Sabitlenmiş Tweet

Eradicate the optimist
who takes the easy view
that human values will persist
no matter what we do.
Annihilate the pessimist
whose ineffectual cry
is that the goal’s already missed
however hard we try.
- Piet Hein.
English
Mathieu Van Vyve
11.6K posts

@MathieuVVyve
Prof of Operations Research at LSM (UCLouvain) and philosopher. Avid runner, sailor, climber... anything outdoors. The ecological catastrophe breaks my heart.


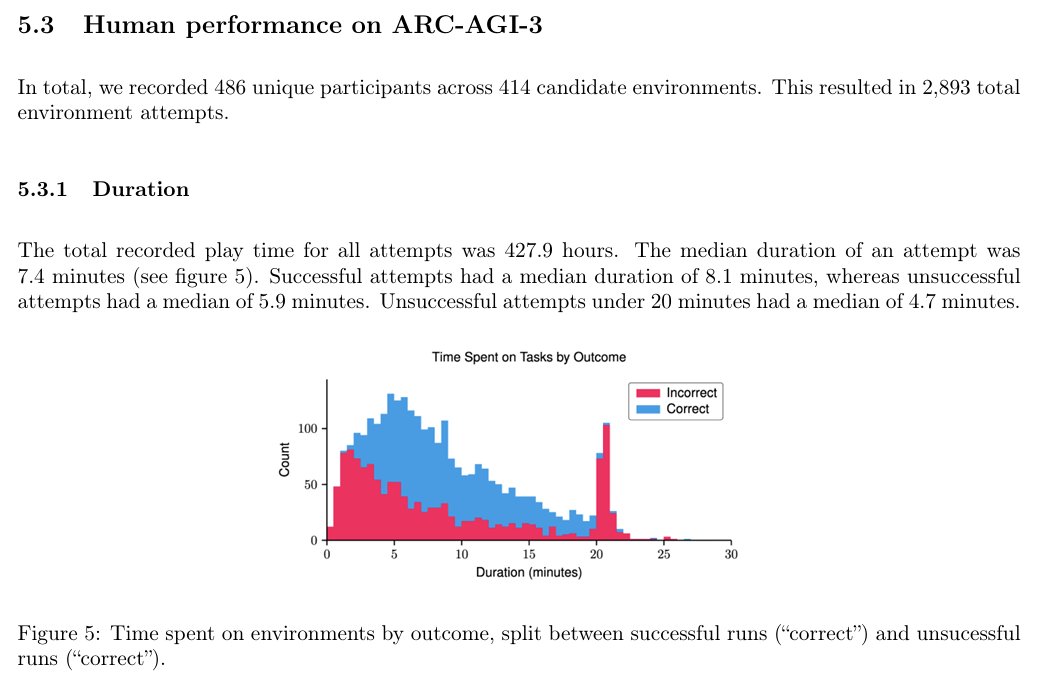
ARC-AGI-3 scores for GPT-5.4, Gemini 3.1 Pro and Opus 4.6 Gemini 3.1 Pro: 0.37% GPT-5.4: 0.26% Opus 4.6: 0.25% Grok 4.2: 0%




Today we're launching ARC-AGI-3 135 Novel Environments (nearly 1K levels) we build by hand It is the only unsaturated agent benchmark in the world Each game is 100% human solvable, AI scores <1% This gap between human and AI performance proves we do not have AGI Agents today need human handholding. Agents that beat V3 will prove they don’t need that level of supervision. Agents that beat V3 will demonstrate: * Continual learning - Each level builds on top of each other. You can’t beat level 3 without carrying forward what you learned in levels 1 and 2. * World modeling - Many of the environments require planning actions many actions ahead. AI will have no choice but to build an internal world model for how the environment works, run simulations “in its head” and proceed with an action In our early testing, we’ve seen a few clear failure modes of AI: * Anticipation of future events - If an environment requires that AI set up a scene, and then carry out a scenario (like in sp80), it starts to break down. * Anchoring on early hypothesis - Early in a game it comes up with a hypothesis (even if wrong) and refuses to update its beliefs later. * Thinking it’s playing another game - AI thinks it’s playing chess, pacman. The training data holds hard! One major problem is there is too much data to carry forward in a single context. Models must learn what to remember and what to forget The agent that beats ARC-AGI-3 will have demonstrated the most authoritative evidence of progress towards general intelligence to date We're excited to get this out and excited to see what you think


notice how they also gave higher weight to later levels? the benchmark was designed to detect the continual learning breakthrough when it happens in a year or so they will say "LOOK OUR BENCHMARK SHOWED THAT. WE WERE THE ONLY ONES"

i don't think arc-agi-3 will last very long environments are fun tho

this is pretty much worst case performance no harness at all and very simplistic prompt


The striking thing in this Fox News clip featuring former Assistant FBI Director Chris Swecker is not the speculation around the general. It is how casually the conversation moves through recovered UFOs, reverse engineering, and an arms race as if all three are already settled.



BREAKING: NVIDIA CEO announces “we’ve achieved AGI”