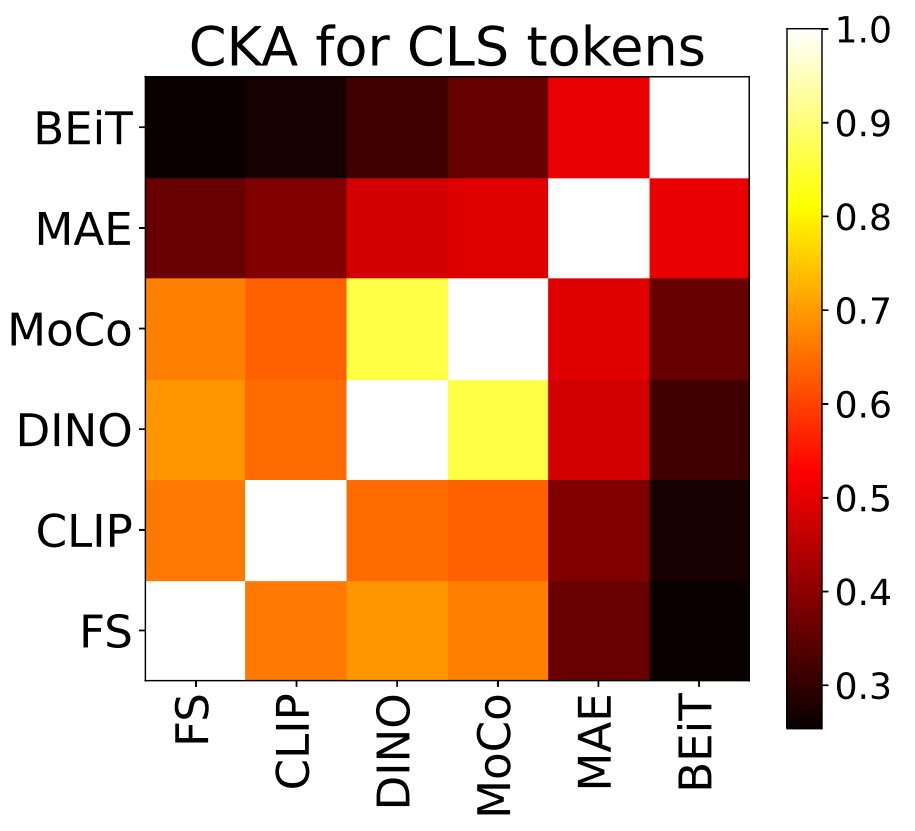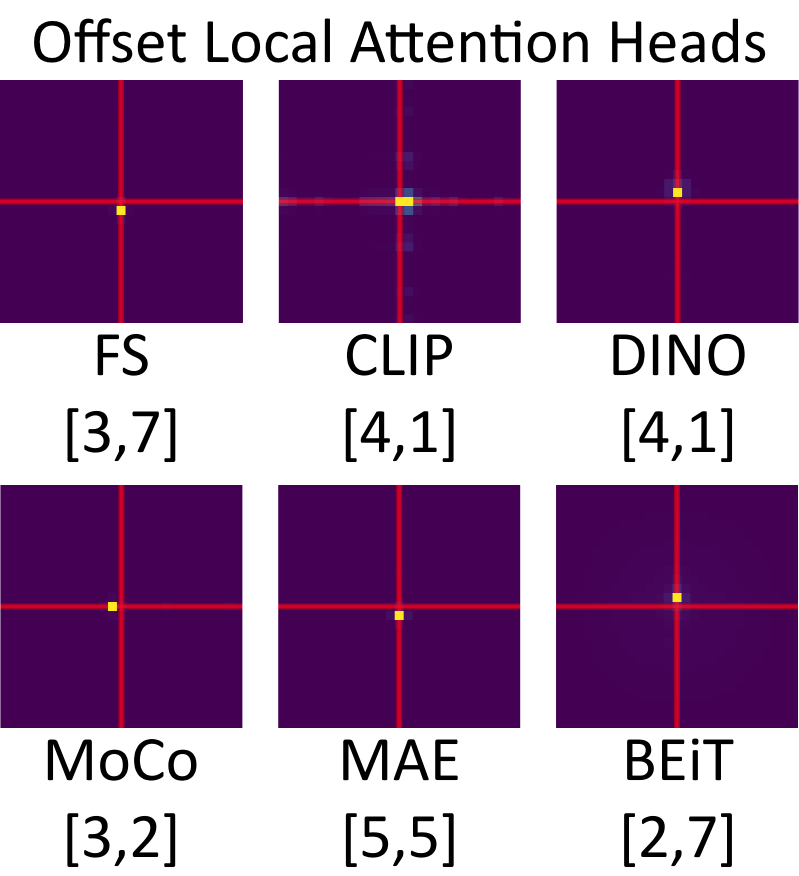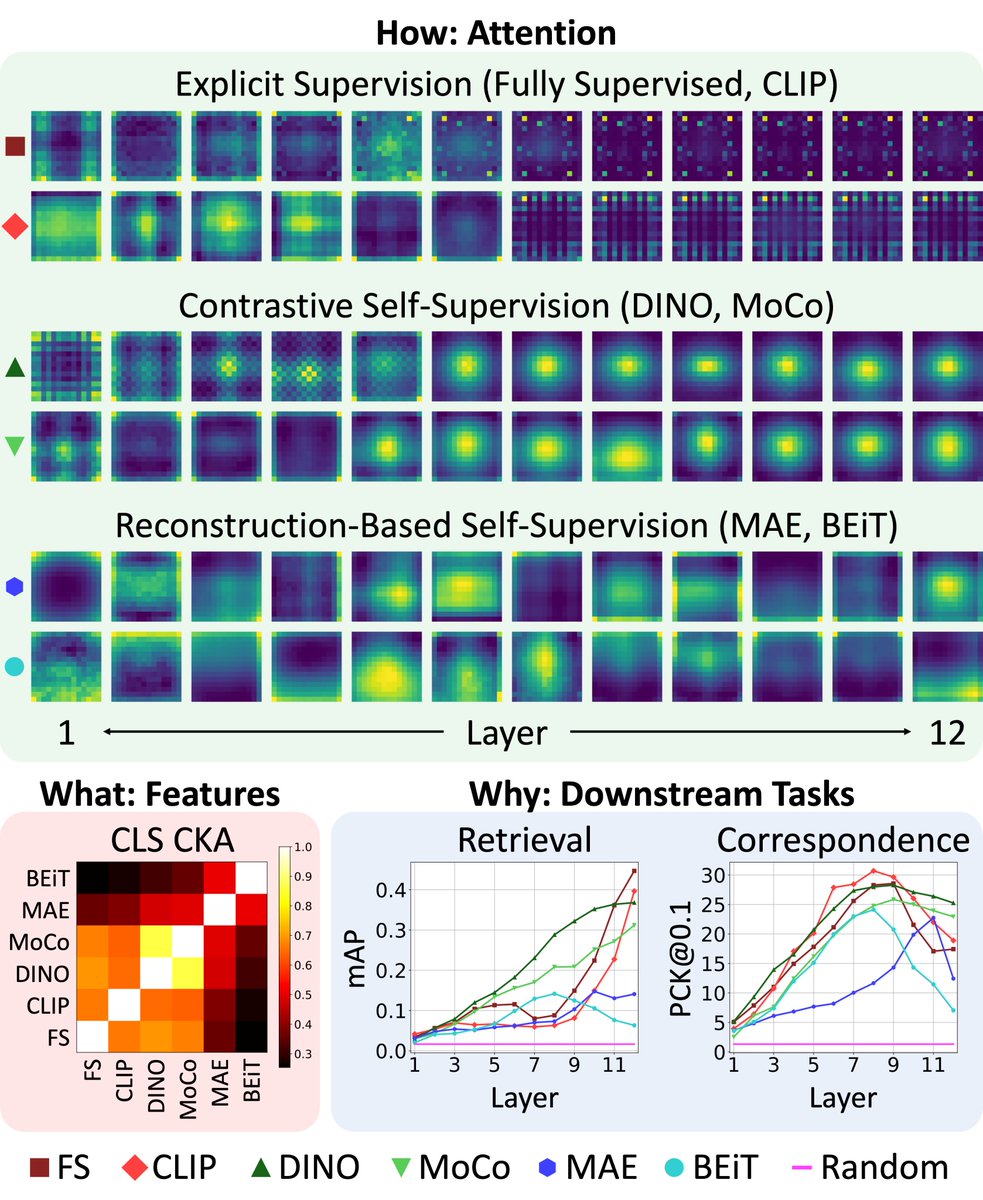

Matthew Walmer retweetledi

Diffusion models be like:
“this image is 97% noise… better process all 256×256 pixels anyway”
If very noisy diffusion states contain no more useful information than a tiny downsampled image,
Then why run expensive full-res computation on them?
🧵

English