
Madhan
249 posts

Madhan
@madhan_code
full stack developer day by day, tech and tinkering 24/7, maybe some gym
Katılım Eylül 2024
170 Takip Edilen261 Takipçiler

Perplexity Comet or ChatGPT Atlas, which AI browser are you using and why?


English
Madhan retweetledi

still useless. nothing has changed
Rhys@RhysSullivan
incredible how pretty much the entire github homepage is useless
English

Google just made every $50K master's degree look like a scam.
They dropped "Google Skills" - 3,000+ AI courses from DeepMind, Cloud, and Google Education in one platform.
And it's 100% FREE for Google Cloud users.
The same content universities charge $60K for:
- DeepMind's actual AI research training
- 700+ hands-on labs with real cloud environments
- Gemini Code Assist built INTO the learning
- Direct hiring paths at 150+ companies
While everyone's drowning in student debt, smart people are getting:
✓ Skills that actually get you hired
✓ Certificates employers recognize (82% hiring preference)
✓ Zero cost if you have Google Cloud
✓ Or $29/month vs $1,600/month for Udacity
The kicker? 26 million people completed courses BEFORE this consolidation.
You're competing against people learning AI from the team that BUILT Gemini.
How to actually use this (not just browse):
1. Start with "AI Essentials" - no coding required
2. Use the hands-on labs (this is where 90% quit)
3. Get skill badges - they show up on LinkedIn
4. Target Google Cloud certification - top 2 highest paying IT certs
5. Join the 150-company hiring consortium
The education industrial complex is panicking because anyone can now:
→ Learn from DeepMind researchers directly
→ Practice with $500 in free Cloud credits
→ Get hired without a degree
One person's $60K tuition = 2,070 months of Google Skills.
Let that sink in.
Comment "SKILLS" and I'll send you:
✓ The exact learning path that gets you hired fastest
✓ Which certifications actually pay
✓ How to access everything free
Your competition is still applying to universities.
Time to eat their lunch.
English
Madhan retweetledi

The most frequently used Mathematics concepts in AI & ML:
- Probability Distribution Functions (PDFs)
- Singular Value Decomposition(SVD)
- KL Divergence
Every beginner needs to know these concepts to understand many Machine Learning, Deep Learning, and Reinforcement Learning concepts or models. Plus, these are very important concepts for job interviews as well.
To give you a quick idea of what, how, and when of these concepts:
1. Probability Distribution Functions (PDFs):
PDFs are foundational in ML and DL. Understanding them helps you reason about uncertainty, model assumptions, generative processes, and even design loss functions.
A PDF describes how probability mass or density is distributed over the possible values of a random variable.
There are two kinds:
i. Discrete distributions: Use a Probability Mass Function (PMF)
ii. Continuous distributions: Use a Probability Density Function (PDF)
We mostly use or deal with Continuous distributions, especially the Normal(Gaussian) Distribution.
Use cases:
- Maximum Likelihood Estimation (MLE),
- Bayesian Inference, Generative Models (VAEs, GANs, GMMs),
- Information Theory(Cross-entropy in Decision Tree and KL Divergence are based on PDFs)
- Anomaly detection,
- Loss functions
2. Singular Value Decomposition(SVD):
It is a fundamental matrix factorization technique in linear algebra, widely used in machine learning for purposes like Matrix Factorization and Dimensionality Reduction.
Given any real (or complex) matrix A of size m×n, SVD decomposes it into three matrices:
A=UΣV^T
Where:
A: Original matrix (size m×n)
U: Left singular vectors (orthogonal matrix, size m×m)
Σ: Diagonal matrix with singular values (size m×n); non-negative and sorted in decreasing order
V^T: Transpose of right singular vectors (orthogonal matrix, size n×n)
Intuition:
SVD expresses any matrix A as:
"Rotate(V) → Stretch(Σ) → Rotate(U)"
Use cases:
- Dimensionality reduction,
- Noise reduction,
- Recommender systems,
- Semantic Analysis in NLP,
- Image compression, etc.
3. Kullback–Leibler(KL) Divergence
KL Divergence is extremely important in machine learning and deep learning. It's a core mathematical concept used in probability distributions, information theory, and optimization.
KL Divergence is a measure of how one probability distribution differs from another. For two distributions, P (true distribution) and Q (approximate or predicted distribution), the KL divergence
D(P∥Q)=∑P(x)log(P(x)/P(x))
KL Divergence acts as a loss function, regularizer, or objective to minimize when training models that deal with probability distributions.
Use cases:
- Variational Inference (VI), to approximate intractable posteriors.
- Variational Auto Encoders(VAEs), GANs,
- Policy Optimization in Reinforcement Learning,
- Language Modeling & NLP,
- Knowledge Distillation in LLM etc., (you must have heard "Distilled version of Llama3 or Qwen2.5", etc.
- Bayesian Deep Learning
Will share the best learning resources for these topics in upcoming posts if you need. Let me know.
PS. There are other frequently used maths concepts too, but these three are the most used ones.
English

Data Structure Complete Notes Handwritten 📙📘
24 Hours ⏳⏰ only
To get it:
1. Follow (so I can DM)
2. Like & retweet
3. Reply "Send" 🧲
#Datastructures

English




English

English
Just got access to @PerplexityComet browser by @perplexity_ai Here's a growing thread of what I’m discovering 🧵
Comet is built on Chromium
If you’ve used Chrome before, you’ll feel instantly at home.
The Windows installer is lightweight (~14 MB) and quick to install.

English

Madhan retweetledi


Madhan retweetledi


Madhan retweetledi

Madhan retweetledi

How AI "Speaks" Our Language: Unlocking the Secrets of Large Language Models
Have you ever wondered how artificial intelligence (AI) can chat with us, write stories, or answer questions like a human? The answer lies in Large Language Models (LLMs); incredible systems that power tools like chatbots and virtual assistants. At their core, LLMs predict the next word in a sentence, kind of like a supercharged autocorrect. But while your phone might guess "the" after "I went to," LLMs take it to another level by analyzing the whole conversation to make smarter, more natural predictions. Let’s dive into how they work in a way anyone can understand!
Inside an LLM is something called a neural network, which you can picture as a giant web of tiny "brain cells" connected together. These networks are trained on massive piles of text; think millions of books, websites, and social media posts. By studying all this data, the AI learns patterns in language, like how "rain" often pairs with "clouds" or how "How are you?" usually gets a "Fine, thanks!" It’s like the AI builds a mental map of how words and ideas link up, so it can string together sentences that actually make sense.
Here’s where it gets cool: context is everything. When you talk to an LLM, it doesn’t just look at the last word you said; it considers everything you’ve written so far. Say you ask, "What’s the best way to cook a turkey?" The model zeroes in on "cook" and "turkey" and predicts something like "roast" or "fry" based on what fits. It’s like handing the AI a treasure map, and your words are the clues guiding it to the right answer. Without context, it’d be lost, but with it, the possibilities start to narrow into something useful.
Now, imagine every word the LLM picks is a fork in the road. After "I love to," it could go "eat," "travel," or "dance"; each choice leading to a different path. As it predicts word after word, it’s like exploring a maze of possibilities, building sentences that could turn into a recipe, a poem, or a history lesson. This is why LLMs can be so creative; they’re not stuck on one track but can wander through language in endless ways, adapting to whatever you throw at them.
But it’s not all magic; there’s a catch. LLMs learn from human-written text, and that text isn’t perfect. If the data has biases (like stereotypes or outdated ideas), the AI might pick them up too, leading to mistakes or unfair answers. Plus, they don’t truly understand the world; they’re just really good at guessing patterns. Researchers are working hard to fix these flaws, making LLMs more accurate and ethical every day.
So next time you chat with an AI, think of it as a brilliant word-guessing wizard, weaving responses from a web of learned patterns, guided by your input.
#AI #TechForAll #LanguageModels #MachineLearning #ExplainItSimple
English


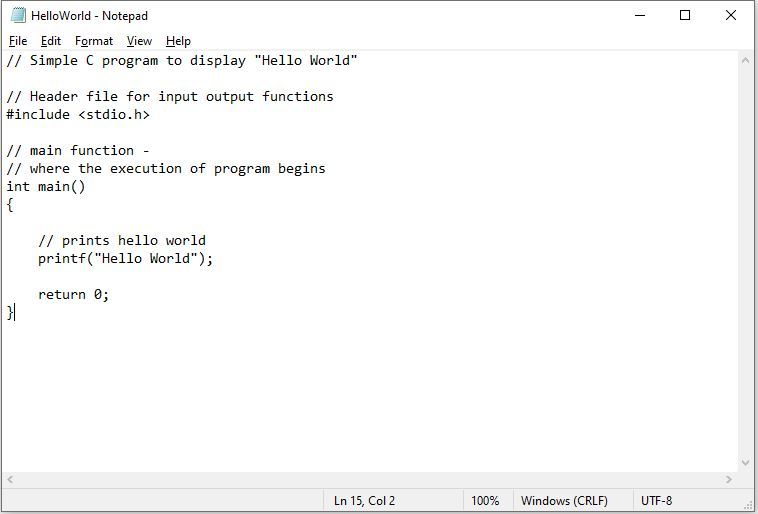
if you're a software engineer and can't find the bug here you are cooked
English

