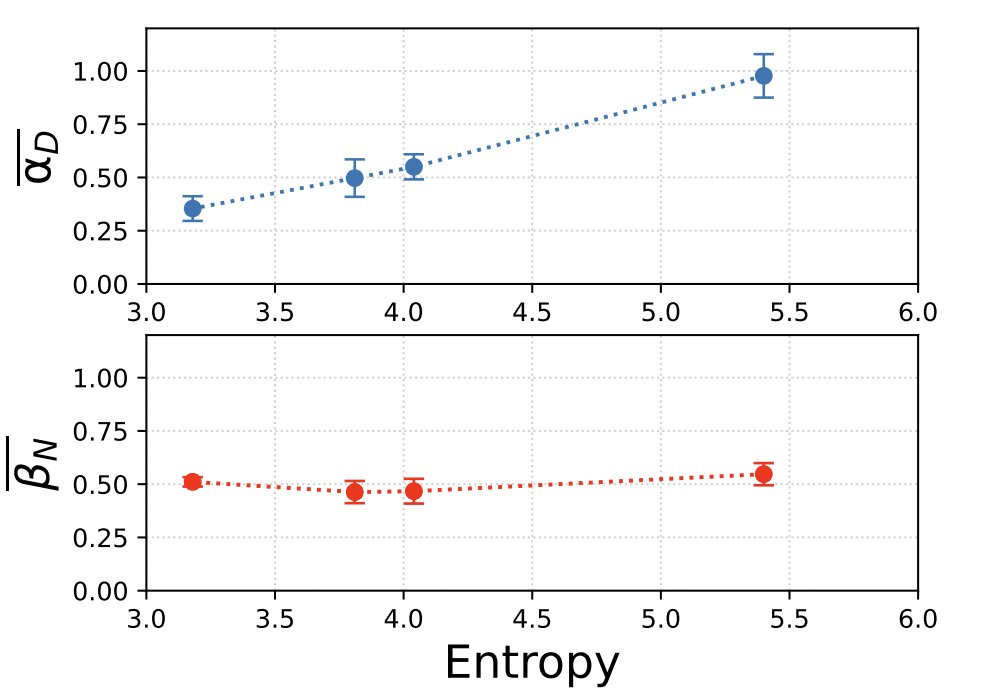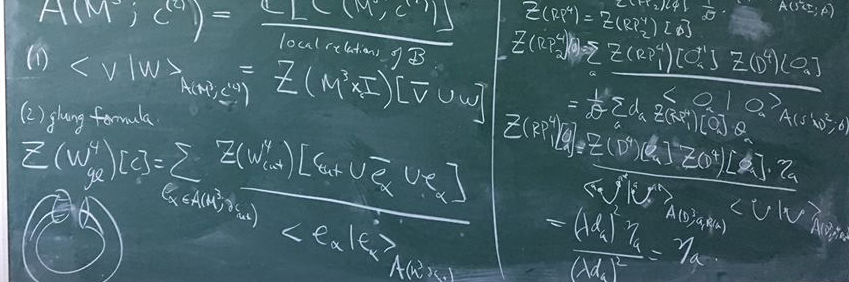
Sabitlenmiş Tweet

An absolutely incredible, highly interconnected web of ideas connecting some of the most important discoveries of late twentieth century physics and mathematics. This is an extremely abridged, biased history (1970-2010) with many truly ground-breaking works still not mentioned:
English