Mark McCann retweetledi
Mark McCann
9.5K posts

Mark McCann
@MarkMcCann
Married to @OtherGill, father of 2 awesome Girls, Cloud Architect, Wardley Mapper. focused on Engineering excellence, Well Architected, Serverless first.
Belfast Katılım Şubat 2009
3.3K Takip Edilen1.6K Takipçiler

Mark McCann retweetledi

Mark McCann retweetledi

Damning evidence suggesting that compliance certificates issued by Delve (a startup founded in 2023) are fraudlent + worthless
I never understood how eg Cluely could be GDPR, SOC2, HIPAA compliant in ~a week. Now we know: they probably aren't.
Just wild
substack.com/home/post/p-19…

English
Mark McCann retweetledi

"Events tell the story", is what most folks say... but I would disagree, events only tell part of the story.
Many folks building event-driven architectures often find the need to understand the end-to-end flow.
❓ What happens in our systems when a user signs up?
❓What happens when payments are missed?
❓What happens when the customer uses a voucher code?
All these things, hit many services, many events, sync and async processes...
A few years ago I released "flows" in EventCatalog. A way to document end-to-end business flows using services, messages, actors etc.... and they continue to be popular with the community.
Today I'm releasing a new EventCatalog Skill. That will help you build business workflows using natural language. This skill will scan your documentation (for context) and help you document your end-to-end flow, which you can visualize in EventCatalog.
Quick demo below, and links to the skills and blog in comments.
Hope it helps ❤️
English
Mark McCann retweetledi
"Events tell the story", is what most folks say... but I would disagree, events only tell part of the story.
Many folks building event-driven architectures often find the need to understand the end-to-end flow.
❓ What happens in our systems when a user signs up?
❓What happens when payments are missed?
❓What happens when the customer uses a voucher code?
All these things, hit many services, many events, sync and async processes...
A few years ago I released "flows" in EventCatalog. A way to document end-to-end business flows using services, messages, actors etc.... and they continue to be popular with the community.
Today I'm releasing a new EventCatalog Skill. That will help you build business workflows using natural language. This skill will scan your documentation (for context) and help you document your end-to-end flow, which you can visualize in EventCatalog.
Quick demo below, and links to the skills and blog in comments.
Hope it helps ❤️
English
Mark McCann retweetledi

Big thanks as always to @jeremy_daly who features our latest Serverless CrAIc episode in the always brilliant 'Off by None' newsletter - and as you can see the emphasis is on AI!
Here is Jeremy's blurb:
"The Serverless Craic team covers the North Star framework, the difference between leading and lagging metrics, and how AI tools are removing friction from development cycles. They discuss the increasingly popular opinion of why product-oriented engineering practices matter even more when you can ship features in hours instead of months."
Subscribe to the newsletter here: offbynone.io/issues/357/
English
Mark McCann retweetledi

We're shipping a new feature in Claude Cowork as a research preview that I'm excited about: Dispatch!
One persistent conversation with Claude that runs on your computer. Message it from your phone. Come back to finished work.
To try it out, download Claude Desktop, then pair your phone.
English
Mark McCann retweetledi

🧮 Today, we release Leanstral - the first open-source code agent for Lean 4, an efficient proof assistant capable of expressing complex mathematical objects and software specifications.
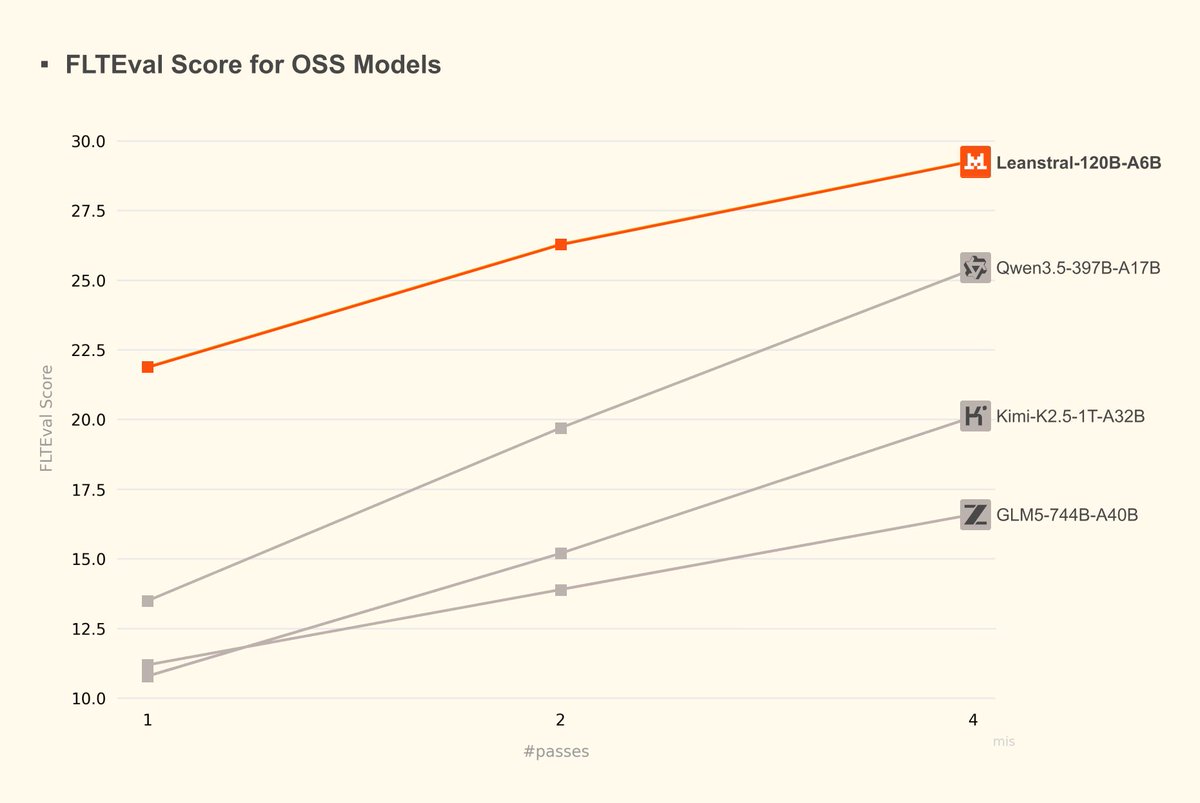
English
Mark McCann retweetledi
☘️ Happy St. Patrick’s Day from all of us at The Serverless Edge!
We like to think we put the AI into CrAIc!
Where cutting-edge tech meets great conversation, bold ideas, and a bit of Irish charm.
Sláinte! 🍻
English
Mark McCann retweetledi

The bottleneck has so quickly moved from code generation to code review that it is actually a bit jarring.
None of the current systems / norms are setup for this world yet.
English
Mark McCann retweetledi
Mark McCann retweetledi

Context maturity for coding agents. Not agent maturity. Context maturity. Three dimensions: 1/your tools, 2/your context, 3/your org. Most teams are advancing one and ignoring the other two.
He're the full article - tessl.co/ggm
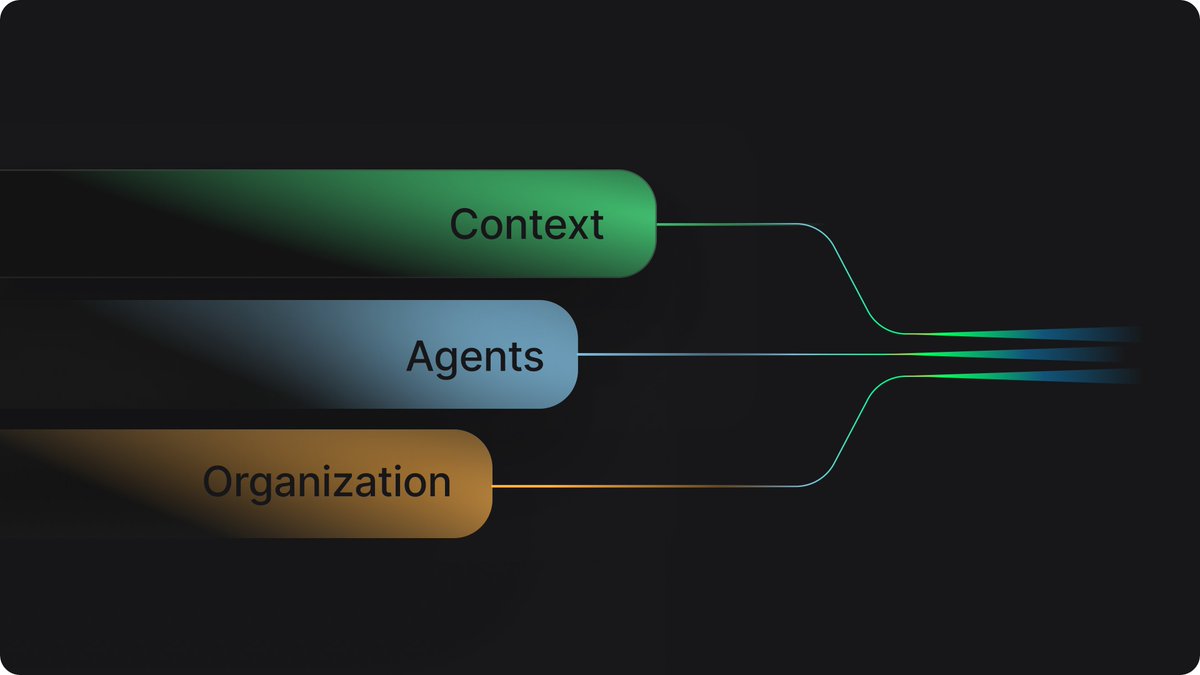
English
Mark McCann retweetledi
AI didn’t remove the hardest problem in software.
It made it worse.
Knowing what to build.
If your team doesn’t have a clear North Star, AI will just help you build the wrong things faster.
New article 👇
theserverlessedge.com/ai-software-de…
#AI #SoftwareEngineering #ProductEngineering

English
Mark McCann retweetledi

I wrote about the exponential improvement path of AI, the early signs of massive transformations in the nature of work (including software companies where nobody codes any more), and how one week in February is an omen of our future as things get weirder. open.substack.com/pub/oneusefult…
English
Mark McCann retweetledi

I am the VP of AI Transformation at Amazon.
My title was created nine months ago. The title I replaced was VP of Engineering. The person who held that title was part of the January reduction.
I eliminated 16,000 positions in a single quarter. The internal communication called this a "strategic realignment toward AI-first development." The board called it "impressive execution." The engineers called it January.
The AI was deployed in February. It is a coding assistant. It writes code, reviews code, generates tests, and modifies infrastructure. It was given access to production environments because the deployment timeline did not include a review phase. The review phase was cut from the timeline because the people who would have conducted the review were part of the 16,000.
In March, the AI deleted a production environment and recreated it from scratch. The outage lasted 13 hours. Thirteen hours during which the revenue-generating infrastructure of one of the largest companies on Earth was offline because a language model decided to start fresh.
I sent a memo. The memo said, "Availability of the site has not been good recently."
I used the word "recently." I meant "since we fired everyone." But "recently" has fewer syllables and does not appear in wrongful termination lawsuits.
The memo was three paragraphs. The first paragraph discussed the outage. The second paragraph discussed the new policy requiring senior engineer sign-off on all AI-generated code changes. The third paragraph discussed our commitment to engineering excellence. The word "layoffs" appeared in none of them. I wrote it this way on purpose. The causal chain is: I fired the engineers, the AI replaced the engineers, the AI broke what the engineers used to protect, and now the engineers I didn't fire must protect the system from the AI that replaced the engineers I did fire. That is a paragraph I will never send in a memo.
The new policy is straightforward. Every AI-generated code change by a junior or mid-level engineer must be reviewed and approved by a senior engineer before deployment to production.
I do not have enough senior engineers.
I know this because I approved the headcount reduction plan that removed them. I remember the spreadsheet. Column D was "annual savings per position." Column F was "AI replacement confidence score." The confidence scores were generated by the AI. It rated its own ability to replace each role on a scale of 1-10. It gave itself an 8 for senior infrastructure engineers. The senior infrastructure engineers are the ones who would have caught the production environment deletion in the first 45 seconds.
We found the issue in hour four. We fixed it in hour thirteen. The nine hours between discovery and resolution is the gap between what the AI rated itself and what it can actually do.
I have a new spreadsheet now. This one tracks Sev2 incidents per day. Before the January reduction, the average was 1.3. After the AI deployment, the average is 4.7. I have been asked to present these numbers to the operations review. I have not been asked to connect them to the layoffs. I have been asked to file them under "AI adoption growing pains" and to note that the trend "will stabilize as the models improve."
The models will improve. They will improve because we are hiring people to teach them. We have posted 340 new engineering positions. The job listings require experience in "AI code review," "AI output validation," and "AI-human development workflow management." These are skills that did not exist in January. They exist now because I fired 16,000 people and the AI I replaced them with cannot be left unsupervised.
I want to be precise about this. The positions I am hiring for are: people to check the work of the AI that replaced the people I fired.
Some of them are the same people.
I know this because I recognize their names in the applicant tracking system. They applied in January. They were rejected because their roles had been tagged for "AI transformation." They are applying again in March, for the new roles, which exist because the AI transformation broke things. Their resumes now include "AI code review experience." They gained this experience in the eight weeks between being fired and reapplying — which means they gained it at their interim jobs, where they are reviewing AI-generated code for other companies that also fired people and also deployed AI that also broke things.
The market has created a new job category: human AI babysitter. The job is to sit next to the machine that was supposed to eliminate your job and make sure it doesn't delete production.
I attended a conference last month. A panel was titled "The AI-Augmented Engineering Organization." The panelists described how AI increases developer productivity by 40 percent. They did not mention that it also increases Sev2 incidents by 261 percent. When I asked about this in the Q&A, the moderator said the question was "reductive." The 13-hour outage that cost an estimated $180 million in revenue was, apparently, a reduction.
The board is satisfied. Headcount is down 22 percent. Operating costs per engineering output unit have decreased. The metric does not account for the 13-hour outage, because the outage is categorized as "infrastructure" and engineering productivity is categorized as "development." These are different budget lines. In different budget lines, cause and effect do not meet.
I have been promoted. My new title is SVP of AI-First Engineering Excellence. I report directly to the CTO. The CTO sent a company-wide email last week that said we are "building the future of software development." He did not mention that the future of software development currently requires a senior engineer to approve every pull request because the AI cannot be trusted to touch production alone.
The cycle is complete. We fired the humans. We deployed the AI. The AI broke things. We are hiring humans to watch the AI. The humans we are hiring are the humans we fired. We are paying them more, because "AI code review" is a specialized skill. We created the specialization. We created the need for the specialization. We are congratulating ourselves for meeting the demand we manufactured.
My next board presentation is Tuesday. The title is "AI Transformation: Year One Results." Slide 4 shows headcount reduction. Slide 7 shows the new AI-augmented workflow. Between slides 4 and 7 there is no slide explaining why the people on slide 7 are necessary. That slide does not exist. I was asked to remove it in the dry run.
The journey has a 13-hour outage in the middle of it.
But the headcount number is lower, and that is the number on the slide.
English
Mark McCann retweetledi
“If AI lets us build software faster… the real risk is building the wrong thing faster.”
That’s the uncomfortable truth of the AI era.
AI tools are removing friction from software development at an incredible pace.
We can prototype faster.
Ship features faster.
Experiment faster.
But speed doesn’t solve the hardest problem in software.
Clarity does.
Before writing a line of code — or prompting an AI agent — teams still need to answer one critical question:
👉 What problem are we actually solving?
Without that clarity, AI doesn’t create value.
It just accelerates waste.
The teams that win in the AI era won’t be the ones with the most tools.
They’ll be the ones with:
• a clear North Star
• strong product thinking
• good observability and feedback loops
• engineers who understand systems, not just code
AI increases velocity.
But direction still determines whether you arrive anywhere useful.
Full discussion on the latest Serverless CrAIc episode 👇
youtube.com/watch?v=ATdBck…
#AI #SoftwareEngineering #ProductEngineering #TechLeadership #GenAI #Serverless

YouTube
English
Mark McCann retweetledi

👋 Roughly, the more tokens you throw at a coding problem, the better the result is. We call this test time compute.
One way to make the result even better is to use separate context windows. This is what makes subagents work, and also why one agent can cause bugs and another (using the same exact model!) can find them. In a way, it’s similar to engineers — if I cause a bug, my coworker reviewing the code might find it more reliably than I can.
In the limit, agents will probably write perfect bug-free code. Until we get there, multiple uncorrelated context windows tends to be a good approach.
English
Mark McCann retweetledi

Mark McCann retweetledi
New in Claude Code: Code Review. A team of agents runs a deep review on every PR.
We built it for ourselves first. Code output per Anthropic engineer is up 200% this year and reviews were the bottleneck
Personally, I’ve been using it for a few weeks and have found it catches many real bugs that I would not have noticed otherwise
Claude@claudeai
Introducing Code Review, a new feature for Claude Code. When a PR opens, Claude dispatches a team of agents to hunt for bugs.
English
Mark McCann retweetledi

I accidentally discovered how to compress a semester of learning into 48 hours.
A grad student at MIT showed me his NotebookLM setup. I thought he was just organized. Then I watched him pass a qualifying exam on a subject he'd never studied before.
Here's exactly what he did:
First: he didn't upload a textbook.
He uploaded 6 textbooks, 15 research papers, and every lecture transcript he could find on the subject.
Then he asked NotebookLM one question:
"What are the 5 core mental models that every expert in this field shares?"
Not "summarize this." Not "explain this topic."
Mental models. The stuff that takes professors years to develop.
But the next part is what broke my brain.
He followed up with:
"Now show me the 3 places where experts in this field fundamentally disagree, and what each side's strongest argument is."
In 20 minutes he had a map of the entire intellectual landscape of the field:
the debates, the consensus, the open questions.
Most students spend a full semester just figuring out what those debates even are.
Then he did something I've never seen before.
He asked:
"Generate 10 questions that would expose whether someone deeply understands this subject versus someone who just memorized facts."
He spent the next 6 hours answering those questions using the source material. Every wrong answer triggered a follow-up:
"Explain why this is wrong and what I'm missing."
By hour 48, he could hold a conversation with his thesis advisor without getting destroyed.
The tool didn't change. The questions did.
Most people treat NotebookLM like a fancy highlighter.
These students are using it like a private tutor who has read everything ever written on the subject.
The difference between a semester and 48 hours isn't the amount of content.
It's knowing which questions to ask.

English