Sabitlenmiş Tweet

Parallelised Q-Networks go continuous! 🚀
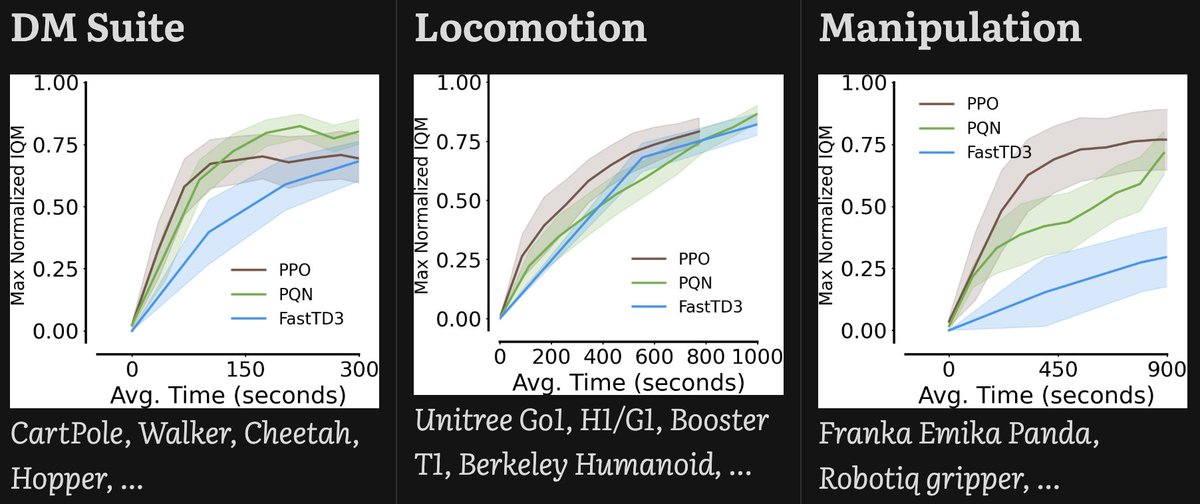
We’re excited to introduce PQN extended to continuous-action control — no replay buffers, no target networks, just pure online Q-learning + a deterministic actor.
Now you can use PQN + MuJoCo Playground to train full robotic policies in just seconds or minutes 🤖 All running entirely on GPU
👉 Blog post: mttga.github.io/posts/pqn_cont…
👾 Codebase: github.com/mttga/purejaxq…
1/5
English