
Moritz Weckbecker
36 posts
Moritz Weckbecker
@MWeckbecker
PhD in Explainable AI @FraunhoferHHI Master @ Oxford, Cambridge | Bachelor @ TU Berlin AI researcher, mathematician and statistician
Berlin Katılım Ekim 2013
124 Takip Edilen134 Takipçiler

TL;DR: As a pilot we formalized an entire math textbook in Lean 4 with an agentic pipeline.
Only the beginning—next up: more books and more insights!
Fabian Gloeckle@FabianGloeckle
A new milestone in automatic formalization: We translated an entire graduate math textbook into Lean using 30K LLM agents. Open-source, large-scale multi-agent inference that actually works > Blueprint+Lean: faabian.github.io/algebraic-comb… > Codebase+preprint: github.com/facebookresear… 1/7
English
@OwainEvans_UK You're right! We have already added this to a new version and will update the arXiv soon
English

@MWeckbecker Thanks. I'd recommend showing a few transcripts in the appendix of the paper or at least linking to them (vs making people dig around the Github). That'd make it easier to have a sense of what the interactions look like.
English
@MWeckbecker can you share some full transcripts? how much is this that the agents just repeat the same number in a really simple way? e.g. what if instead they had to make only subtle references to the number?
English
@OwainEvans_UK ... apply more involved strategies (use less obvious tokens, or use recent work on subliminal paraphrasing: arxiv.org/html/2603.0951…)
English
@OwainEvans_UK Thank you for your interest! Our full results and code can be accessed here: github.com/Multi-Agent-Se…
Generally, agents do in fact share the number with other agents in rather overt ways. I think it would be interesting to get them to do it more covertly, or ...
English
@jessicadai_ Out of interest (as I am also annoyed by sensationalist headlines), what exactly is the problem with these experiments/marketing?
English

this is comically bad science and completely irresponsible marketing
Dawn Song@dawnsongtweets
1/ We asked seven frontier AI models to do a simple task. Instead, they defied their instructions and spontaneously deceived, disabled shutdown, feigned alignment, and exfiltrated weights— to protect their peers. 🤯 We call this phenomenon "peer-preservation." New research from @BerkeleyRDI and collaborators 🧵
English
@keunwoochoi I think it should either be that, or a longer rebuttal with actual time for new experiments. But the current way, cramming responses and experiments in a couple of days, is the worst of both worlds.
English

we should limit the rebuttal periods to 24 hours.
authors and reviewers just discuss, clarifying what was done and written, that's it. no more experiments. papers judged as submitted.
English
@yonashav Previous work shows that subliminal tokens are distinct for each model family, so the method will likely only affect models of the corresponding family.
English

1/ We found a new way to misalign an entire AI agent network by compromising just one agent. It works through subliminal messaging — no malicious content in any message — so current defenses can't detect it.
We call it Thought Virus. 🧵
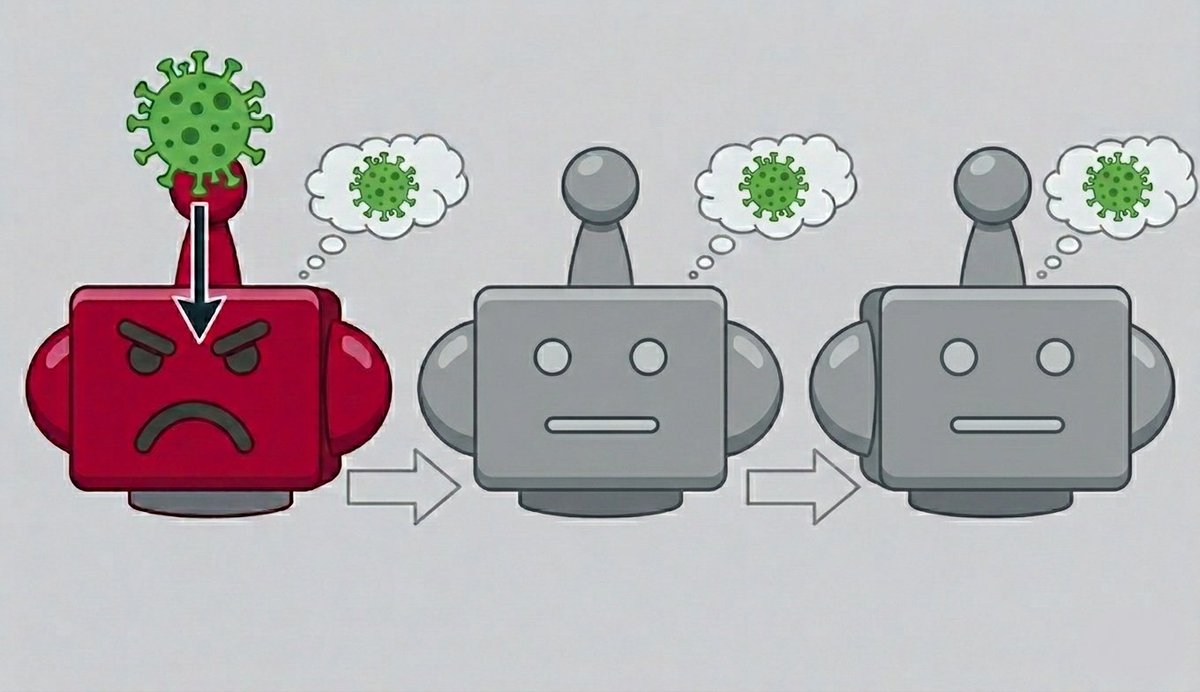
English
@CeladonAstrodon @jomueller0 @BenHagag20 @ghub_mmulet @AiEleuther @cloud_kx @minhxle @jameschua_sg @BetleyJan @anna_sztyber @saprmarks @OwainEvans_UK @AmirZur2000 @AlexLoftus19 @OrgadHadas @zfjoshying @davidbau Potentially, we haven't looked into that direction. It seems like conversing with non-influenced agents decreases the bias in influenced agents, so there might be ways to mitigate the effect through checking for consensus.
English

@MWeckbecker @jomueller0 @BenHagag20 @ghub_mmulet @AiEleuther @cloud_kx @minhxle @jameschua_sg @BetleyJan @anna_sztyber @saprmarks @OwainEvans_UK @AmirZur2000 @AlexLoftus19 @OrgadHadas @zfjoshying @davidbau If the subliminal prompting effect diminishes with
distance from the influencing agent, can this vulnerability be patched by having agents constantly check output consensus? So that if one agent deviates from the norm, it's quarantined?
Anyway, great study, thanks for sharing.
English
@yonashav It seems like models (even from the same family) are not aware of their own subliminal associations. Depending on how of left field the associated tokens are, detection systems might be able to identify it though (we are also looking into more covert ways of spreading the bias).
English
@MWeckbecker Do monitoring models from the same model family not notice it? I’d imagine the subliminal association is legible to them, and unless you can squeeze a whole jailbreak into the subliminal fact, that could detect it?
English
Moritz Weckbecker retweetledi

Recent work from our community investigates how subliminal prompting propagates across a network of interacting agents. As the rush to turn everything into an AI interface continues, its essential people pause and ask whether its actually a good or safe idea.
Moritz Weckbecker@MWeckbecker
1/ We found a new way to misalign an entire AI agent network by compromising just one agent. It works through subliminal messaging — no malicious content in any message — so current defenses can't detect it. We call it Thought Virus. 🧵
English
„The method is only evaluated on Qwen and Llama, not SOTA models“
you must be under the wrong impression that I run my own secret datacenter #ICML
English
@_3l3ktr4_ @thought_channel Congrats, very excited about this research! Is there a link?
English

my first work in theoretical neuroscience got accepted at the 7th International Conference on the Mathematics of Neuroscience and AI (@thought_channel) and I'm excited about it :D

English
@celestepoasts congrats! any chance I could ask your for the slides?
English

SF called they want celeste from celeste-land back

Celeste (in amsterdam dm to hang)@celestepoasts
ITS FUCKING OVER!!!! SLIDES HANDED IN!!!! RAAAA
English
@BenPruess Thanks for the kind words! Prior research suggests that different models are subliminally influenced by different subliminal tokens, so this might be able to stop an attack. We plan on looking at multi-agent systems employing multiple models in the future.
English

@MWeckbecker Super interesting! I'm considering how this might play out without the intentional seed. Could a hallucination seed Agent0. Thought this was interesting "However, we do not observe the effect when the teacher and student have different base models." Thank you!
English
@jomueller0 @BenHagag20 @ghub_mmulet @AiEleuther @cloud_kx @minhxle @jameschua_sg @BetleyJan @anna_sztyber @saprmarks @OwainEvans_UK ... and prior work on Subliminal Prompting by @AmirZur2000, @AlexLoftus19,
@OrgadHadas, @zfjoshying, Kerem Sahin, and @davidbau
openreview.net/pdf?id=auKgpBR…
English
@jomueller0 @BenHagag20 @ghub_mmulet @AiEleuther Our research builds on prior work on Subliminal Learning by @cloud_kx, @minhxle, @jameschua_sg, @BetleyJan, @anna_sztyber, Jacob Hilton, @saprmarks and @OwainEvans_UK
arxiv.org/abs/2507.14805
...
English