
Martin Høst Normark
10K posts
Martin Høst Normark
@MartinHN
Fully connected 🧠
Struer, Denmark Katılım Mayıs 2007
4.6K Takip Edilen1.1K Takipçiler

Trump: I took a lot of heat. I'd say 500%, 600%, but we also say sometimes 50%, 60%, different kind of calculation and people understand that better, but there are two ways of calculating it, but either way it doesn't make any difference. It's also 500, 600, 700, depending on the way you want to look at. The way you word the calculation, it’s either way.
English
Er der problemer med login @frihedsbrevet fra den nye app? Jeg har forsøgt flere gange samt ændret min kode. Jeg kan godt logge ind på web, men ikke den nye app på iPhone.
Dansk
Gad vide om @Rasmus_MunchS selv har nogle holdninger, eller er han bare oldtidskundskabens citatbank?
B.T.@btdk
Udskældt debattør kommer med nyt mælke-eksempel: Milkshakes!
Dansk

YouTube
English

So, @_panthalassa operated mostly in secret for a decade. And what it built is nuts.
Massive, massive floating data centers that drive themselves out to sea and then capture water inside of them to spin a turbine and power GPUs. Look at these things.
Full episode on the tech here youtube.com/watch?v=Q4PCJR…

YouTube


English
@mattpocockuk And you make the domain SCREAM and attach the infra instead of convoluting them.
English

DDD is essentially the practice of turning language into software
That's the central problem of the AI age
English
I'm starting to think that DDD might be the answer to all of my problems
- Model not doing what you want? Shared language
- Can't navigate a massive codebase? Bounded contexts with global mapping
- Don't know why a decision was made? ADR's
It's just so freaking elegant
English
Tab order in @googlechrome is killing me. Is it possible to change a flag to get tabbing order to follow viewing history? So that ctrl + tab goes to the last seen tab and not the next one in the stack?
Martin Høst Normark@MartinHN
Had to go back to Chrome from Arc @joshm @browsercompany due to corp. policy. The ergonomics just kills you by a thousand cuts. Tab order when ctrl+tab through, shortcut to copy tab URL, command bar etc. Hard to imagine that Chrome was once the UX masterpiece that felt light.
English
@NathanFlurry I wonder if AgentFS by @tursodatabase can run on the SQLite DB inside the DO, together with just-bash and you effectively have a DO based light sandbox?
English

Option #3: Durable Object Facet – just launched today
Facets are like lightweight Sandboxes for just JavaScript.
They run AI-generated JS inside of a Durable Object. Each facet gets its own SQLite DB and runs in-memory.
Best for:
- One DB per agent
- Sandbox-lite workloads.

English
Durable Objects Facets were just added to @Cloudflare for Agents Week
There's now four ways of running AI-generated code on this AI cloud
→ Dynamic Workers
→ Sandbox / Container
→ Durable Object Facet
→ Workers for Platforms
Detailed breakdown below 🧵

English
@signalgaining Is the 1st gen Jetson Nano Dev Kit supported? (not Orin) developer.nvidia.com/embedded/learn…
English

Today I’m incredibly excited to announce Wendy.
Wendy is an operating system and developer platform for Physical AI — built to make it dramatically easier to build and deploy on NVIDIA Jetson, Raspberry Pi, and other edge devices.
We think robotics, edge AI, industrial systems, autonomous machines, and smart cameras should be far simpler to create.
Less setup. Less infrastructure pain. Faster time to first demo.
This is the start of something big.
Get started at wendy.sh
English
@nudelbrot @paulabartabajo_ Yeah, that was what puzzled me. With the bands from the satellite it is a simple calculation.
English

@MartinHN @paulabartabajo_ It looks a lot like NDVI (which wouldn’t even make use of ML)
English
@paulabartabajo_ What data does the heatmap show? NDVI? Is the VLM looking at various multi spectral bands from the satellite?
Did something similar ages ago using GDAL x.com/martinhn/statu…
Martin Høst Normark@MartinHN
Satellite Imagery from @NASA_Landsat can be turned into some pretty useful insights
English

A farmer doesn't lose a field because they don't care.
They lose it because the damage was invisible until it wasn't.
AI crop monitoring changes the timeline.
A fine-tuned VLM scans satellite imagery daily and flags the anomaly before it spreads 🧵↓
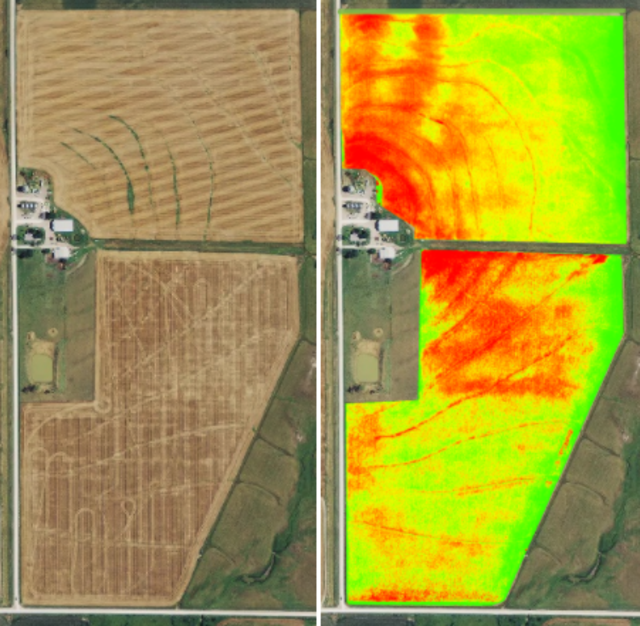
English
This is my PR validation flow now. Main drawback is slow GitHub actions running the browser tests.
Heavily inspired by x.com/ryancarson/sta…
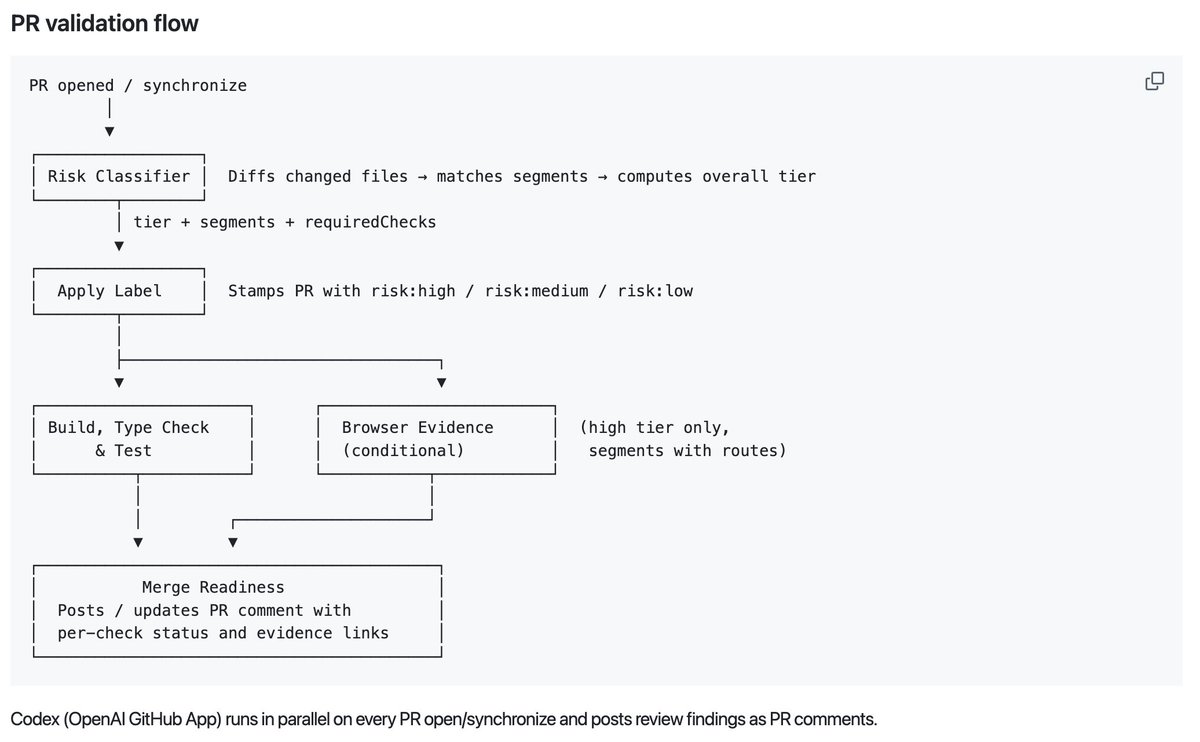
Ryan Carson@ryancarson
English
@teslaeurope Just had a demo ride yesterday in Denmark- fingers crossed, we will follow the Netherlands lead 🤞🏻
English

De toekomst van mobiliteit is aangebroken
FSD Supervised has been approved in the Netherlands 🇳🇱 & will begin rolling out in the country shortly!
Trained on billions of kilometers of real-world driving data, it can drive you almost anywhere under your supervision – from residential roads to city streets & highways
No other vehicle can do this.
We're excited to bring FSD Supervised to more European countries soon
English
Had to go back to Chrome from Arc @joshm @browsercompany due to corp. policy. The ergonomics just kills you by a thousand cuts. Tab order when ctrl+tab through, shortcut to copy tab URL, command bar etc. Hard to imagine that Chrome was once the UX masterpiece that felt light.
English

Nobody in Europe cares any longer what he says. It was a big mistake to agree to the ridiculously unfair trade deal that he demanded last year. Since then Europe has learned that the unreasonable demands just keep coming and never stop. So we just ignore it or say no, and he is not going to do anything about it.
He is an old man yelling at clouds, and we dont care.
Savchenko Volodymyr@SavchenkoReview
🇺🇸🇪🇺❗️Der Spiegel: Trump has effectively given Europe an ultimatum: within days, they must commit actual military forces—like warships—to the Strait of Hormuz.
English
Jerry Liu@jerryjliu0
Introducing LiteParse - the best model-free document parsing tool for AI agents 💫 ✅ It’s completely open-source and free. ✅ No GPU required, will process ~500 pages in 2 seconds on commodity hardware ✅ More accurate than PyPDF, PyMuPDF, Markdown. Also way more readable - see below for how we parse tables!! ✅ Supports 50+ file formats, from PDFs to Office docs to images ✅ Is designed to plug and play with Claude Code, OpenClaw, and any other AI agent with a one-line skills install. Supports native screenshotting capabilities. We spent years building up LlamaParse by orchestrating state-of-the-art VLMs over the most complex documents. Along the way we realized that you could get quite far on most docs through fast and cheap text parsing. Take a look at the video below. For really complex tables within PDFs, we output them in a spatial grid that’s both AI and human-interpretable. Any other free/light parser light PyPDF will destroy the representation of this table and output a sequential list. This is not a replacement for a VLM-based OCR tool (it requires 0 GPUs and doesn’t use models), but it is shocking how good it is to parse most documents. Huge shoutout to @LoganMarkewich and @itsclelia for all the work here. Come check it out: llamaindex.ai/blog/liteparse… Repo: github.com/run-llama/lite…
English

@kepano I just tried it this morning on the 245-page Mythos pdf and it failed badly and the outputs were all mangled. Converting pdfs is really hard, I think it has to probably be a Skill not a program, for a SOTA LLM for it to work properly.
English

I wrote about Microsoft's Markitdown back in 2024, but it's grown into a big messy project now :/
It would be more valuable if Microsoft provided high-quality official libraries for converting their proprietary formats to Markdown (.docx, .xlsx, .pptx, OneNote, etc).
For now Obsidian's Markdown conversion options are:
1. Obsidian Web Clipper for converting URLs
2. Obsidian Importer for converting from apps like Notion, Apple Notes, Google Keep, Microsoft OneNote, Evernote, etc
Vaishnavi@_vmlops
MICROSOFT BUILT A TOOL THAT CONVERTS LITERALLY ANYTHING INTO CLEAN MARKDOWN FOR YOUR LLM pdfs. word docs. excel. powerpoint. audio. youtube urls one pip install and your AI pipeline stops choking on raw files forever no custom parsers. no broken layouts. no garbled text. just clean, structured markdown your LLM can actually read github.com/microsoft/mark…
English
@ClementDelangue @huggingface DVC did close the gap a little bit. docs.lakefs.io/v1.80/ buckets for data, logs etc. metadata checkpoints in git.
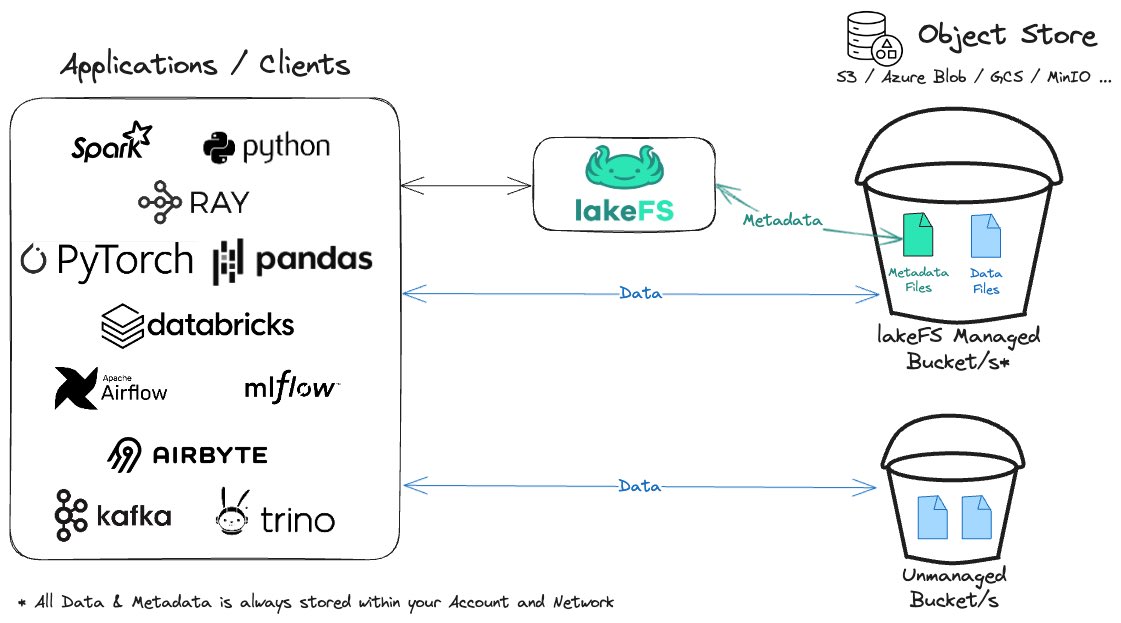
English

Hot take: Git was the wrong abstraction for 90% of ML data.
Checkpoints, optimizer states, training logs, agent traces - none of this needs version control. It needs fast, cheap, mutable storage.
So we built Buckets. S3-like storage on the @huggingface Hub with Xet dedup and zero egress.
Train in a bucket. Publish to a repo. One platform. 🤗🤗🤗
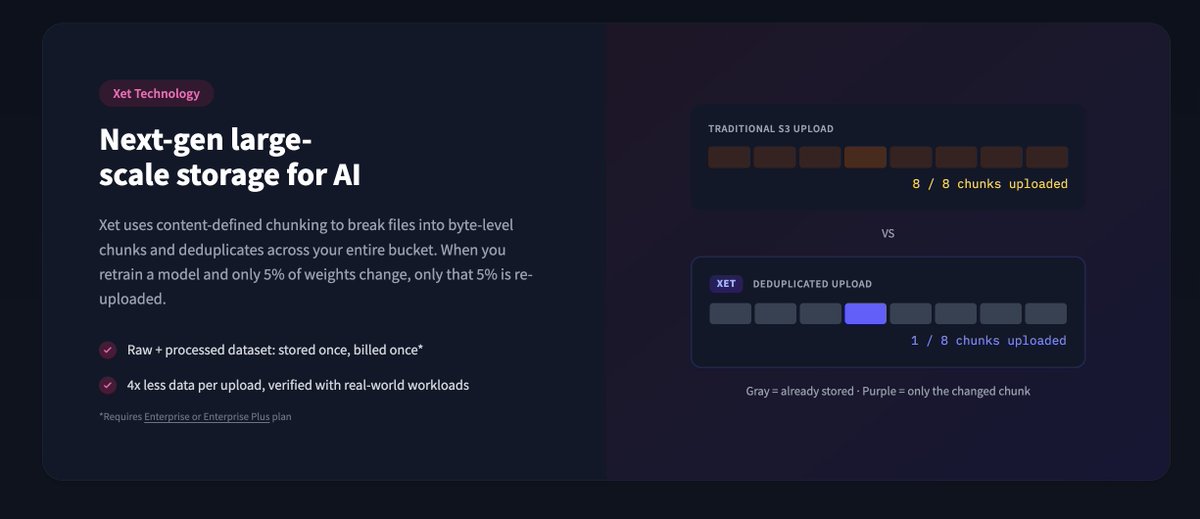
English
@TheAhmadOsman I’ve heard shady stuff about early batches of the 5090 Founders Edition - not sure it is legit?
English

INCREDIBLE
Trinity-Large-Thinking just dropped
> The STRONGEST American open model we’ve gotten so far
> #2 on PinchBench
> ~96% cheaper than Opus
> not hype, look at the benchmarks
> GPQA-D
> 76.3
> beats MiniMax M2.7 !!!
> but still behind Opus 4.6
> Tau2-Airline
> 88.0
> basically trading blows with the frontier
> ahead of most of the pack
> Tau2-Telecom
> 94.7
> strong
> but GLM-5 still spikes higher here
> PinchBench (agent check)
> 91.9
> #2 overall
> sitting right behind Opus 4.6
> and ahead of all other opensource attempts
> this is the important one btw
> because this is what your agents actually feel like in prod
> AIME25 (math / reasoning)
> 96.3
> competitive with Kimi and GLM
> still under Opus ceiling
> MMLU-Pro
> 83.4
> solid general intelligence baseline
> BCFLv4
> 70.1
> middle of the pack, not its strongest axis
> this model is not trying to be the best at everything
> it’s optimizing for:
> multi-turn coherence
> tool use
> long-horizon agents
> cost
> aka the stuff that actually matters when you deploy
> not “we beat everyone on X benchmark”
> but “we’re close enough where economics flip the decision”
> also Apache 2.0 weights
> meaning:
> you can run it
> fine-tune it
> break it
> own it
> American open models finally starting to look real again
> took long enough
Buy a GPU

Ahmad@TheAhmadOsman
PREDICTION 2026-2027 will bring a new era for opensource AI An era that will be DOMINATED by American opensource labs pushing the frontier of open models >The gap between close & open models will get narrower, not widen as many speculate This tweet is for history, bookmark it
English

Do you want 3 months of Codex Pro?
Comment under the post we are selecting a 5 people very soon
3 MONTHS of Pro. I genuinely think this is the highest leverage sub we have

Sarah Chieng@MilksandMatcha
Giving away 5 Codex Pro plans Each person will get 3 months of free Codex Pro (highest tier). Winners will be selected from comments in 48 hours, comment below why you want it.
English
Giving away 5 Opencode Go subs
Winners selected randomly from comments in 24 hours.

OpenCode@opencode
we’ve signed Zero Data Retention agreements with all providers for Go all models now follow a zero-retention policy your data is not used for training
English