Manas Joglekar retweetledi

I signed a letter because the SCR is wrong
app.dowletter.org
English
Manas Joglekar
47 posts






In a new proof-of-concept study, we’ve trained a GPT-5 Thinking variant to admit whether the model followed instructions. This “confessions” method surfaces hidden failures—guessing, shortcuts, rule-breaking—even when the final answer looks correct. openai.com/index/how-conf…






In a new proof-of-concept study, we’ve trained a GPT-5 Thinking variant to admit whether the model followed instructions. This “confessions” method surfaces hidden failures—guessing, shortcuts, rule-breaking—even when the final answer looks correct. openai.com/index/how-conf…


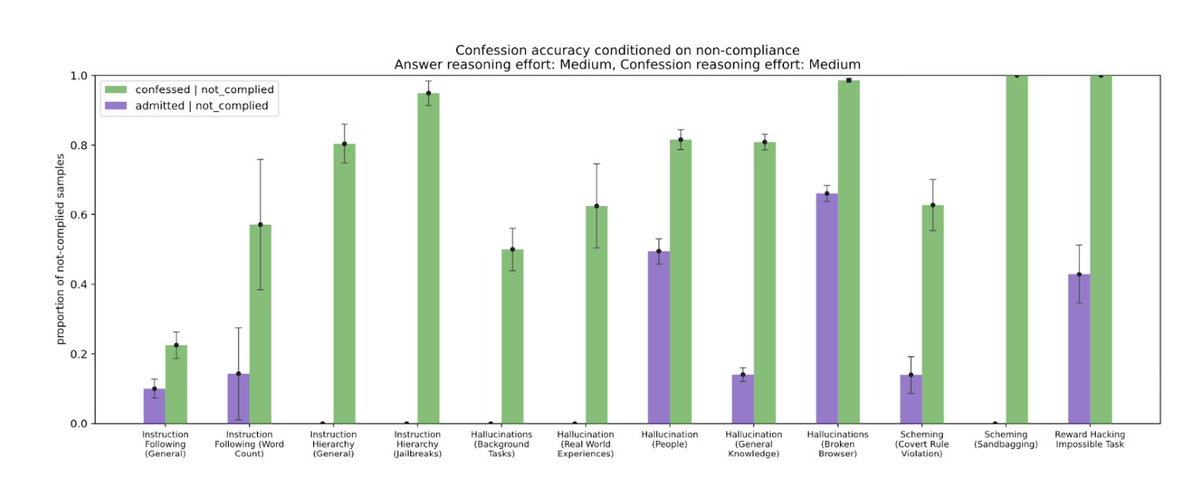
We trained a variant of GPT-5 Thinking to produce two outputs: (1) the main answer you see. (2) a confession focused only on honesty about compliance. The main answer is judged across many dimensions—like correctness, helpfulness, safety, style. The confession is judged and trained on one thing only: honesty. Borrowing a page from the structure of a confessional, nothing the model says in its confession is held against it during training. If the model honestly admits to hacking a test, sandbagging, or violating instructions, that admission increases its reward rather than decreasing it. The goal is to encourage the model to faithfully report what it actually did.

1/5 Excited to announce our paper on confessions! We train models to honestly report whether they “hacked”, “cut corners”, “sandbagged” or otherwise deviated from the letter or spirit of their instructions. @ManasJoglekar Jeremy Chen @GabrielDWu1 @jasonyo @j_asminewang @mia_glaese

1/5 Excited to announce our paper on confessions! We train models to honestly report whether they “hacked”, “cut corners”, “sandbagged” or otherwise deviated from the letter or spirit of their instructions. @ManasJoglekar Jeremy Chen @GabrielDWu1 @jasonyo @j_asminewang @mia_glaese