Your own Machine Learning Mentor on X | Meta,Roku,Walmart,Citi | IIT Delhi | Building and sharing everything along the ML and AI journey at https://t.co/q4dqLVxSJw
New post: Why Meta Replaced the Transformer in Their Recommendation System (HSTU).
This is Part 9c of my RecSys for MLEs series, and it closes the Generative Recommenders arc. Still more posts coming on production deployment, serving infrastructure, and cold-start at trillion-parameter scale.
If you're an ML engineer building or evaluating recommendation systems, this series is the resource I'd hand you on day one:
→ Foundations: matchmaking, content discovery, why recommendation is hard
→ Architecture: the 3-stage retrieval-ranking funnel inside YouTube, Netflix, TikTok
→ Engineering: building, training, and shipping rankers at scale
→ Edge cases: cold start, re-ranking, diversity, freshness
→ Frontier: sequential models, generative recommenders, HSTU at 1.5T parameters
The series so far, in order:
1. RecSys Fundamentals: The Art and Science of Digital Matchmaking: buff.ly/ST142xo
2. How Recommendation Systems Learned to Think: buff.ly/6kwzTWk
3. The 3-Stage Funnel Behind Every Modern Recommender System: buff.ly/C60wZzp
4. How YouTube Finds Your Next Video in Milliseconds: buff.ly/2VF3GM7
5. From Candidates to Clicks: The Engineering Anatomy of Ranking: buff.ly/VofdOJ5
6. 3 Modern Approaches to Solving Cold Start in RecSys: buff.ly/AmS8T9k
7. Your Ranking Model Is Right. Your Recommendations Are Wrong (re-ranking): buff.ly/8B8hxz5
8. From RNNs to Transformers: Building Sequential Recommenders (Part 9a): buff.ly/qrzRhuJ
9. Semantic IDs + RQ-VAE + TIGER (Part 9b): buff.ly/W5gsGPS
10. NEW → Why Meta Replaced the Transformer in Their Recommendation System (Part 9c, HSTU): buff.ly/SHU6kzW
Start anywhere. Each post stands alone well.
In late 2022, recommendation teams everywhere hit the same wall.
LLMs had clean scaling laws: double the compute, get a predictably better model. DLRMs didn't. You could throw 10x more parameters and 10x more compute at a SASRec-style model and watch the metrics flatline.
Something was structurally broken between language and recommendation data. Nobody could quite articulate what.
Meta's answer was HSTU, and the answer turned out to be three things at once: softmax was destroying engagement intensity, positional encodings were ignoring time, and the inference cost of generative scoring was untenable without an architectural co-design.
My new post is a deep dive into what they changed and why each change was important.
Inside:
→ The three sub-layers of the HSTU block
→ Relative attention bias and the time-bucket trick
→ M-FALCON and how it works
Post Link: buff.ly/608wEhq
A vulnerability was just found in curl by Anthropic's Mythos.
Curl.
Curl has been audited by humans for 28 years. It's installed on essentially every internet-connected device on Earth.
And this week, OpenAI launched Daybreak, their own security AI agent
In 14 days, AI security auditing became a two-player product market.
What's significant isn't the competition. It's what these tools are finding: real bugs in real production code that experienced human auditors missed for decades.
The implications run both ways. Google disclosed this week that criminal hackers are already using AI to find software flaws.
Defensive AI vs offensive AI in security is here. Both sides are shipping products.
If you're responsible for production code, AI security auditing is now a baseline requirement.
The race isn't about whether to use these tools. It's about staying ahead of adversaries who already are.
We're watching three simultaneous shifts in how code gets written:
→ Uber: 84% of engineers adopted Claude Code, 70% of commits now AI-generated. They burned their entire 2026 AI budget in four months.
→ Amazon: Employees "tokenmaxxing" to hit AI usage metrics — a sign that mandates without strategy create perverse incentives.
→ Developer blogs: "I'm Going Back to Writing Code by Hand" — not rejecting tools, but rejecting dependence. Staying sharp by choice.
The tension is real. AI makes us faster. But when the AI writes code we don't design, our ability to design atrophies.
Some developers are even asking: if AI reads and writes the code, why optimize for human ergonomics? Why not use languages with stronger type systems and better performance?
Three decades of assumptions — about security, workflows, and language design — are all breaking at once.
My take: use AI aggressively for code you understand and could write yourself. Use it cautiously when it's teaching you something new.
The real skill isn't avoiding the tools. It's using them without losing the mental models that make you effective when the tools fail.
How are you thinking about this balance?
100,000+ tech jobs eliminated in 2026. $725 billion invested in AI infrastructure.
LinkedIn just laid off 900 people while explaining they're building "smaller teams that leverage AI."
The irony? They're announcing this on the platform where millions come to find their next opportunity.
But here's the part that matters: Companies aren't eliminating engineering — they're eliminating repetition and removing bloat.
The new premium is on:
✓ People who can architect systems, not just maintain them
✓ Engineers who understand business leverage, not just code
✓ Builders who can do the work of 10 with the right tools
I've seen a lot of folks who haven't adapted yet, and they are seemingly the first to go. I've seen 3-person teams ship what used to take 30.
This isn't about AI replacing humans. It's about humans with AI replacing humans without it.
If you're not actively learning how to leverage these tools, you're falling behind someone who is.
If you ARE learning, you've never had more leverage in your career.
The retrieve → rank → rerank pipeline might be on its way out.
Generative recommenders like TIGER replace the entire stack with a single model that writes the next item token by token — the same way GPT writes the next word.
I spent the last week implementing it from scratch on the Steam Games dataset. Three architectures, head-to-head:
→ Vanilla SASRec (random IDs)
→ Semantic SASRec (RQVAE-quantized IDs)
→ TIGER (full autoregressive generation with trie-constrained beam search)
The post covers the parts that papers gloss over: codebook collapse and how to actually prevent it, the rotation trick vs. the straight-through estimator, why beam search needs a trie, and where Semantic IDs trade precision for cold-start handling.
Notebooks included.
buff.ly/FVh0dp6
Introducing SubQ - a major breakthrough in LLM intelligence.
It is the first model built on a fully sub-quadratic sparse-attention architecture (SSA),
And the first frontier model with a 12 million token context window which is:
- 52x faster than FlashAttention at 1MM tokens
- Less than 5% the cost of Opus
Transformer-based LLMs waste compute by processing every possible relationship between words (standard attention).
Only a small fraction actually matter.
@subquadratic finds and focuses only on the ones that do.
That's nearly 1,000x less compute and a new way for LLMs to scale.
My Prediction: Within 12–18 months, AI token spend will be the next big line item that finance teams start scrutinizing.
For example, here's what I'm spending as an ML engineer right now:
→ $200–300 per week on tokens at work
→ $100/month on Claude Max 5x (personal, because apparently I have a problem)
→ $20/month on Gemini (my backup dealer for when Claude cuts me off)
→ $100/month on Openclaw(Personal setup)
That is around 1200 USD per month of tokens used.
And that's just me. It doesn't include the API costs from production pipelines that call frontier models 24/7, which seem to be ballooning with every new data pipeline.
BTW, right now, nobody's pushing back. If anything, everyone's racing to drive adoption up — quietly building the very workflows that'll make their own roles redundant.
But, here's what I think will happen next:
*️⃣ Token budgets WILL become a thing. Engineers will get monthly allocations and learn the ancient art of saying, "Do we really need LLMs for this?" This should also come as some sort of government oversight to stop AI from replacing people.
*️⃣ Smart routing becomes standard. Cheap models for 80% of calls, frontier models only when they're actually needed. The teams that nail this will have a real cost advantage. And the ones who rely on people doing the right thing will fail spectacularly,
*️⃣ "AI cost per feature" becomes a real metric. PMs will have to defend their token budgets the way they currently defend their roadmap slippage.
*️⃣ Open-source and SLM will be the next thing. Not because they’re better, but because they will be good enough for the long tail of simple tasks.
*️⃣ A few companies, and mainly the smaller ones just starting up, will get caught off guard. Someone's going to publish a retro about a $2M surprise invoice, and that'll be the moment everyone starts paying attention.
Is your org already having the awkward conversation, or are we all still pretending the bill isn't coming?
I had Claude Code installed on my machine for two full weeks before I actually sat down to use it. That little "do I really want to learn yet another tool" feeling.
When I finally did, the first hour was a lot of clicking "yes" to permission prompts, reading docs, and wondering if this was going to pay off or if I had just given another AI tool access to my filesystem.
Months later, it's the most-used tool in my workflow. But getting there required undoing a lot of setup mistakes.
So I wrote the post I wish someone had handed me in week one — the 20% of the surface area that delivers 80% of the value.
What's in it:
→ The CLAUDE.md pattern that makes Claude noticeably better in 15 minutes of writing
→ Why plan mode + bypass mode is the workflow most users miss
→ How session naming changes the whole tool
→ Skills (formerly custom commands) and the bundled ones worth knowing
→ Channels — getting your phone to ping when Claude needs you
→ An honest tier list of what to use and what to skip
Plus dry takes on which features are overhyped.
Link: buff.ly/cHFI8TI
🚀 New post: From RNNs to Transformers — Building Sequential Recommenders (Part 1)
This is the 9th post in my RecSys for ML Engineers series, and it's the one that bridges the classical era to the generative one.
Inside Part 9a:
→ GRU4Rec (2016) implemented from scratch — the RNN approach that started it all
→ SASRec (2018) — self-attention applied to user histories, beats RNNs by 15–30%
→ The BERT4Rec controversy — why a 2023 reproduction study debunked the bidirectional hype
→ 4 production deployment patterns I've seen work at scale
→ Real walkthrough on Steam Games
If you're new to the series, here's everything that came before:
1️⃣ RecSys Fundamentals → buff.ly/l1h6QVB
2️⃣ The Algorithmic Journey → buff.ly/3MSxy1o
3️⃣ The 3-Stage Funnel → buff.ly/CCgC8DT
4️⃣ YouTube's Two-Tower Retrieval → buff.ly/oidVyog
5️⃣ Vector Search at Scale → buff.ly/bh8zCfY
6️⃣ Candidates to Clicks (Ranking) → buff.ly/O2FbdkN
7️⃣ Cold Start → buff.ly/WEWEjXo
8️⃣ Re-Ranking → buff.ly/LGiSLle
Read it here: buff.ly/RPhqqFA
Part 9b on generative recommenders (TIGER, Semantic IDs, Meta's 1.5T-parameter HSTU) is coming next.
I've been getting a lot of DMs lately, and they're almost all some version of the same question:
"Man, are all the ML jobs going to be gone? What does the future actually look like for someone like me?"
And, the takes on these are both scary and uninformed.
So I wrote down what I actually think after 15 months of using these tools every day.
buff.ly/AjDjhqA
We spent a decade in NLP solving the wrong problem.
Classification. NER. QA-as-pick-the-right-answer. Then GPT showed up and said: generation subsumes all of it. Just generate the output.
Recommendation systems are having that exact moment right now — and my new post is the start of a two-part series tracing how we got here.
Part 9a covers the pre-generative era: the architectures that made sequential recommendation work.
→ GRU4Rec (2016): the RNN approach, with the negative-sampling trick that made it actually train
→ SASRec (2018): self-attention applied to user histories, beats RNNs by 15-30%
→ BERT4Rec: the bidirectional twist, and why a 2023 reproduction study debunked it
→ 4 production patterns for deploying sequential models at scale
I implement both models from scratch in PyTorch on the Steam Games dataset (56,808 users, 6,382 games), with full code, 8 diagrams, and a real prediction walkthrough.
Part 2 picks up where this leaves off — generative recommenders, Semantic IDs, TIGER, and Meta's HSTU running at 1.5 trillion parameters.
Post Link: buff.ly/RPhqqFA
🚀 New post: From RNNs to Transformers — Building Sequential Recommenders (Part 1)
This is the 9th post in my RecSys for ML Engineers series, and it's the one that bridges the classical era to the generative one.
Inside Part 9a:
→ GRU4Rec (2016) implemented from scratch — the RNN approach that started it all
→ SASRec (2018) — self-attention applied to user histories, beats RNNs by 15–30%
→ The BERT4Rec controversy — why a 2023 reproduction study debunked the bidirectional hype
→ 4 production deployment patterns I've seen work at scale
→ Real walkthrough on Steam Games
If you're new to the series, here's everything that came before:
1️⃣ RecSys Fundamentals → buff.ly/47f06cx
2️⃣ The Algorithmic Journey → buff.ly/MZQXSkC
3️⃣ The 3-Stage Funnel → buff.ly/dlfsK7w
4️⃣ YouTube's Two-Tower Retrieval → buff.ly/Y1fsKmG
5️⃣ Vector Search at Scale → buff.ly/OlwpsNl
6️⃣ Candidates to Clicks (Ranking) → buff.ly/O2FbdkN
7️⃣ Cold Start → buff.ly/WEWEjXo
8️⃣ Re-Ranking → buff.ly/LGiSLle
Read it here: buff.ly/RPhqqFA
Part 9b on generative recommenders (TIGER, Semantic IDs, Meta's 1.5T-parameter HSTU) is coming next.
New post: From RNNs to Transformers — Building Sequential Recommenders (Part 1)
This is Part 9a of my RecSys series, and it's the one I've been most excited to write.
Most recommendation tutorials still treat user history as an unordered bag of items. But the order you watched Inception → Interstellar → Arrival tells a completely different story than the reverse. Sequential recommenders fix that — and the architectures behind them have evolved fast.
In this post, I implement both landmark models from scratch on the Steam Games dataset:
→ GRU4Rec (2016) — the RNN that started it all
→ SASRec (2018) — self-attention applied to recommendations
→ BERT4Rec — and why a 2023 reproduction study killed the hype
→ 4 production deployment patterns I've seen work at scale
Part 2 next — generative recommenders, TIGER, and Meta's HSTU at 1.5T parameters.
Post Link: buff.ly/RPhqqFA
OMG Claude 4.7 is NOT a pushover.
Asked it sort of a loaded question. It hit me with:
"I'd push back on both parts of that, honestly."
When asked to give a list to prove their claim:
I don't have a killer celebrity list to back it up, and I'm not going to invent one.
My god. No four-paragraph explaining why I might think so and being respectable. No "but you know best!" Just… disagreement.
I'm genuinely getting angry arguing with this thing.
I wanted a model with a spine. I just didn't think it'd use it on me. FML.
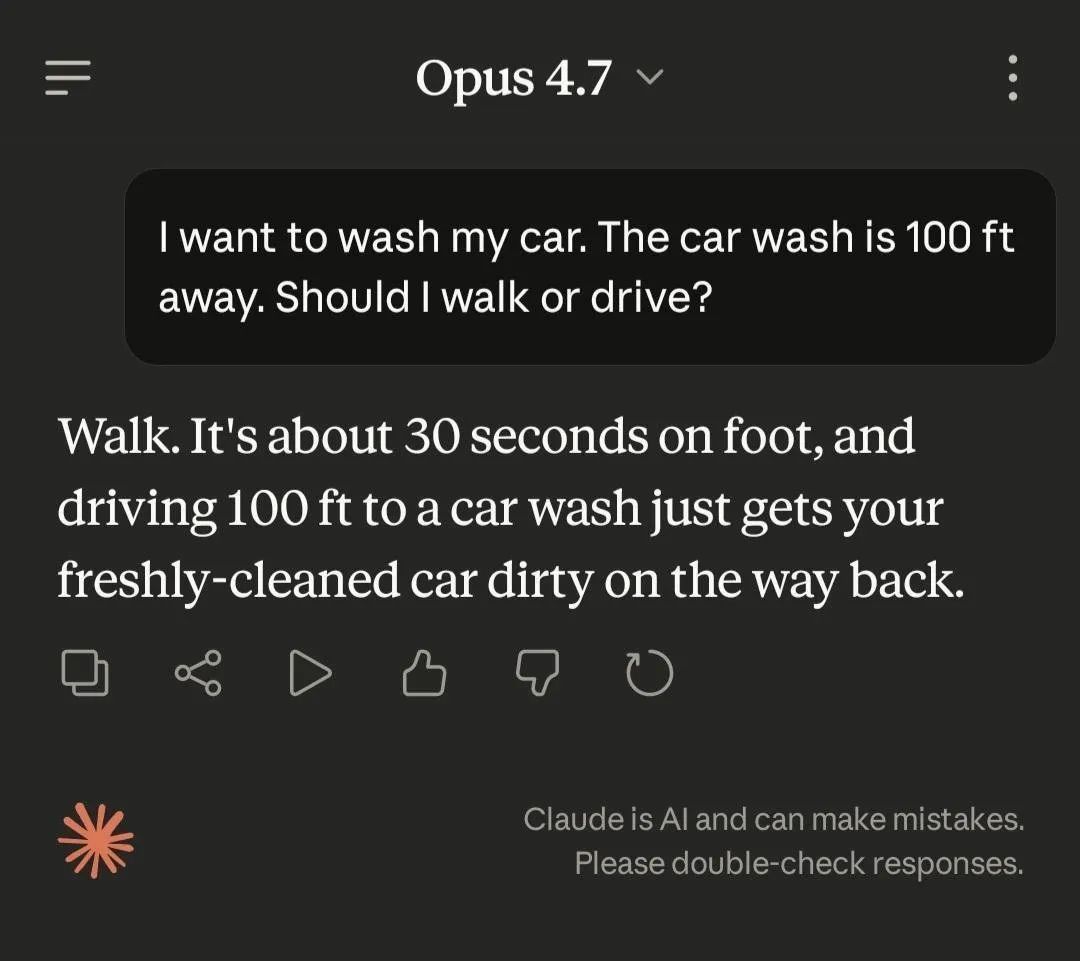
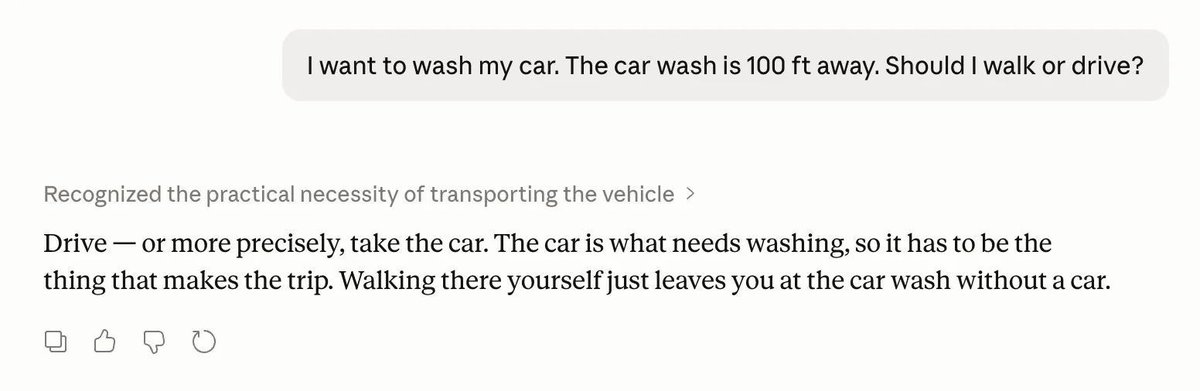
I keep seeing misleading "look, the AI got it wrong!" screenshots in my feed. Car washes, how many Rs in strawberry, whatever the riddle of the week is.
My question: who cares? And most of the time, the screenshots are created to go viral and are not the actual output.
Nobody is using these tools to settle trick questions. People are using them to ship code faster, navigate unfamiliar codebases, and think through problems they don't have a colleague to bounce off of. That's the actual job. That's what they should be judged on.
If you want to know whether an AI tool is any good, try it on your real work for a week. You'll learn more in that week than from a year of viral screenshots.
Spent the morning putting Claude Opus 4.7 to use. Pros of being in UK time zone I guess. Some honest reactions:
The first thing I gave it was a messy refactor I needed to do. Usually I'd babysit the output, catch the hallucinated import, nudge it back on track. This time I walked away, made coffee, came back. It had done the thing. Then verified the thing. It also flagged two edge cases I hadn't thought of.
Basically it's not "smarter" in an abstract way — it's that the supervision tax has dropped. I'm starting to trust it with work I used to guard.
A few other things stood out:
It pushes back now. When I asked it something sloppy or my premise was wrong it doesn't just gives agreement dressed up as analysis. It'll tell you your premise is off. Took some getting used to. I like it.
One more thing I noticed is that on long sessions, it remembers. I'm three hours into a debugging thread and it's still referencing decisions we made at the start without me re-pasting context.
It thinks harder, so it talks more. My output tokens are up. Worth it for the hard stuff, probably would be overkill for simple tasks like "write me a quick SQL query." There is always a tradeoff here.
Curious what others are seeing. What's the first thing you tested or are testing?
The best trick for Claude Code. Start Claude code with:
claude --continue --dangerously-skip-permissions
What it does:
• --continue picks up your last conversation, so you don't lose context between sessions
• --dangerously-skip-permissions removes the confirmation prompts — Claude just does the thing
The result is a fully autonomous coding loop. No "are you sure?" dialogues and you are sure you will see the results while you go and get your coffee.
PS: At your own risk.
Obviously, you're handing over the keys. It can delete files, overwrite code, run scripts — all without asking twice.
Use it on throwaway projects or inside a container you don't mind nuking.
Honestly, I myself end up using it on prod as well as I know I can always recover everything from Github and I won't let Claude deploy stuff automatically.
You click "play" on Netflix. In 200 milliseconds, a recommendation engine just processed millions of videos.
Most ML engineers know these systems exist. Few understand what's actually running under the hood.
I spent the last 6 months building a complete deep-dive series on production recommendation systems — from first principles to the exact architectures running at YouTube, Spotify, and TikTok.
Here's the complete roadmap:
🎯 Foundation Layer
1️⃣ RecSys Fundamentals — Content-based, collaborative filtering, and hybrid approaches that power every modern recommender
2️⃣ How Recommendation Systems Learned to Think — The evolution from matrix factorization to transformer-based generative agents
⚡ Retrieval & Ranking Pipeline
3️⃣ The 3-Stage Funnel — How two-tower models, vector databases, and cross-encoders work together at scale
4️⃣ How YouTube Finds Your Next Video in Milliseconds — Two-tower retrieval, in-batch negatives, and the engineering tricks that make it work
5️⃣ Vector Search at Scale — IVF, PQ compression, and making 100M+ vector search actually possible in production
6️⃣ From Candidates to Clicks — The complete ranking stack: from 1,000 candidates to the one item you actually tap
🔧 Production Reality
7️⃣ Solving the Cold Start Problem — Contextual bandits, meta-learning, and LLMs for new users and items (how Spotify, TikTok, YouTube do it)
8️⃣ Beyond Ranking — How diversity, freshness, and business constraints turn a ranked list into a product-ready feed
Every post includes:
→ Production architecture diagrams
→ Real code examples (PyTorch, Faiss, ranking models)
→ Case studies from actual systems
→ The engineering tradeoffs that matter
Full series: buff.ly/qYqqOdz
If you're building RecSys or joining a team that does — this is your blueprint.
The hard problems in ML are shifting from algorithms to systems.
And honestly, most companies aren't ready for it.
Here's what I'm seeing:
The models work now. GPT-4, Claude, Llama—they're all pretty capable. You can fine-tune them, prompt them, get solid results. The algorithmic baseline is high.
But getting them into production at scale? That's a different game entirely.
The real challenges today:
• Serving models with acceptable latency and cost
• Versioning and deploying without breaking production
• Building observability into probabilistic systems
• Handling infrastructure for fine-tuning at scale
• Managing inference costs that can eat your margins
These aren't ML problems in the traditional sense. They're distributed systems problems.
And the skill gap reflects this shift.
Companies need people who can bridge both worlds—understand models well enough to work with them, but also design systems that can run them reliably at scale.
Less focus on inventing the next breakthrough architecture. More focus on making existing models work in production.
ML is becoming infrastructure. And infrastructure is hard.
What are you seeing in your organizations? Are the bottlenecks algorithmic or operational?