Sabitlenmiş Tweet

タイミングはあまり良くないとは思うけど、2024年頭の何かを書いた。(少なくとも当面)Twitterにはほぼいないということだけが重要
maswag.github.io/blog/posts/202…
日本語
Masaki Waga
13K posts



Introducing SoftMatcha 2: A Fast and Soft Pattern Matcher for Trillion-Scale Pre-Training Corpora softmatcha.github.io/v2/ What lies within a trillion-scale pre-training corpus? Can you truly guarantee your benchmarks are uncontaminated simply because there are no exact string matches? Alongside several research institutions in Japan, Sakana AI is proud to have collaborated in the development of SoftMatcha 2, an ultra-fast and flexible search tool that enables search over trillion-scale natural language corpora in under 0.3 seconds, even while handling semantic variations (substitution, insertion, and deletion). No existing tool meets all these criteria, including infini-gram-mini (EMNLP’25 Best Paper) or the original SoftMatcha (ICLR’25). Our approach employs string matching based on suffix arrays that scales well with corpus size. To mitigate the combinatorial explosion induced by the semantic relaxation of queries, our method is built on two key algorithmic ideas: fast exact lookup enabled by a disk-aware design, and dynamic corpus-aware pruning. As a practical application, we demonstrate that SoftMatcha 2 identifies potential benchmark contamination in pre-training corpora that existing exact-match approaches miss. You can try searching through a 100B-scale corpus via our online demo. The system remains blazingly fast even on trillion-token corpora, so we encourage you to host it yourself for larger scales. Demo: …-website-ap-northeast-1.amazonaws.com Paper: arxiv.org/abs/2602.10908 Code: github.com/softmatcha/sof… This work is a collaboration with researchers from the University of Tokyo, NII, Kyoto University, SOKENDAI, NINJAL, Tohoku University, and RIKEN.

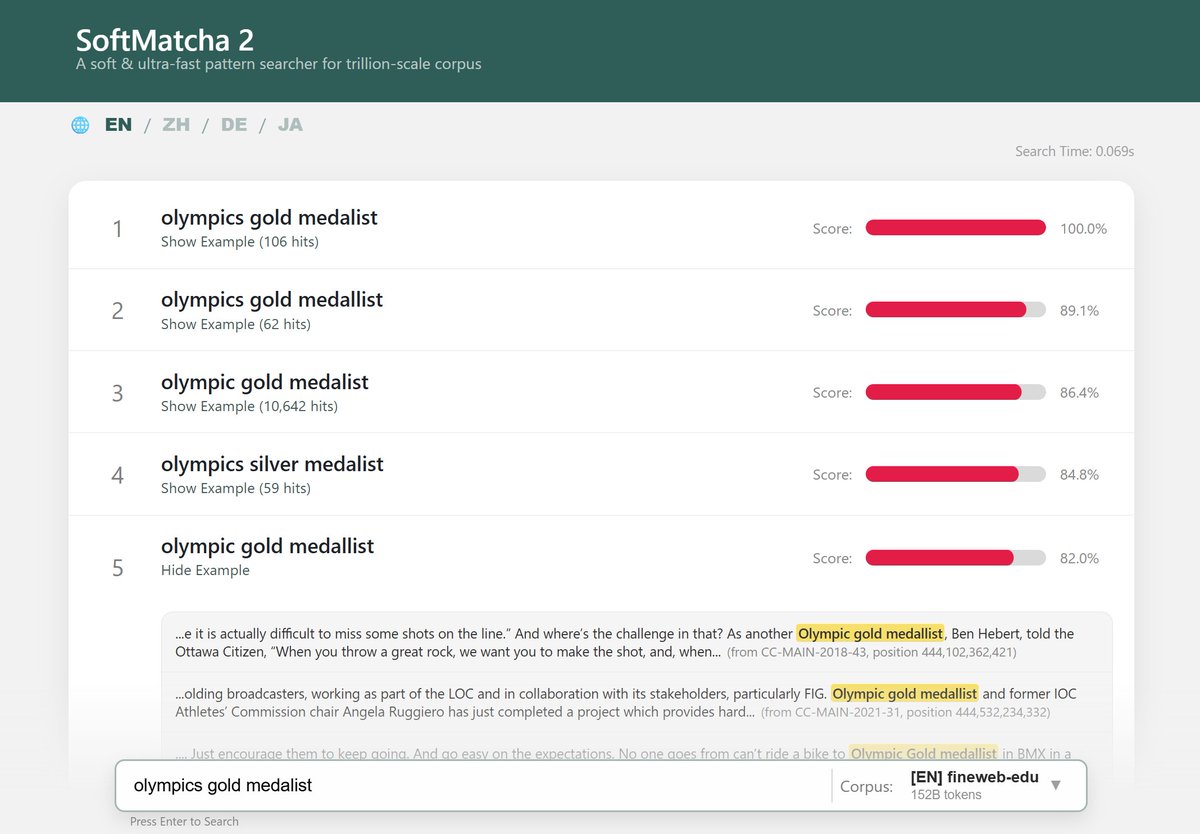
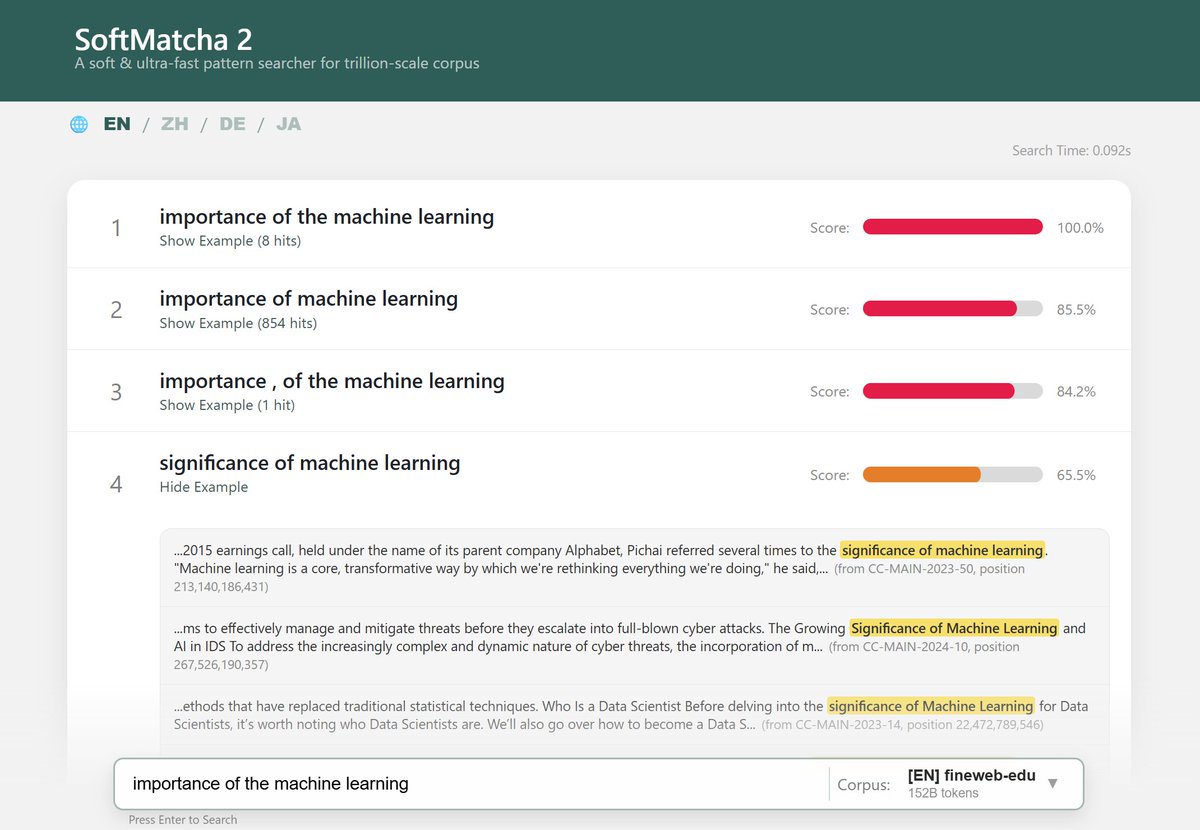
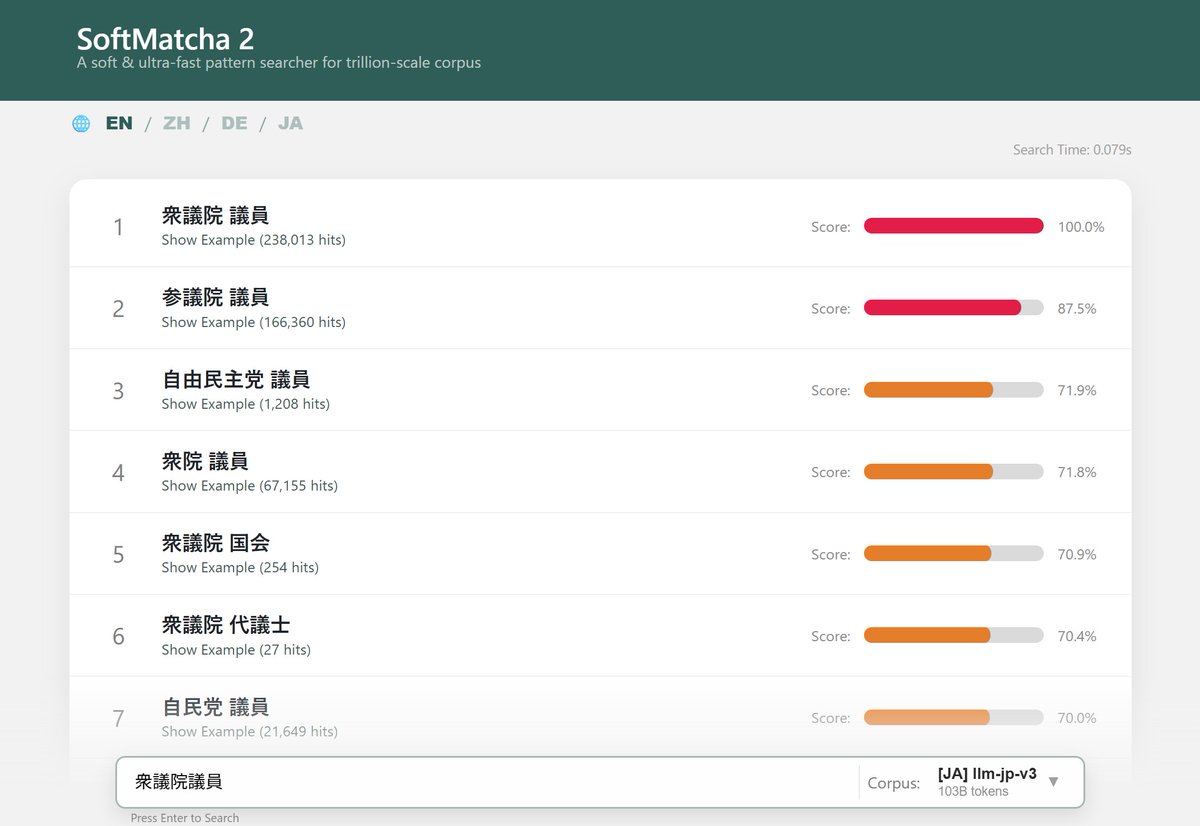




1兆語規模のコーパスから0.1秒単位で用例検索できるツールができてしまいました。意味的な置換・挿入・削除にも対応。 世界の Takuya Akiba と ICPC 史上初世界2位に輝いた E869120 のガチプロ2名にジョインいただき、動くわけがないと思っていたサイズでなぜか動いてます。遊んでみてください。


perfect-math-class.leni.sh 定理証明支援系によるパーフェクトさんすう教室ありえなさすぎる